一种GPU加速的多数据多线程SHA-256计算实现方法与流程
本发明属于加密,具体涉及一种gpu加速的多数据多线程sha-256计算实现方法。
背景技术:
1、安全散列算法,也被称作哈希算法(secure hash algorithm,sha),能够对一个数字消息,计算生成一个对应的固定长度的字符串,该字符串被称作消息的摘要。sha算法是一种hash算法,对于hash函数,将两个不同的关键字映射到同一个值的情况被称作碰撞,任意hash算法都无法避免碰撞问题。对于内容不同的消息,由于sha算法基于消息本身进行了复杂的循环迭代计算,所以生成相同摘要的可能性非常低。这恰好满足区块链对安全性的需求,由于区块链中的每一条交易都是独一无二,不会出现两条一样的数据,所以能够通过sha算法生成的摘要来判断消息内容是否被篡改。在区块链中使用sha算法除了能够很好地保护区块数据的安全性之外,生成的摘要长度固定,使得区块头部格式整齐,便于解析。
2、在区块链中sha-256目前被用在计算区块头部的前一块的hash值和当前块的hash值。sha-256由美国国家安全局研发,由美国国家标准与技术研究院(nist)在2001年发布,目前仍然是可靠的加密算法。此外,在比特币诞生初期就出现的pow(proof-ofwork,pow)共识算法,是最早的且安全可靠的公有链共识算法。比特币系统采用这一算法来保证分布式记账的一致性。在pow算法中,系统的各个节点基于各自的计算机的算力来互相竞争共同求解一个复杂但容易验证的sha-256数学难题,最快解决该问题的节点会获得下一个区块的记账权和系统自动生成的比特币作为奖励。
3、gpu(graphics processing unit,图形处理器)起源于用户对于高质量画面的要求,通过将cpu从画面渲染中解放出来,既改善了画面质量,又释放了cpu算力。gpu核心相较cpu轻量很多,它将问题约束在大量的类型相同、可并行即相互无依赖的数据计算上,大幅减少了控制电路与缓存对芯片资源的占用,从而允许在相同的芯片资源与功率下提供远超cpu的核心数量,实现远超传统cpu的高性能并行计算能力。
4、当前,利用cpu-gpu异构架构或其它硬件平台(如fpga、asic)执行sha-256算法主要有以下实现方式:
5、cpu-gpu加速方案:崔岩对安全散列算法sha-1进行了分析与改进,最后基于cuda平台实现了sha-1算法的加速。薛子豪分析了nvidia的gpu架构的演变,基于cuda平台加速了sha-256以及新的安全散列算法sha-3系列中的keccak算法,并对数据流的处理进行了优化。葛灿基于opengl平台,在amd的gpu上实现了sha-2算法的gpu加速,设计实现并优化了sha-2口令恢复算法的gpu加速。
