一种基于高层次综合工具的图像处理方法及系统与流程
1.本发明涉及图像处理技术领域,更具体地,涉及一种基于高层次综合工具的图像处理方法及系统。
背景技术:
2.目前工业实时检测对图像处理算法的处理速度和吞吐量提出了极高的要求,使得传统的cpu平台无法满足要求,需要转向硬件平台进行图像处理算法加速。在工业检测领域中,常见的图像处理算法包括gauss滤波、sobel滤波、harris角点提取、fast角点提取等。
3.传统工业视觉检测系统不能满足现代工业现场要求主要体现在检测精度低、检测速率慢、检测总量小。工业级别的高精度相机能够解决检测精度低与检测速率不够的问题,但是随之带来的是图像原始数据量大,图像传输速率快等问题。图像算法的处理速度成为工业检测系统的瓶颈。cpu平台的工业检测系统不能适应日益增大的图像原始数据量以及日益复杂的图像处理算法。图像处理算法需要高效的开发方式和高速高吞吐量的硬件平台以满足现代工业视觉检测要求。而在fpga加速领域中,fpga具有更强大的原始数据算力以及可重构性,比如fpga可以处理任意精度数据并进行调整。一方面,fpga硬件加速采用流水线优化,能够将各阶段的计算处理过程重叠起来;另一方面,fpga能够通过流水线优化取消数据传输和数据计算的延迟,达到较高的实时性。
技术实现要素:
4.本发明为克服上述现有技术所述的传统工业视觉检测存在检测精度低、检测速率慢、检测总量小的缺陷,提供一种基于高层次综合工具的图像处理方法及系统。
5.为解决上述技术问题,本发明的技术方案如下:
6.一种基于高层次综合工具的图像处理方法,包括以下步骤:
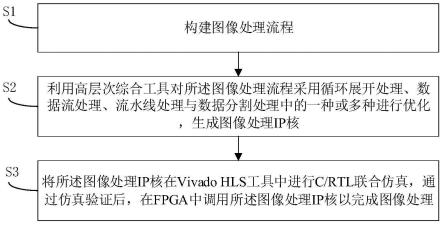
7.构建图像处理流程,其中包括依次执行的基于gauss算法的图像去噪处理、基于sobel算法的边缘提取处理、基于harris算法或fast算法的特征点提取处理;
8.利用高层次综合工具对所述图像处理流程采用循环展开处理、数据流处理、流水线处理与数据分割处理中的一种或多种进行优化,生成图像处理ip核;
9.将所述图像处理ip核在vivado hls工具中进行c/rtl联合仿真,通过仿真验证后,在fpga中调用所述图像处理ip核以完成图像处理。
10.进一步地,本发明还提出了一种基于高层次综合工具的图像处理系统,其应用本发明提出的高层次综合工具的图像处理方法。
11.所述图像处理系统中包括依次连接的图像采集模块、图像处理模块和图像显示模块;所述图像处理模块中包括基于gauss算法的图像去噪单元、基于sobel算法的边缘提取单元、基于harris算法或fast算法的特征点提取单元;其中,所述图像去噪单元、边缘提取单元和特征点提取单元中包括利用高层次综合工具对图像处理流程采用循环展开处理、数据流处理、流水线处理与数据分割处理中的一种或多种进行优化生成得到的图像处理ip
核。
12.与现有技术相比,本发明技术方案的有益效果是:本发明利用高层次综合工具进行的图像处理算法的设计与优化,针对图像处理算法进行并行化改进,从而提升图像处理速度,满足高速高吞吐量的应用需求,尤其适用于工业实时检测领域。
附图说明
13.图1为实施例1的基于高层次综合工具的图像处理方法的流程图。
14.图2为gauss滤波算法流程图。
15.图3为gauss滤波算法权重参数计算部分的伪代码示意图。
16.图4为gauss滤波算法gauss滤波计算部分的伪代码示意图。
17.图5为sobel滤波算法流程图。
18.图6为sobel滤波算法的伪代码示意图。
19.图7为harris角点提取算法流程图。
20.图8为harris角点提取算法的伪代码示意图。
21.图9为fast特征点提取算法流程图。
22.图10为fast特征点提取算法的伪代码示意图。
23.图11为实施例2中各阶段图像处理效果图。
24.图12为实施例3的基于高层次综合工具的图像处理系统的架构图。
具体实施方式
25.附图仅用于示例性说明,不能理解为对本专利的限制;
26.为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
27.对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
