面向大规模差分算子的资源并行调度与优化方法及系统
1.本发明属于计算机学科并行计算、中间件及资源调度技术领域,涉及一种面向大规模差分算子的资源并行调度与优化方法及系统,具体涉及一种集群环境下多粒度并行计算与自动并行化和资源调度的中间件相结合的面向大规模差分算子的资源并行调度与优化方法及系统。
背景技术:
2.差分算子是一种算子,对任一实函数f(x),若记δf(x)=f(x+1)-f(x),则称δ为向前差分算子,简称差分算子。差分是计算数学的基本概念之一,指离散函数在离散节点上的改变量。差分算子在数值积分、数值微分和微分方程的数值解中是很有用的。
3.资源调度是将工作分配给完成工作的资源的方法。工作可能是虚拟计算元素,例如线程、进程或数据流,这些元素又被调度到硬件资源(例如处理器、网络链接或扩展卡)上。如何合理的分配计算资源来提高计算速率是本研究的主要内容。
4.异构计算主要指不同类型的指令集和体系架构的计算单元组成的系统的计算方式。使用不同的类型指令集、不同的体系架构的计算单元,组成一个混合的系统,执行计算的特殊方式,就叫做“异构计算”。
5.中间件是介于应用系统和系统软件之间的一类软件,它使用系统软件所提供的基础功能,衔接网络上应用系统的各个部分或不同的应用,能够达到资源共享、功能共享的目的。
技术实现要素:
6.本发明的目的在于提供一种集群环境下多粒度并行计算与自动并行化和资源调度的中间件相结合的面向大规模差分算子的资源并行调度与优化方法及系统,实现资源的最优调度。
7.本发明的方法所采用的技术方案是:一种面向大规模差分算子的资源并行调度与优化方法,包括以下步骤:
8.步骤1:提取差分算子,分析其中共同的部分,取其共性表达,将不同之处抽取出来作为参数,将得到的差分算子转换成多线程c代码和cuda下的代码;
9.步骤2:获取需求任务,即差分算子需要重复计算的次数n;将需求任务发送至集群;
10.步骤3:将总需求任务进行划分,将需求任务合理地分配给集群中任务执行单元的cpu和gpu进行计算,将计算结果存储。
11.本发明系统所采用的技术方案是:一种面向大规模差分算子的资源并行调度与优化系统,包括以下模块:
12.模块1,用于提取差分算子,分析其中共同的部分,取其共性表达,将不同之处抽取出来作为参数,将得到的差分算子转换成多线程c代码和cuda下的代码;
13.模块2,用于获取需求任务,即差分算子需要重复计算的次数n;将需求任务发送至集群;
14.模块3,用于将总需求任务进行划分,将需求任务合理地分配给集群中任务执行单元的cpu和gpu进行计算,将计算结果存储。
15.步骤3中,通过分布式框架来将总需求任务进行划分,将总的任务数n作为输入,通过一个消息中间件联系;所述消息中间件将总任务数n分别分配给各个任务执行单元,并监视每个任务执行单元的运行情况;当任务执行单元的运算结束后将结果存储。
16.本发明的资源调度、任务分配使用了分片的思想。
17.本发明提取其算子的核心思想是将具有共同性质或结构的算子进行整合,将不同的部分作为可更改的参数进行传递等。
18.本发明的资源调度部分,其核心技术是中间件技术。资源调度中间件和分布式框架中所使用的消息中间件。
19.本发明的尽量使cpu和gpu计算时间相同,这样才能使计算总时间最短。
20.本发明以分布式计算、计算机系统与结构和分片技术为指导思想,使用分布式框架将任务执行单元与主机相连,组成集群,并在集群的环境下使用中间件,具有自动并行化翻译和资源调度的功能。针对大规模算子,分析算子结构,寻找共性,将其不同之处提取出来作为参数传递,并翻译出其并行化代码。
21.本发明不仅可以实现算子在集群上的高效计算,而且可以对其他串行程序转换为并行程序的课题起到帮助作用。灵活变动后,除了可以使待处理的任务在集群上运行,若任务量较小,也可以在单独的主机上实现cpu\gpu的协同计算。
附图说明
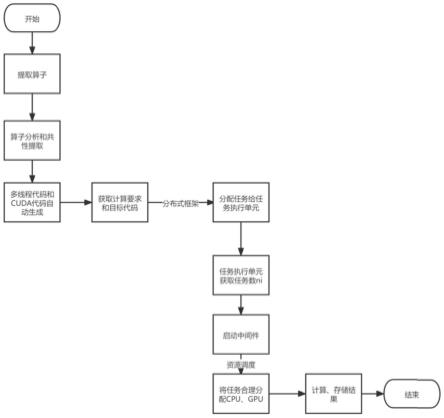
22.图1为本发明实施例的流程图。
23.图2为本发明实施例的消息中间件工作原理图。
24.图3为本发明实施例的分布式框架实现需求任务划分工作原理图;
25.图4为本发明实施例的分片思想工作原理图;
26.图5为本发明实施例的资源调度模型图。
具体实施方式
