障碍物感知方法、装置、整车控制器及可读存储介质与流程
本发明涉及目标检测,特别涉及一种障碍物感知方法、装置、整车控制器及可读存储介质。
背景技术:
1、随着科技的不断发展,越来越多的车辆开始装配有自动驾驶、辅助驾驶、碰撞预警等智能功能。为了实现上述智能功能,需要对车辆周围的障碍物进行空间感知,以获取障碍物的位置、姿态等信息。
2、相关技术中,为了实现确定障碍物的空间感知结果,通常需要在车辆上装备激光雷达,通过激光雷达实时获取车辆周围空间的点云图,并根据点云图建立周围空间的三维模型,再对三维模型中的障碍物进行识别,以对三维模型中障碍物的信息进行分析,得到障碍物的空间感知结果。
3、在上述方案中,需要使用激光雷达,但激光雷达的装配成本较为高昂,且维护成本同样较高,导致目前获取车辆周围障碍物的空间感知结果的成本较高。
技术实现思路
1、有鉴于此,本发明旨在提出一种障碍物感知方法、装置、整车控制器及可读存储介质,以解决现有技术中获取车辆周围障碍物的空间感知结果的成本较高的问题。
2、为达到上述目的,本发明的技术方案是这样实现的:
3、第一方面,本发明提供了一种障碍物感知方法,所述方法包括:
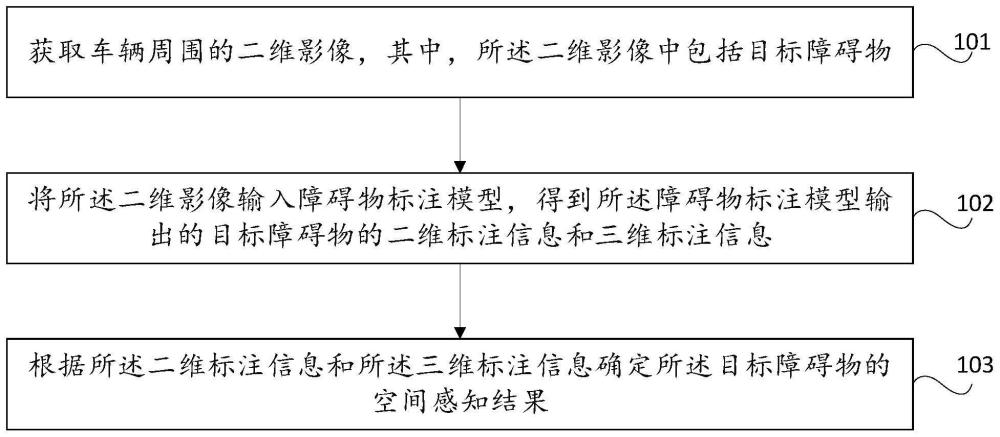
4、获取车辆周围的二维影像,其中,所述二维影像中包括目标障碍物;
5、将所述二维影像输入障碍物标注模型,得到所述障碍物标注模型输出的目标障碍物的二维标注信息和三维标注信息;
6、根据所述二维标注信息和所述三维标注信息确定所述目标障碍物的空间感知结果。
7、可选地,所述获取车辆周围的二维影像,包括:
8、通过多个视觉摄像头采集车辆周围的多张图像,其中,所述多个视觉摄像头的取景角度不同;
9、对所述多张图像进行全景拼接,得到车辆周围的二维影像。
10、可选地,所述目标障碍物的二维标注信息包括障碍物特征线和障碍物接地线,所述目标障碍物的三维标注信息包括所述目标障碍物的第一姿态。
11、可选地,所述目标障碍物的空间感知结果包括所述目标障碍物的目标姿态,所述根据所述二维标注信息和所述三维标注信息确定所述目标障碍物的空间感知结果,包括:
12、根据所述障碍物特征线和所述障碍物接地线确定所述目标障碍物的第二姿态;
13、根据所述第一姿态和所述第二姿态确定所述目标障碍物的目标姿态。
14、可选地,所述根据所述二维标注信息和所述三维标注信息确定所述目标障碍物的空间感知结果,包括:
15、获取所述目标障碍物的分类结果;
16、从融合规则集合中确定所述分类结果对应的目标融合规则,基于所述目标融合规则对所述二维标注信息和所述三维标注信息进行融合,得到所述目标障碍物的空间感知结果。
17、可选地,所述获取所述目标障碍物的分类结果,包括:
18、获取所述障碍物标注模型针对所述目标障碍物输出的分类结果,其中,所述分类结果包括车辆类型和非车辆类型。
19、可选地,所述方法还包括:
20、获取样本二维影像,对所述样本二维影像中的样本障碍物进行信息标注,得到所述样本障碍物对应的样本二维标注信息和样本三维标注信息;
21、基于所述样本二维影像、所述样本二维标注信息和所述样本三维标注信息构建模型训练数据集;
22、采用所述模型训练数据集对初始神经网络模型进行训练,得到所述障碍物标注模型。
23、可选地,所述初始神经网络模型包括第一检测头和第二检测头,所述采用所述模型训练数据集对初始神经网络模型进行训练,得到所述障碍物标注模型,包括:
24、将所述样本二维影像输入所述初始神经网络模型,得到所述第一检测头输出的训练二维标注信息,以及所述第二检测头输出的训练三维标注信息;
25、基于所述训练二维标注信息和所述样本二维标注信息确定第一损失,并基于所述训练三维标注信息和所述样本三维标注信息确定第二损失;
26、基于所述第一损失和所述第二损失调整所述初始神经网络模型的参数,得到所述障碍物标注模型。
27、第二方面,本发明提供了一种障碍物感知装置,所述装置包括:
28、获取模块,用于获取车辆周围的二维影像,其中,所述二维影像中包括目标障碍物;
29、标注模块,用于将所述二维影像输入障碍物标注模型,得到所述障碍物标注模型输出的目标障碍物的二维标注信息和三维标注信息;
30、融合模块,用于根据所述二维标注信息和所述三维标注信息确定所述目标障碍物的空间感知结果。
31、可选地,所述获取模块包括:
32、采集子模块,用于通过多个视觉摄像头采集车辆周围的多张图像,其中,所述多个视觉摄像头的取景角度不同;
33、拼接子模块,用于对所述多张图像进行全景拼接,得到车辆周围的二维影像。
34、可选地,所述目标障碍物的二维标注信息包括障碍物特征线和障碍物接地线,所述目标障碍物的三维标注信息包括所述目标障碍物的第一姿态。
35、可选地,所述目标障碍物的空间感知结果包括所述目标障碍物的目标姿态,所述融合模块包括:
36、姿态确定子模块,用于根据所述障碍物特征线和所述障碍物接地线确定所述目标障碍物的第二姿态;
37、姿态融合子模块,用于根据所述第一姿态和所述第二姿态确定所述目标障碍物的目标姿态。
38、可选地,所述融合模块包括:
39、分类子模块,用于获取所述目标障碍物的分类结果;
40、融合子模块,用于从融合规则集合中确定所述分类结果对应的目标融合规则,基于所述目标融合规则对所述二维标注信息和所述三维标注信息进行融合,得到所述目标障碍物的空间感知结果。
41、可选地,所述分类子模块包括:
42、分类结果子模块,用于获取所述障碍物标注模型针对所述目标障碍物输出的分类结果,其中,所述分类结果包括车辆类型和非车辆类型。
43、可选地,所述装置还包括:
44、样本获取模块,用于获取样本二维影像,对所述样本二维影像中的样本障碍物进行信息标注,得到所述样本障碍物对应的样本二维标注信息和样本三维标注信息;
45、训练数据集模块,用于基于所述样本二维影像、所述样本二维标注信息和所述样本三维标注信息构建模型训练数据集;
46、训练模块,用于采用所述模型训练数据集对初始神经网络模型进行训练,得到所述障碍物标注模型。
47、可选地,所述初始神经网络模型包括第一检测头和第二检测头,所述训练模块包括:
48、训练输入子模块,用于将所述样本二维影像输入所述初始神经网络模型,得到所述第一检测头输出的训练二维标注信息,以及所述第二检测头输出的训练三维标注信息;
49、损失子模块,用于基于所述训练二维标注信息和所述样本二维标注信息确定第一损失,并基于所述训练三维标注信息和所述样本三维标注信息确定第二损失;
50、训练子模块,用于基于所述第一损失和所述第二损失调整所述初始神经网络模型的参数,得到所述障碍物标注模型。
51、第三方面,本发明提供了一种整车控制器,所述整车控制器包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述障碍物感知方法。
52、第四方面,本发明提供了一种可读存储介质,当所述可读存储介质中的指令由整车控制器的处理器执行时,使得所述整车控制器能够执行上述障碍物感知方法。
53、第五方面,本发明提供了一种车辆,包括上述整车控制器。
54、相对于现有技术,本发明所述的一种障碍物感知方法、装置、整车控制器及可读存储介质具有以下优势:
55、综上,本发明实施例提供了一种障碍物感知方法,包括:获取车辆周围的二维影像,其中,二维影像中包括目标障碍物;将二维影像输入障碍物标注模型,得到障碍物标注模型输出的目标障碍物的二维标注信息和三维标注信息;根据二维标注信息和三维标注信息确定目标障碍物的空间感知结果。本发明实施例中,可以获取车辆周围的二维影像,并仅根据二维影像对车辆周围的障碍物进行标注,得到二维标注信息和三维标注信息,再根据二维标注信息和三维标注信息融合得到障碍物较为准确的空间感知结果,不仅可以提高空间感知结果的精准性,还无需使用三维影像,无需在车辆上搭载激光雷达,降低了对障碍物进行空间感知的成本。
- 还没有人留言评论。精彩留言会获得点赞!