28.下面结合附图和实施例对本发明的技术方案做进一步的说明。
29.实施例1
30.本实施例提出一种基于高层次综合工具的图像处理方法,如图1所示,为本实施例的基于高层次综合工具的图像处理方法的流程图。
31.本实施例提出的基于高层次综合工具的图像处理方法中,包括以下步骤:
32.s1、构建图像处理流程,其中包括依次执行的基于gauss算法的图像去噪处理、基于sobel算法的边缘提取处理、基于harris算法或fast算法的特征点提取处理。
33.s2、利用高层次综合工具对所述图像处理流程采用循环展开处理、数据流处理、流水线处理与数据分割处理中的一种或多种进行优化,生成图像处理ip核。
34.s3、将所述图像处理ip核在vivado hls工具中进行c/rtl联合仿真,通过仿真验证后,在fpga中调用所述图像处理ip核以完成图像处理。
35.其中,可选地使用c语言设计gauss、sobel、harris与fast四种图像处理算法,然后针对所设计的图像处理算法采用循环展开、数据流、流水线与数组分割来提升图像处理速度,从而提升图像处理速度,满足高速高吞吐量的应用需求。
36.本实施例提出的图像处理方法主要面向工业检测场景设计,在一具体实施过程中,使用gauss算法将模板图像与待测图像进行去噪处理,用于减少相机底噪的影响;然后,经过直方图均衡化,使用sobel算法进行边缘提取;接着,使用harris算法和fast算法进行特征点提取,完成图像配准;最后,经过差值计算和阈值判断输出缺陷图。其中,gauss、sobel、harris与fast四种图像处理算法利用高层次综合工具采用循环展开处理、数据流处理、流水线处理与数据分割处理中的一种或多种进行优化,生成经过加速优化的图像处理ip核。
37.在一可选实施例中,所述基于gauss算法的图像去噪处理包括以下步骤:
38.(1)初始化操作:导入初始权重参数及输入图像,所述权重参数包括偏移量参数σ、权重参数核的大小n;
39.(2)权重参数计算:通过gauss函数计算其权重参数σ和n并存储,重复计算过程至权重参数边界完成遍历,输出权重参数核的大小n;
40.(3)卷积处理:将图像与权重参数进行卷积计算,并与权重参数总和进行平均计算,重复计算过程至图像完成遍历,输出完成去噪的图像,并存储所述权重参数。
41.如图2所示,为gauss滤波算法流程图,图示中虚线框内为较高延迟部分,也是需要重点优化部分。其伪代码如图3、4所示。
42.本实施例将gauss滤波算法分为权重函数计算以及gauss滤波计算两大部分。在一具体实施过程中,其优化前的运行参数如下表1所示。
43.表1优化前gauss滤波算法的延迟
[0044][0045]
权重函数计算分为两个循环体进行处理,第一部分的延迟(lantency)为51个时钟周期,其中迭代延迟(iteration lantency)为17个时钟周期,行程计数(trip count)为3。总延迟为迭代延迟与行程计数的乘积。第二部分延迟为36个时钟周期,迭代延迟为12个,行程计数为3。权重函数的两个部分在迭代延迟消耗的时钟周期数较高,超过了10个时钟周期,反映了fpga不善于进行指数以及浮点的计算。第二个函数为权重卷积计算,函数分成了初始化、行循环计算以及列循环计算步骤。初始化的循环体中延迟为1024个时钟周期,延迟较高,迭代延迟为2个时钟周期。每次循环不产生数据依赖,属于完美循环体(perfect loop),即循环体中的每次迭代中数据结果无关,可将此部分进行循环展开或流水线操作。行循环中的延迟更是达到了2099712个时钟周期,时间消耗主体处于该部分。行循环与列循环存在嵌套循环关系。嵌套循环中的列循环的延迟为4096个时钟周期,迭代延迟为8个周期,而行循环每次迭代都会受到列循环的延迟影响,因此在此部分需要进行优化。此外,由于gauss的权重参数在计算完成后会频繁的使用,因此需要将权重参数进行固化,在流水线过程中减少调度参数的时间。
[0046]
进一步地,利用高层次综合工具对基于gauss算法的图像去噪处理流程进行优化
的步骤包括:
[0047]
以pragma hls unroll指令将gauss算法的初始化操作进行循环展开;
[0048]
以pragma hls pipeline指令将权重参数计算进行流水线处理;
[0049]