27.为了便于本领域普通技术人员理解和实施本发明,下面结合附图及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
28.本发明是适用于集群下计算差分算子的情形。首先获得算子的多线程c代码和cuda下的代码。然后将代码中的算子进行分析,对一系列算子进行共性抽取,将代码简化,其中算子共性的提取是本发明的主要内容。将算子代码整合后获得目标代码,然后根据具体需求将目标代码与计算次数在中间件中进行资源调度,将任务合理分配,通过使cpu\gpu的协同计算更快地得到计算结果。
29.请见图1,本发明提供的一种面向大规模差分算子的资源并行调度与优化方法,第一部分是准备工作。提取算子,将得到的算子转换成多线程c代码和cuda下的代码。第二部
分,将一系列算子汇总,分析其中共同的部分,取其共性表达,将不同之处抽取出来作为参数,然后封装到函数里。当算子部分处理完毕以后,获取需求,即算子需要重复计算的次数n。将任务送给集群系统。然后通过分布式框架来将总任务进行划分,合理的分配给每个任务执行单元。例如,第一个任务执行单元执行数量为n1,第二个为n2,依此类推。其中n1+n2+...+ni=n。接着任务执行单元获取任务数,启动中间件对其进行资源调度,即任务分配,将任务合理地分配给任务单元的cpu和gpu。进行计算,将计算结果存储。
30.本实施例在集群的单个主机上部署资源调度的中间件,该中间件的总体结构与工作流程如图2所示。将并行化以后的算子与需要计算的次数,即一个任务执行单元的任务数作为输入,经过资源调度模模型可以将任务合理地分配给cpu和gpu,达到二者同时进行计算,减少运行时间。
31.本实施例的资源调度模型如附图5,首先对于需要计算的差分算子进行提取然后进入差分算子共性分析程序,分析差分算子的共性并进行提取,提取完成后对于查分算子进行结构化表达,之后通过代码生成程序生成对于的多线程实现代码和cuda实现代码,对传入的数据进行分片并且赋予元数据标签标记数据块在源数据的位置以便后续合并,对于新的数据的传入我们首先在数据库中判断要调用的worker是否存在已经配置好的相关参数(上文提到的cpu的块数,gpu的块数和cpu上创建的线程数),如果不存在相关参数就发送任务,让worker调用插桩程序进行拟合,并且得出相关的结果(插桩程序得到的信息分析拟合后的就够)中获得这些参数(同上相关参数)。然后根据这些参数同数据一起发送到任务队列等待从机拉取任务运行。本模型的创新点在于使用数学模型事先对于cpu数,gpu数和线程数进行预分配,达到程序高效的同时使用cpu和gpu的目的。
32.将任务执行单元与主机联系起来形成集群则需要一个分布式的框架。本实施例提供的框架形式如图3所示。将总的任务数n作为输入,通过一个消息中间件联系。该中间件将总任务数n分别分配给各个任务执行单元,并监视每个任务执行单元的运行情况。当任务执行单元的运算结束后将结果存储到后端。
33.请见图4,本发明的资源调度、任务分配使用了分片的思想。
34.以下通过使用的海洋模式下由一个偏微分方程推导出的12种基本差分算子运算为例对本发明做进一步的阐述。
35.该系列算子来自于黄小猛等人于2019年发表的论文(xiaomeng huang,xing huang,dong wang,qi wu,yi li,shixun zhang,yuwenchen,mingqingwang,yuan gao,qiang tang,yue chen,zheng fang,zhenyasong,andguangwenyang:openarray v1.0:a simple operator library for the decoupling of ocean modeling and parallel computing.geosci.model dev.,12,4729
–
4749,2019)。表1是12种基本差分算子的详细内容。
36.表1
37.序号算子名称离散形式1axf[var(i,j,k)+var(i+1,j,k)]/22axb[var(i,j,k)+var(i-1,j,k)]/23ayf[var(i,j,k)+var(i,j+1,k)]/24ayb[var(i,j,k)+var(i,j-1,k)]/2