6、专用电路:koziel等人提出了一种硬件架构来加速后量子密码候选之一的同源密码学。dai等人[23]提出了一种基于fft的指数硬件架构用于加速rsa算法。kerckhof等人总结了在sha-3竞赛中的五名决赛选手们的基于fpga平台的精简的sha-3算法实现。虽然与通用处理器相比,特定的硬件实现在能在性能上有所提升,但它们也存在一些缺点。例如,特定硬件实现不够灵活,不同硬件之间难以兼容,且后续升级维护困难。并且像asic这样的硬件实现通常需要昂贵的制造成本,且需要专门的开发设计技巧,导致开发周期变长。
7、当前,利用cpu-gpu异构架构实现sha-256加速的方案仍存在一定不足和缺陷。葛灿移植sha-256算法到gpu上的方法仅能面向小规模数据,不具有实用性价值。薛子豪虽然使用cuda平台将sha-256算法从cpu上移植到gpu上运行,并进行了一些优化,但其对算法的并行化设计能力不足,无法对同时计算多个数据时的情况进行优化,且没有对cpu与gpu之间的任务划分与通信方法进行优化。目前的优化方案对于大规模数据处理存在缺陷。
技术实现思路
1、本发明所要解决的技术问题是针对上述现有技术的不足,提供一种gpu加速的多数据多线程sha-256计算实现方法,通过分析sha-256内部的并行特性,构建了基于gpu的多线程方法,提升了算法的运算效率,与同类型gpu性能建模模型相比,既保证了建模速度,又提升了建模精度,对gpu架构探索有着积极意义。
2、为实现上述技术目的,本发明采取的技术方案为:
3、一种gpu加速的多数据多线程sha-256计算实现方法,包括以下步骤:
4、步骤1:构建sha-256算法消息扩展的并行模型;
5、步骤2:构建sha-256算法循环迭代的并行模型;
6、步骤3:优化数据存储模型和数据流模型;
7、步骤4:基于步骤1-3构建完整cpu-gpu异构结构任务和数据流。
8、为优化上述技术方案,采取的具体措施还包括:
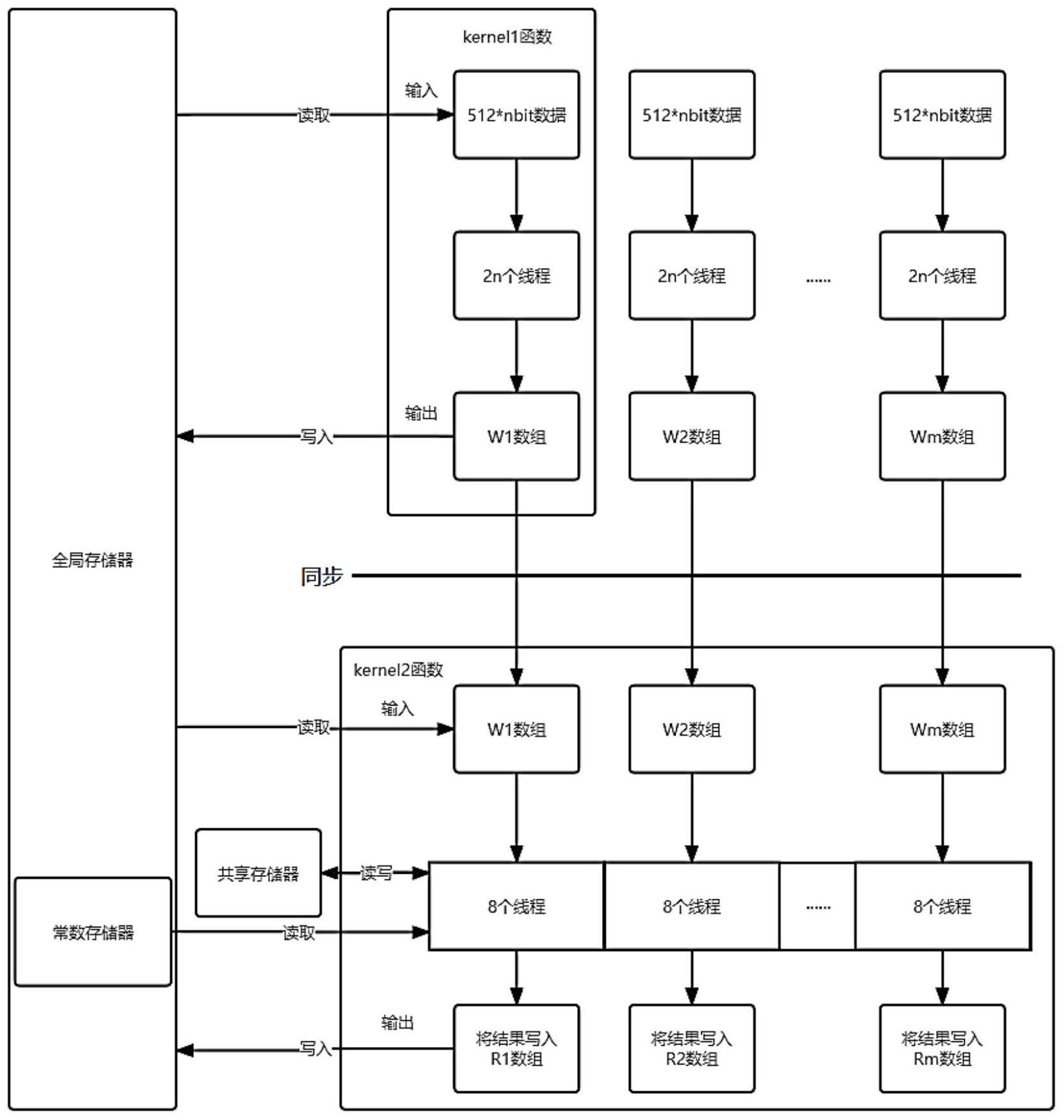
9、上述的步骤1构建的sha-256算法消息扩展的并行模型,使用gpu对整块数据采用地址偏移方法区別数据块,为不同的数据块分配不同的线程,数据块对j取值范围从16-63的w[j]数组采用双线程并行计算模式实现sha-256算法消息扩展的并行。
10、上述的步骤2构建的sha-256算法循环迭代的并行模型,利用8个线程同时处理a、b、…、h的迭代计算任务:a、b、…、h分別首先获取中间变量数组h对应位置的数值,再根据计算结果更新h,如此循环64次,完成一个数据块的迭代计算部分。
11、上述的步骤3优化的数据存储模型,将a、b、…、h存储在共享存储器中,共享存储器中的数据在计算完成后再拷贝回全局存储器,将64个常数k[i](i=0,1,2…63)存储在常数存储器,在迭代更新h数组中计算a、b、…、h时被使用。
12、上述的步骤3优化的数据流模型,使用两个不同的kernel函数分别计算消息扩展部分与之后的迭代更新h数组部分;