以pragma hls pipeline指令将图像与权重参数卷积进行流水线处理;
[0050]
以pragma array_partition complete指令将权重参数存储进行数组分割。
[0051]
本实施例中,对于gauss算法,优化的重点在于并行性优化,具体地,使用pragma预处理指令指导高层次综合工具进行针对性优化。
[0052]
其中,本实施例将基于gauss算法的图像去噪处理划分为两个部分,第一部分为权重参数算法,该权重参数算法的输入为σ和n,σ决定了权重参数偏移量,n决定了权重参数核的大小。输出为长宽n的权重参数核。该部分中,权重函数计算涉及到较为复杂的浮点以及指数计算,同时在权重参数算法内循环体为一个嵌套循环体,循环体的边界条件取决于算法输入n,本实施例使用#pragma hls unroll指令将初始化操作进行循环展开,使得初始化循环完全展开,以及使用#pragma hls pipeline指令将权重参数计算进行流水线处理。
[0053]
第二部分算法为背景噪声去除算法,由两个循环体构成,分别是权重参数总和与图像卷积的计算,其中图像卷积的计算包括了四层嵌套循环,并且外层循环中有数据依赖关系。本实施例使用#pragma hls pipeline指令将图像与权重参数卷积进行流水线处理,使用#pragma array_partition complete指令将权重参数存储进行数组分割。在一具体实施过程中,选择complete作为type参数,将数组全部打散以寄存器形式实现。
[0054]
经高层次综合优化后的gauss滤波算法的运行参数如下表2所示。
[0055]
表2优化后的gauss滤波算法的延迟
[0056][0057]
由表1、2可知,权重卷积计算中的列循环进行流水优化后延迟减少至516个时钟周期,原本的列循环延迟为4096个时钟周期,延迟变为原本的八分之一,采取的启动间隔为(initiation interval)为1。循环初始化函数在进行流水线优化后的延迟变为512。
[0058]
在一可选实施例中,所述基于sobel算法的边缘提取处理包括以下步骤:
[0059]
导入水平方向卷积核、竖直方向卷积核,以及sobel算子;
[0060]
将输入图像分别通过所述水平方向卷积核和竖直方向卷积核进行卷积,遍历图像后得到经过水平滤波的图像和经过竖直滤波的图像;
[0061]
将经过水平滤波的图像和经过竖直滤波的图像利用sobel算子进行加权平均,导出完成边缘提取的图像;存储所述sobel算子。
[0062]
如图5所示,为sobel滤波算法流程图,其中虚线框图为延迟较高的部分。sobel算法通过sobel算子进行边缘提取操作,其中sobel算子由一阶导数计算得到。本实施例共取两个方向进行边缘提取,分别为水平方向与竖直方向。算法的输入与输出分别为图像的输入与输出。sobel算法由两个函数主体构成,分别是sobel滤波函数和加权计算函数。这两个
函数主体中存在着大量循环体,包括嵌套循环体。其中完美循环体特别适合利用高层次综合技术去进行相关的优化。如图6所示,为sobel滤波算法的伪代码示意图。
[0063]
进一步地,利用高层次综合工具对基于sobel算法的边缘提取处理流程进行优化的步骤包括:
[0064]
以pragma hls dataflow指令将水平方向卷积与加权计算衔接,以及竖直方向卷积与加权计算衔接进行数据流处理;
[0065]
以pragma hls pipeline指令将水平方向卷积、竖直方向卷积和加权平均计算进行流水线处理;
[0066]
以pragma array_partition variable指令将sobel算子分成一维数组存储。
[0067]
本实施例中,考虑到sobel算法中的两个主要函数时延消耗较大,其中行程计数为图片的长和宽,也是循环的边界条件。本实施例使用#pragma hls dataflow指令将水平和竖直方向卷积与加权计算衔接进行数据流处理。其中dataflow pragma支持任务级流水线,允许函数和循环在它们的操作中重叠,增加了rtl实现的并发性,并增加了设计的总体吞吐量。
[0068]