5azf[var(i,j,k)+var(i,j,k+1)]/26azb[var(i,j,k)+var(i,j,k-1)]/27dxf[var(i+1,j,k)-var(i,j,k)]/dx(i,j)8dxb[var(i,j,k)-var(i-1,j,k)]/dx(i-1,j)9dyf[var(i,j+1,k)-var(i,j,k)]/dy(i,j)10dyb[var(i,j,k)-var(i,j-1,k)]/dy(i,j-1)11dzf[var(i,j,k+1)-var(i,j,k)]/dz(k)12dzb[var(i,j,k)-var(i,j,k-1)]/dz(k-1)
[0038]
使用动态代码生成技术,可以得到与算子对应的代码。例如,
[0039]
(list_0[calc_id2(i,j,k,s0_0,s0_1)]+list_0[calc_id2(-1+i,j,k,s0_0,s0_1)])/2表示算子2,为方便后续说明,本实施例使用另一种形式进行表示,即
[0040]
0.5*(list_0[calc_id2(i,j,k,s0_0,s0_1)]+list_0[calc_id2(-1+i,j,k,s0_0,s0_1)]);
[0041]
(list_1[calc_id2(i,j,k,s1_0,s1_1)]+list_1[calc_id2(-1+i,j,k,s1_0,s1_1)])表示算子8。
[0042]
经过观察可以将算子简化成如下形式:f*(a
±
b)。f是系数,a是左项数组,b是右项数组。
±
是a与b之间的操作符,根据不同算子的具体情况选择+或者-。在公式中,f是系数,在表1的前六个算子中取值为0.5;后六项取值为1.0。a和b均为三维数组[i,j,k]的形式,由于算子不同,其中所做的运算也相应改变。如在axb中左项并未进行运算,而右项进行了i-1。规定数组为[0,0,0]时只传入原始数据而不进行运算,若需要进行运算则把i,j,k对应的位置进行更改。其中1代表+1运算,-1代表-1运算。例如当右项为[0,1,0]时代表在右侧的三元组变成[i,j+1,k]。右项与左项操作原理相同。对于两项之间的操作符,经分析可知,表一中前六项对应操作符为+,后六项对应-。因此可将操作符定义为一个参数op,1对应+运算,-1对应-运算。将f,a,b和op作为参数在程序之中传递,通过改变参数来改变需做运算的目的算子。
[0043]
将整合后的算子代码改写为可在集群上运行的多线程c代码与cuda代码,得到所需的目标代码。得到代码以后需要获得要求的运算次数n。将n传入集群,通过消息中间件将任务合理的分配给不同的任务执行单元。
[0044]
在任务执行单元中启动资源调度中间件,中间件将任务执行单元需处理的任务分配给该单元中的cpu和gpu。cpu上的线程数遵循资源调度模型计算的任务分配方案,受到cpu内核数、数据块数以及g基于gpu执行的块计算加速率等条件的限制。
[0045]
本实施例提供了一个简化的映射示例,具体包括以下步骤:
[0046]
(1)利用#program parallel标记分析后可并行化的代码块。
[0047]
(2)根据在分析阶段确定的线程数量在cpu上创建线程,创建比确定的线程数量多一个,用来控制gpu对于任务的运行。
[0048]
(4)cpu线程并行执行分配的任务。
[0049]
(4.1)在cpu线程的控制下,cuda内核对于任务进行并行计算。
[0050]
(4.2)明确了需要在gpu上进行的任务以后,分配gpu内核,给对应的循环分配线程。
[0051]
(4.3)确定grid和block的维度和大小,grid和block影响cuda的执行效率。
[0052]
(4.4)通过资源调度模型进行粗粒度的集群间调度。
[0053]
(5)完成计算任务,对任务数据进行合并。
[0054]
在资源调度模块中,按照cpu和gpu同时完成任务的情况下计算的总时间最短这一原则来分配任务。
[0055]
任务分配好后直接计算,计算完成后,每个任务执行单元将会把结果存储在分布式框架的后端,结果与运行时间将会在界面上显示出来。
[0056]
应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1