13、其中,在第一个kernel函数计算完成后在显存保留w数组,第二个kernel函数使用第一个kernel函数计算得出的w数组作为输入,实现中间结果复用;
14、此外,当有多个数据进行sha-256计算时,数据传输与消息扩展部分的计算异步进行。
15、上述的步骤4构建的完整cpu-gpu异构结构任务和数据流具体包括:
16、步骤4.1、cpu发起指令将内存中的常数数组k传输到显存中的常数存储器部分;
17、步骤4.2、cpu从磁盘读取数据信息,确定数据长度,分配内存与显存并创建cuda流;
18、步骤4.3、开始运行sha-256算法,记录运行的起始时间;
19、步骤4.4、gpu在数据传输完成后开始计算消息扩展部分;
20、步骤4.5、当cpu处理完所有数据的补位填充后,等待gpu计算完所有数据的消息扩展部分,之后cpu同步调用gpu来计算所有数据的循环迭代部分,并进行数据存储;
21、步骤4.6、gpu计算完成后cpu执行下一步代码,发起异步传输的请求,将结果数组从显存拷贝到主存,在数据拷贝完成后,算法执行完毕,停止计时;
22、步骤4.7、释放内存与显存,并摧毁之前创建的流,计算sha-256算法的执行时间。
23、上述的步骤4.2具体为:cpu从磁盘读取数据信息,确定数据长度,根据数据长度分配内存来存储数据,之后基于数据长度分配好需要的显存,需要分配的显存有数据部分、w数组部分和结果数组部分,此外还需要在内存里分配相应结果数组部分以提供空间存储gpu计算出的结果;最后为每个待处理的数据创建好相应的cuda流,并且同时确定需要处理的总的数据个数。
24、上述的步骤4.3所述sha-256算法,包括:cpu先对数据进行预处理,进行补位填充;之后,利用前一步中为数据已经创建好的流,将处理完的数据异步传输给gpu,gpu开始异步计算;cpu在调用gpu执行异步操作后开始处理下一个数据的补位与填充部分。
25、上述的步骤4.4具体过程为:gpu直接从显存的数据部分读取数据,计算完后存到显存的w数组部分;随着cpu不断处理完多个数据的补位填充并且完成数据传输后,会有多个流等待着gpu来处理,当硬件未达到满载时,多个数据的多个流被gpu同时计算。
26、上述的步骤4.5中,gpu通过线程id来寻找显存中对应的w数组以及结果数组的地址,之后每个线程开始执行相同代码,在过程中访问常数存储器,读取其中的k数组,并使用共享存储器存储部分中间变量。
27、本发明具有以下有益效果:
28、可以采用多线程的方法处理多个数据的sha-256摘要的计算任务,并且根据算法的过程设计了并行方案;同时,本发明利用gpu多级存储的结构,将一些常用数据存放于快速存取结构当中,加快了算法的运算速度;此外,本发明设计了cpu的同步调度方案,利用cpu-gpu异构系统不同硬件设备各自的优势实现了合理计算任务分配,降低了计算时间开销。
- 还没有人留言评论。精彩留言会获得点赞!