sobel算法中将水平滤波与竖直滤波图像图像进行并行处理,因为两个滤波结果没有数据依赖关系,可以实现并行架构,且为完美循环体,适合使用流水线优化。本实施例使用#pragma hls pipeline指令将水平方向卷积、竖直方向卷积和加权平均计算进行流水线处理。因为是完美循环体,不存在阻止循环流水线,所以采用pipeline pragma来并发执行操作。在一具体实施过程中,默认启动间隔为1。
[0069]
此外,在sobel算子部分使用#pragma array_partition variable指令将sobel算子分成一维数组存储,有助于之后直接进行流水线操作的调度。
[0070]
优化前后的sobel算法运行参数分别如下表3、4所示。
[0071]
表3优化前的sobel算法延迟
[0072][0073]
表4优化后的sobel算法延迟
[0074][0075]
由上表可见,方向滤波计算经过流水线优化后,行循环的延迟减少了三分之二,列循环的延迟减少至515个时钟周期。加权计算中的行循环经过优化后,延迟减少了三分之二,列循环的延迟减少至512个时钟周期。总延迟减少至原来的三分之一。
[0076]
在一可选实施例中,基于harris算法的特征点提取处理包括以下步骤:
[0077]
导入水平方向卷积核、竖直方向卷积核;
[0078]
将经过边缘提取处理的图像分别通过所述水平方向卷积核和竖直方向卷积核进行卷积,遍历图像后得到经过水平滤波的图像和经过竖直滤波的图像;
[0079]
将经过水平滤波的图像通过平方计算函数,将经过竖直滤波的图像通过平方计算函数,以及将经过水平滤波的图像和经过竖直滤波的图像通过乘方计算函数计算处理后,输入r响应函数中进行计算;
[0080]
根据计算得到的r响应函数值进行窗口阈值判断,在图像上标注角点后输出图像。
[0081]
如图7所示,为harris角点提取算法流程图,其中,算法的输入为原始图像,输出为标定特征点后的图像。harris角点提取算法主要由五个函数主体构成,分别是方向滤波函数、平方计算函数、乘法计算函数、r响应函数和筛选函数。其中方向滤波函数与边缘检测算法的函数相同,但是在原本的边缘检测函数中,使用了权重函数将水平方向滤波与竖直方向滤波进行合并,而在harris特征点提取中不需要将方向滤波的图像进行加权,而是需要将水平方向滤波与竖直方向滤波图像进行导出,因此此函数的的输入为原图像,而输出为水平滤波图像与竖直滤波图像。平方计算函数与乘法计算函数为r响应函数计算中的元素计算,分别为图像乘积与图像平方计算。r响应函数后会通过筛选函数选出特征点。
[0082]
如图8所示,为harris角点提取算法的伪代码示意图。除了方向滤波函数外,其余四个函数中都包括了完美循环体。
[0083]
进一步地,利用高层次综合工具对基于harris算法的特征点提取处理流程进行优化的步骤包括:
[0084]
以pragma hls pipeline指令将水平方向卷积、竖直方向卷积、水平方向滤波平方、竖直方向滤波平方、水平与竖直滤波图像乘方、r响应函数计算和窗口阈值判断分别进行流水线处理;
[0085]
以pragma hls dataflow指令对r响应函数计算时的读取图像操作进行数据流处理;
[0086]
以pragma hls unroll指令对窗口阈值判断操作进行循环展开优化。
[0087]
由harris角点提取算法的处理过程可知,在计算完水平滤波图像与竖直滤波图像后,需要将这两个滤波图像进行平方以及乘方操作,两个滤波图像的平方操作是将图像的每个像素点进行平方,最消耗时间的部分为遍历全图像素点,其次为图像传输操作。在图像传输操作中,使用流水线优化指令,加快图像传输图像速率。在图像平方以及乘方的部分使用循环展开优化,将遍历图像的计算部分展开成并行操作。计算r响应函数时,需要读取水平滤波平方图、竖直滤波平方图以及水平与竖直滤波乘方图,读取图像时会消耗较多时间,流水线优化以及数据流优化能够在图像乘积以及图像平方的读取操作上减少消耗时间。
[0088]
本实施例在对应的函数体处加入#pragma hls pipeline指令和#pragma hls dataflow指令,指定factor=1,pipeline可以缩短c函数或c循环之内的指令触发间隔,dataflow编译指示启用任务级流水打拍,允许函数和循环在其操作过程中重叠,增加rtl实现的并发度,并增加设计的整体吞吐量。
[0089]
