基于文章摘要句子的数据扩充方法以及PICOS抽取分类方法与流程
基于文章摘要句子的数据扩充方法以及picos抽取分类方法
技术领域
1.本发明属于循证医学中picos抽取分类技术领域,特别涉及一种基于文章摘要句子的数据扩充方法以及picos抽取分类方法。
背景技术:
2.目前大部分的医学文献都是按照picos的思路和原则来编写文献。针对医学文章摘要picos分类任务,可考虑应用人工智能中深度学习解决大规模文本分类问题,通过预训练-微调-下游任务的方式去实现文本分类,去掉繁杂的人工特征工程,端到端的解决问题。
3.然而,在做文章摘要句子分类时,存在数据量少的问题,需要对文章摘要句子进行标注,然而目前人工标注方式困难且繁杂,需要专业的医学工作者通读摘要后才能进行标注。
技术实现要素:
4.本发明的目的之一在于提出一种基于文章摘要句子的数据扩充方法,通过自动数据扩充的方式,以解决目前数据标注困难、数据量少的技术问题。
5.本发明为了实现上述目的,采用如下技术方案:
6.一种基于文章摘要句子的数据扩充方法,包括如下步骤:
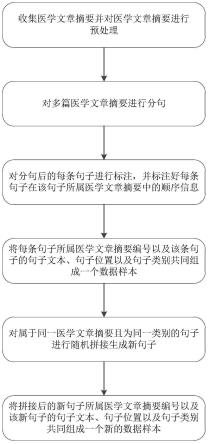
7.步骤1.数据样本构建;
8.首先对多篇医学文章摘要进行分句,然后对分句后的每条句子进行类别标注,并标注好每条句子在该句子所属医学文章摘要中的句子位置即顺序信息;
9.将每条句子所属医学文章摘要编号以及该条句子的句子文本、句子位置以及句子类别共同组成一个数据样本;
10.步骤2.数据样本扩充;
11.对属于同一医学文章摘要且为同一类别的句子进行随机拼接生成新句子;
12.其中,拼接后的新句子的句子位置采用拼接前首条句子的句子位置信息,拼接后的新句子的句子类别与拼接前各条句子的句子类别均相同,拼接后的新句子所属医学文章摘要编号与拼接前各条句子所属医学文章摘要编号均相同;
13.将拼接后的每条新句子所属医学文章摘要编号以及该条新句子的句子文本、句子位置以及句子类别共同组成一个新的数据样本。
14.本发明的目的之二在于提出一种基于文章摘要句子的picos抽取分类方法,该方法基于上述数据扩充方法扩充的数据,以提升模型对长句子识别的准确率。
15.本发明为了实现上述目的,采用如下技术方案:
16.一种基于文章摘要句子的picos抽取分类方法,包括如下步骤:
17.步骤1.搭建picos抽取分类模型;
18.搭建的picos抽取分类模型包括预训练模型、拼接模块以及分类模块;
19.其中,数据样本在picos抽取分类模型中的处理过程如下:
20.将数据样本中的句子文本通过预训练模型进行文本嵌入,得到句子向量;将数据样本中的句子位置通过预训练模型进行文本嵌入,得到句子顺序信息向量;
21.将数据样本的句子向量和句子顺序信息向量送入拼接模块,通过拼接得到新的句子向量信息,然后将新的句子向量信息送入分类模块,输出句子类别;
22.步骤2.训练picos抽取分类模型;
23.利用训练数据集中的训练数据训练picos抽取分类模型;其中,该训练数据集中的训练数据来源于上述数据扩充方法得到的数据样本;
24.通过最小化分类模块的损失值得到picos抽取分类模型的模型参数,完成模型训练;
25.步骤3.对医学文章摘要信息进行picos抽取分类;
26.利用训练好的picos抽取分类模型待分类的对医学文章摘要信息进行picos抽取分类。
27.此外,本发明还提出了一种与上述基于文章摘要句子的picos抽取分类方法相对应的计算机设备,该计算机设备包括存储器和一个或多个处理器。
28.所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,用于实现上述基于文章摘要句子的picos抽取分类方法的步骤。
29.此外,本发明还提出了一种与上述基于文章摘要句子的picos抽取分类方法相对应的计算机可读存储介质,其上存储有程序。
30.该程序被处理器执行时,用于实现上述基于文章摘要句子的picos抽取分类方法的步骤。
31.本发明具有如下优点:
32.如上所述,本发明述及了一种基于文章摘要句子的数据扩充方法,该方法针对于同一医学文章摘要且同一类别的句子采用随机拼接的方法去进行自动数据扩充,很好地解决了目前人工数据标注困难、数据量少的技术问题。此外,本发明还提出了一种基于文章摘要句子的picos抽取分类方法,该方法中搭建了picos抽取分类模型,其中,模型的训练数据来源于上述数据扩充方法得到的数据样本,通过数据扩充以及在训练过程中加入句子位置信息的方式,可明显提升模型对长句子识别的准确率,同时模型收获了额外的与输入相关的知识。