而判断窗口阈值部分算法主要是将r响应函数的计算结果进行阈值判断,在图像读取中可选地使用流水线操作加速图像读取,在遍历阈值判断中使用了循环展开优化,加
速阈值判断。本实施例通过将上述函数进行高层次综合的循环展开优化减少特征点检测的总延迟。优化前后的harris角点提取算法运行参数分别如下表5、6所示。
[0090]
表5优化前的harris角点提取算法延迟
[0091][0092]
表6优化后的harris角点提取算法延迟
[0093][0094]
由上表可见,每个函数的总延迟均显著减少,尤其是r相应函数运算中,其行循环经过优化后,其延迟从1310720个时钟周期减少至264192个时钟周期。此外,其启动间隔从优化前的3952172个时钟周期减少到268326个时钟周期。
[0095]
在一可选实施例中,基于fast算法的特征点提取处理的步骤包括:
[0096]
导入bresham圆坐标与经过边缘提取处理的图像;
[0097]
通过候选角点选取函数,对选取的每一个像素点进行bresham圆差运算,将bresham圆中的像素点进行连续性对比,选出候选角点,并计算每个候选角点的角点值;
[0098]
导入选出的候选角点,通过非极大值抑制函数对所述候选角点进行窗口的非极大值抑制,筛选出角点;
[0099]
在图像上标注角点后输出图像。
[0100]
如图9所示,为fast特征点提取算法流程图,其中,算法主要由两个函数主体构成,为候选角点选取函数和非极大值抑制函数。候选角点选取函数是将bresham圆中的像素点进行连续性对比将候选角点选出,同时计算每个候选角点的角点值。非极大值抑制函数主要是将候选的角点进行筛选。在筛选窗口内出现候选角点时,将对窗口内的角点进行角点值比较,选出角点。
[0101]
如图10所示,为fast特征点提取算法的伪代码示意图。由伪代码可知,两个函数主体中都包括循环体。
[0102]
经过进行延迟测试,得到如表7所示的fast特征点提取算法延迟数据。
[0103]
表7优化前的fast特征点提取算法延迟
[0104][0105]
由上表可知,候选角点选取函数总延迟为1129533个时钟周期。其计算过程中需要中心点与周围bresham圆上的点进行比较,只有当周围的某一像素点满足其条件才能进行下一操作,否则跳过该点。这种特性使得其分支较多。非极大值抑制函数的总延迟为7372306个时钟周期,其中读取数据延迟为1545个时钟周期。图像遍历中列循环延迟为14364个时钟周期,迭代延迟为28个时钟周期。这两个函数为此算法高延迟的主要部分,将在加速设计中主要对这两个函数进行优化处理,从而为fast角点提取作进一步加速。
[0106]
进一步地,利用高层次综合工具对基于fast算法的特征点提取处理流程进行优化的步骤包括:
[0107]
以pragma hls pipeline指令对将选取的像素点进行bresham圆差运算操作进行流水线优化;
[0108]
以pragma hls unroll指令对窗口的非极大值抑制操作采用循环展开的形式进行优化。
[0109]
本实施例中,使用#pragma hls pipeline指令对将选取的像素点进行bresham圆差运算操作进行流水线优化,其中涉及对选取的每一个中心点进行bresham圆差运算,为该算法的主要时延消耗部分。
[0110]
在导出候选角点后,进行窗口的非极大值抑制,窗口的非极大值抑制在前面函数延迟分析中的消耗较严重,因此需要重点进行优化。由于窗口的边界是固定的,本实施例使用#pragma hls unroll指令采用循环展开的形式进行优化,同时在导入候选角点的部分可以使用#pragma hls pipeline ii=1指令采用流水线优化。
[0111]
此外,在图像进行导入以及导出的过程中为了节约传输时间,可选地使用流水线优化指令,利用流水线优化达到接近并行的图像传输速率。在导入7x7滑窗的过程中,使用array_partition complete dim=1指令,将目标像素点周围的16个像素点作为单元进行存储,之后进行逐次比较时调用时间能够减少。
[0112]