附图说明
33.图1为本发明实施例中基于文章摘要句子的数据扩充方法的流程图。
34.图2为本发明实施例中基于文章摘要句子的picos抽取分类方法的流程图。
具体实施方式
35.名词解释:
36.picos:在循证医学中,任何一个研究都是由患者、干预、比较、结果和试验设计组成的,即picos原则。picos原则有5个元素组成:
37.p(population)研究对象:需要研究的对象人群或代表与研究对象相关的问题。
38.i(intervention)干预措施:对研究人群采用的治疗干预措施或与观察指标。
39.c(comparison)比较组:代表对照组和将给予治疗措施或观察的指标。
40.o(outcome)结局:代表与结局指标和相关的问题。
41.s(study design)研究类型:即研究设计是什么,队列研究、病例对照还是横断面。
42.pmid:pubmed唯一标识码,是pubmed搜索引擎中收录的生命科学和医学等领域的文献编号,在本发明中pmid用来判断哪些句子属于同一篇医学文章摘要中。
43.pandas:是基于numpy的一种工具,该工具是为解决数据分析任务而创建的。
44.下面结合附图以及具体实施方式对本发明作进一步详细说明:
45.如图1所示,本实施例述及了一种基于文章摘要句子的数据扩充方法,其包括如下步骤:
46.步骤1.数据样本构建。
47.在进行数据样本构建之前,需要先进行数据获取以及预处理。
48.本实施例中收集多篇医学文章摘要,例如500-1000篇医学文章摘要,这些医学文章摘要数据来源于开源的文献资源网站,例如知网、pubmed等等。
49.数据获取之后,需要对医学文章摘要进行数据清洗,其中,数据清洗的操作主要包括将有编码问题或者摘要只有一句话的医学文章摘要剔除掉。
50.然后对获取的医学文章摘要按照标点符号(如句号、问号和感叹号)进行分句操作。
51.对分句后的每条句子进行类别标注,句子类别有六类,分别是p、i、c、o、s和其他六类。同时标注好每条句子在该句子所属医学文章摘要中的句子位置即顺序信息。
52.将每条句子所属医学文章摘要编号(例如pmid)以及该条句子的句子文本、句子位置以及句子类别共同组成一个数据样本。
53.将所有数据样本存储到excel文件中,存储格式如下述表1所示。
54.表1
[0055][0056][0057]
其中,表1中句子位置表示该句子在所属医学文章摘要信息中的顺序信息。
[0058]
步骤2.数据样本扩充。
[0059]
对属于同一医学文章摘要且为同一类别的句子进行随机拼接生成新句子。
[0060]
其中,拼接后的新句子的句子位置采用拼接前首条句子的句子位置信息,拼接后
的新句子的句子类别与拼接前各条句子的句子类别均相同。
[0061]
首条句子是指两个及以上待拼接的句子中,位置最靠前的一个句子。
[0062]
将拼接后的每条新句子所属医学文章摘要编号(例如pmid)以及该条新句子的句子文本、句子位置以及句子类别共同组成一个新的数据样本。
[0063]
本实施例中数据样本扩充采用自动数据扩充的方式。
[0064]
具体的,本实施例通过pandas工具处理excel文件实现自动化数据扩充。
[0065]
数据自动扩充的过程为:首先使用pandas.groupby从数据样本中筛选出属于同一医学文章摘要且为同一类别的各条句子,然后将筛选出的各条句子均放入列表中。
[0066]
遍历列表对属于同一医学文章摘要且为同一类别的各条句子进行随机拼接生成新句子。
[0067]
例如:一篇医学文章摘要中有句子{s1、s2、s3、s4、s5},如下述表2所示。
[0068]
其中,句子s1、s2、s4为同一类别。
[0069]
通过拼接生成新句子s6=s1+s2,s7=s1+s4,s8=s2+s4。
[0070]
拼接后的新句子s6、s7、s8顺序信息采用拼接前首条句子的位置信息。以新句子s6为例,在拼接之前,s1的位置最靠前,因此新句子s6的句子位置信息与s1一致。
[0071]
拼接后的新句子的类别,与拼接前的句子的类别一致。
[0072]
表2
[0073][0074][0075]