得到每个像素点的差值后进行分类,分类过程中使用循环展开指令减少像素遍历时间。完整指令为#pragma array_partition type=complete dim=1。type默认为comlete完全分区可将阵列分解为多个独立元素。对于一维阵列,这对应于将存储器解析为独立寄存器。dim=1指定区的多维阵列的维度,dim=1代表对第1个维度进行分区。
[0113]
经高层次综合优化后的fast算法延迟数据如下表8所示。
[0114]
表8优化后的fast算法延迟
[0115][0116]
比对表7、8可知,经高层次综合优化后的fast算法中,延迟得到显著的减少,尤其是候选角选取函数部分算法,总延迟从1129533个时钟周期下降至272440个时钟周期。
[0117]
本实施例利用高层次综合工具进行的图像处理算法的设计与优化,针对图像处理算法进行并行化改进,从而提升图像处理速度,满足高速高吞吐量的应用需求,尤其适用于工业实时检测领域。
[0118]
实施例2
[0119]
本实施例应用实施例1提出的高层次综合工具的图像处理方法,应用于工业实时检测领域。
[0120]
首先,构建图像处理流程。本实施例中的图像处理流程包括:
[0121]
(1)基于gauss算法的图像去噪处理;
[0122]
(2)灰度直方图均衡化处理;
[0123]
(3)基于sobel算法的边缘提取处理;
[0124]
(4)基于harris算法或fast算法的特征点提取处理;
[0125]
(5)基于otus算法的图像二值化分割处理;
[0126]
(6)差值计算;
[0127]
(7)图片显示。
[0128]
上述图像处理流程中,首先使用gauss算法将模板图像与待测图像进行去噪处理,去噪的目的是减少相机底噪的影响;然后,经过直方图均衡化,使用sobel算法进行边缘提取;接着,使用harris算法和fast算法进行特征点提取,完成图像配准;最后,经过差值计算和阈值判断输出缺陷图。
[0129]
其中,对基于gauss算法的图像去噪处理、基于sobel算法的边缘提取处理、基于harris算法或fast算法的特征点提取处理等处理流程,利用高层次综合工具采用循环展开处理、数据流处理、流水线处理与数据分割处理中的一种或多种进行优化,生成图像处理ip核。
[0130]
对经过高层次综合优化后的ip核在vivado hls工具中进行c/rtl联合仿真,通过仿真验证后,在fpga中调用所述图像处理ip核以完成图像处理。
[0131]
对经过加速优化后的ip核进行图像质量的对比测试以及搭建工业检测流程进行测试。如图11所示,为本实施例各阶段图像处理效果图。其中,图11(a)为原始图片,该图片还有相机底噪需要进行滤波处理。图11(b)为进行了降噪处理后的图像,去除无关噪声后能够凸显特征信息。图11(c)为直方图均衡化后的图像,对比度明显增加。图11(d)和图11(e)
分别为基于边缘和特征点的提取,便于后面的图像配准操作。图11(f)为otsu法后的二值图像,通过otsu法选取特征与背景差距最大的阈值。图11(g)为差值计算后的图像,可以发现图像中除了含有缺陷信息还有其他无关信息。最后,通过开运算删除无关信息得到图11(h)缺陷检测效果图,白点部分为检测的缺陷位置。
[0132]
进一步地,本实施例将优化前的ip核作为基准组,将加速优化后的ip核作为改进组,进行图像处理测试。各算法的资源消耗和时间消耗对比情况如下表9~16所示。
[0133]
表9 gauss滤波算法资源消耗
[0134][0135]
表10 gauss滤波算法时间消耗
[0136][0137]
表11 sobel滤波算法资源消耗
[0138][0139]
表12 sobel滤波算法时间消耗
[0140][0141]
表13 harris算法资源消耗
[0142][0143]
表14 harris算法时间消耗
[0144][0145]
表15 fast算法资源消耗
[0146][0147]
表16 fast算法时间消耗
[0148][0149]
由上表可知,本实施例能够在消耗相同资源的情况下,实现更高检测精度、检测速率和检测总量的工业视觉检测,有效提升图像处理速度,满足高速高吞吐量的应用需求。
[0150]
实施例3
[0151]
本实施例提出一种基于高层次综合工具的图像处理系统,应用实施例1提出的高层次综合工具的图像处理方法。如图12所示,为本实施例的图像处理系统的架构图。
[0152]