本发明通过上述数据扩充方法,解决了目前人工数据标注困难、数据量少的技术问题。
[0076]
此外,本发明实施例中还提出了一种基于文章摘要句子的picos抽取分类方法,如图2所示。该picos抽取分类方法包括如下步骤:
[0077]
步骤1.搭建picos抽取分类模型。
[0078]
搭建的picos抽取分类模型包括预训练模型、拼接模块以及分类模块。其中,预训练模型、拼接模块以及分类模块依次相连。
[0079]
预训练模型的输入为数据样本中的句子文本和句子位置。
[0080]
分类模块的预测输出为句子类别。
[0081]
本实施例中预训练模型采用bert预训练模型;拼接模块采用torch.cat模块;分类模块包括layernorm层、两层神经网络层以及一层softmax分类层。
[0082]
数据样本在picos抽取分类模型中的处理过程如下:
[0083]
将数据样本中的句子文本通过bert预训练模型进行文本嵌入,将bert预训练模型最后一层hiddenlayer状态,作为其embedding输出,得到句子向量。
[0084]
同理,将数据样本中的句子位置通过预训练模型进行文本嵌入,得到句子顺序信息向量。
[0085]
将数据样本的句子向量和句子顺序信息向量送入torch.cat拼接模块,通过torch.cat拼接模块将两个向量拼接后,得到新的句子向量信息。
[0086]
由于picos原则的特殊性,本发明对医学文章摘要进行句子picos抽取分类的过程中,加入句子的顺序信息来利用picos的原则去进行模型训练,能够明显提升模型的准确率。
[0087]
将新的句子向量信息送入分类模块,输出句子类别,具体过程如下:
[0088]
新的句子向量信息首先进入layernorm层,再进入两层神经网络结构(激活函数使用relu,dropout值为0.3),最后经过softmax得到句子的类别,分类模块采用交叉熵损失函数。
[0089]
步骤2.训练picos抽取分类模型。
[0090]
利用训练数据集中的训练数据训练picos抽取分类模型;该训练数据集中的训练数据来源于上面基于文章摘要句子的数据扩充方法得到的数据样本。
[0091]
与上述数据样本不同之处在于,训练数据中不包含医学文章摘要编号(例如pmid)。
[0092]
一篇文章中同一类别的句子描述的信息也是最为相似的,本发明通过此种方式扩充数据,会明显提升模型对长句子识别的准确率,同时模型会收获额外的与输入相关的知识。
[0093]
通过最小化分类模块的损失值得到picos抽取分类模型的模型参数,完成模型训练。
[0094]
步骤3.对医学文章摘要信息进行picos抽取分类。
[0095]
利用训练好的picos抽取分类模型待分类的对医学文章摘要信息进行picos抽取分类。
[0096]
本发明在picos抽取分类模型训练过程中,通过加入句子的位置顺序信息,并且基于上述数据扩充的方法得到的数据样本,大幅度提升了模型的picos抽取分类准确率。
[0097]
此外,本发明实施例中还提出了一种用于实现上述基于文章摘要句子的picos抽取分类方法的计算机设备。该计算机设备包括存储器和一个或多个处理器。
[0098]
其中,在存储器中存储有可执行代码,当处理器执行可执行代码时,用于实现上述基于文章摘要句子的picos抽取分类方法的步骤。
[0099]
本实施例中计算机设备为任意具备数据数据处理能力的设备或装置,此处不再赘述。
[0100]
此外,本发明实施例还提供一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,用于实现上述基于文章摘要句子的picos抽取分类方法的步骤。
[0101]
该计算机可读存储介质可以是任意具备数据处理能力的设备或装置的内部存储单元,例如硬盘或内存,也可以是任意具备数据处理能力的设备的外部存储设备,例如设备上配备的插接式硬盘、智能存储卡(smart media card,smc)、sd卡、闪存卡(flash card)等。
[0102]
当然,以上说明仅仅为本发明的较佳实施例,本发明并不限于列举上述实施例,应当说明的是,任何熟悉本领域的技术人员在本说明书的教导下,所做出的所有等同替代、明显变形形式,均落在本说明书的实质范围之内,理应受到本发明的保护。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1