本实施例提出的图像处理系统中,包括依次连接的图像采集模块、图像处理模块和图像显示模块。
[0153]
其中,所述图像处理模块中包括基于gauss算法的图像去噪单元、基于sobel算法的边缘提取单元、基于harris算法或fast算法的特征点提取单元。
[0154]
本实施例中的所述图像去噪单元、边缘提取单元和特征点提取单元中包括利用高层次综合工具对图像处理流程采用循环展开处理、数据流处理、流水线处理与数据分割处理中的一种或多种进行优化生成得到的图像处理ip核。
[0155]
在一可选实施例中,利用高层次综合工具对基于gauss算法的图像去噪处理流程进行优化的步骤包括:
[0156]
以pragma hls unroll指令将gauss算法的初始化操作进行循环展开;
[0157]
以pragma hls pipeline指令将权重参数计算进行流水线处理;
[0158]
以pragma hls pipeline指令将图像与权重参数卷积进行流水线处理;
[0159]
以pragma array_partition complete指令将权重参数存储进行数组分割。
[0160]
在一可选实施例中,利用高层次综合工具对基于sobel算法的边缘提取处理流程进行优化的步骤包括:
[0161]
以pragma hls dataflow指令将水平方向卷积与加权计算衔接,以及竖直方向卷积与加权计算衔接进行数据流处理;
[0162]
以pragma hls pipeline指令将水平方向卷积、竖直方向卷积和加权平均计算进行流水线处理;
[0163]
以pragma array_partition variable指令将sobel算子分成一维数组存储。
[0164]
在一可选实施例中,利用高层次综合工具对基于harris算法的特征点提取处理流程进行优化的步骤包括:
[0165]
以pragma hls pipeline指令将水平方向卷积、竖直方向卷积、水平方向滤波平方、竖直方向滤波平方、水平与竖直滤波图像乘方、r响应函数计算和窗口阈值判断分别进行流水线处理;
[0166]
以pragma hls dataflow指令对r响应函数计算时的读取图像操作进行数据流处理;
[0167]
以pragma hls unroll指令对窗口阈值判断操作进行循环展开优化。
[0168]
在一可选实施例中,利用高层次综合工具对基于fast算法的特征点提取处理流程进行优化的步骤包括:
[0169]
以pragma hls pipeline指令对将选取的像素点进行bresham圆差运算操作进行流水线优化;
[0170]
以pragma hls unroll指令对窗口的非极大值抑制操作采用循环展开的形式进行优化。
[0171]
在一具体实施过程中,选用相机ov5640作为图像采集模块,采用arm核通过sccb协议对相机的寄存器进行配置。配置完成后通过驱动电路进入zynqultrascale+,在zynq中通过摄像头采集接口得到rgb565格式的图片,将图片转换成rgb888的形式供后续操作。由于xilinx芯片内部提供较强大的片内互连总线axi,因此将图像rgb信息转换成axi-stream可以更加方便的进行互联,图像信息后续以axi形式进行传输。采集图像数据需要缓存在ddr中进行后续操作,而pl中访问ddr,需要通过vdma进行访问。采集到的两帧数据存储在ddr中,同时图像处理模块也通过vdma对缓存的图像进行读取。图像处理模块通过axi总线进行图像的读取,且图像处理模块中各个ip核完成图像处理后,通过vdma缓存至ddr中供ps端进行读取。ps读取后通过dp接口协议进行输出。由于输出图像的dp协议时钟需要74.25mhz,因此通过pll将ps输出时钟100mhz转换为74.25mhz。最后通过电平转换电路以及单端转差分电路将信号输出至图像显示模块中进行显示。
[0172]
附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;
[0173]
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可
以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1