一种冷链食品短文本情报主题挖掘系统及方法与流程
本发明涉及文本挖掘,具体是一种冷链食品短文本情报主题挖掘系统及方法。
背景技术:
1、通过搜集和研判冷链食品海量情报信息,在大量文本信息中及时发现正在发生的热点主题,对于识别进口冷链食品风险具有重要意义。而网络舆情作为重要的情报信息集散地,舆情信息内容简短等特性增加了信息理解和监控的难度,因此从舆情短文本信息中自动分析并挖掘出隐含的语义模式,将显著提升对冷链食品情报信息挖掘的能力,增强对冷链食品网络信息的传播过程中情报识别与监控;因此,针对冷链食品段文本信息的主题挖掘有着十分重要的意义。
2、在文本挖掘领域,主题挖掘技术旨在从大量文本数据中无监督地挖掘出语料中隐含的语义模式;传统主题挖掘常常基于词袋假设,其仅仅根据文档内的词与词的共现关系进行主题建模;社交媒体和新闻报道等文本信息具有文本长度短,信息量大,传播速度快的特点,但是短文本文档内的词与词的共现关系减弱,导致文本主题发现能力降低的痛点。当情报通过短文本传播时,由于短文本中词共现信息的缺乏与不足,传统主题模型所抽主题质量不高的现象表现得尤为明显。如果在主题挖掘过程中利用公开的外部语义知识,能解决主题抽取质量不高的问题。
3、随着深度神经网络的快速发展,出现了许多新兴的表示学习技术;采用表示学习的方法提升了短文本主题挖掘能力;这类方法主要有融合广义波利亚球罐与词嵌入的短文本主题挖掘算法(gpu-dmm)、融合知识图谱嵌入的主题挖掘算法(kge-lda)、基于知识图谱的主题挖掘算法(tmkge)以及加入潜在特征词表示改进的主题挖掘算法(lf-dmm)等。其中融合广义波利亚球罐与词嵌入的短文本主题挖掘算法(gpu-dmm)为这类方法的主要代表,该模型采用了基于广义波利亚球罐(generalized polya urn,gpu)机制的采样策略,并将词嵌入中存储的词法、语法和句法知识融入主题建模的过程,使得模型在求解过程中能够考虑每个主题下词与词之间的语义相关程度,得以将语义相关的词更好地聚集在一个主题中,从而提升主题的抽取质量。但是现有基于外部知识的主题模型在主题建模过程中仅引入单一的外部知识去提升抽取主题的质量;这类方法在主题建模的过程中只从一个视角考虑了在一种外部知识背景下词之间特定的关系,很难从多视角全面综合的角度去考虑词与词之间在不同知识背景下的关系,限制了挖掘出主题的质量,导致挖掘出主题的质量不高。
技术实现思路
1、本发明的目的在于提供一种冷链食品短文本情报主题挖掘系统及方法,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:
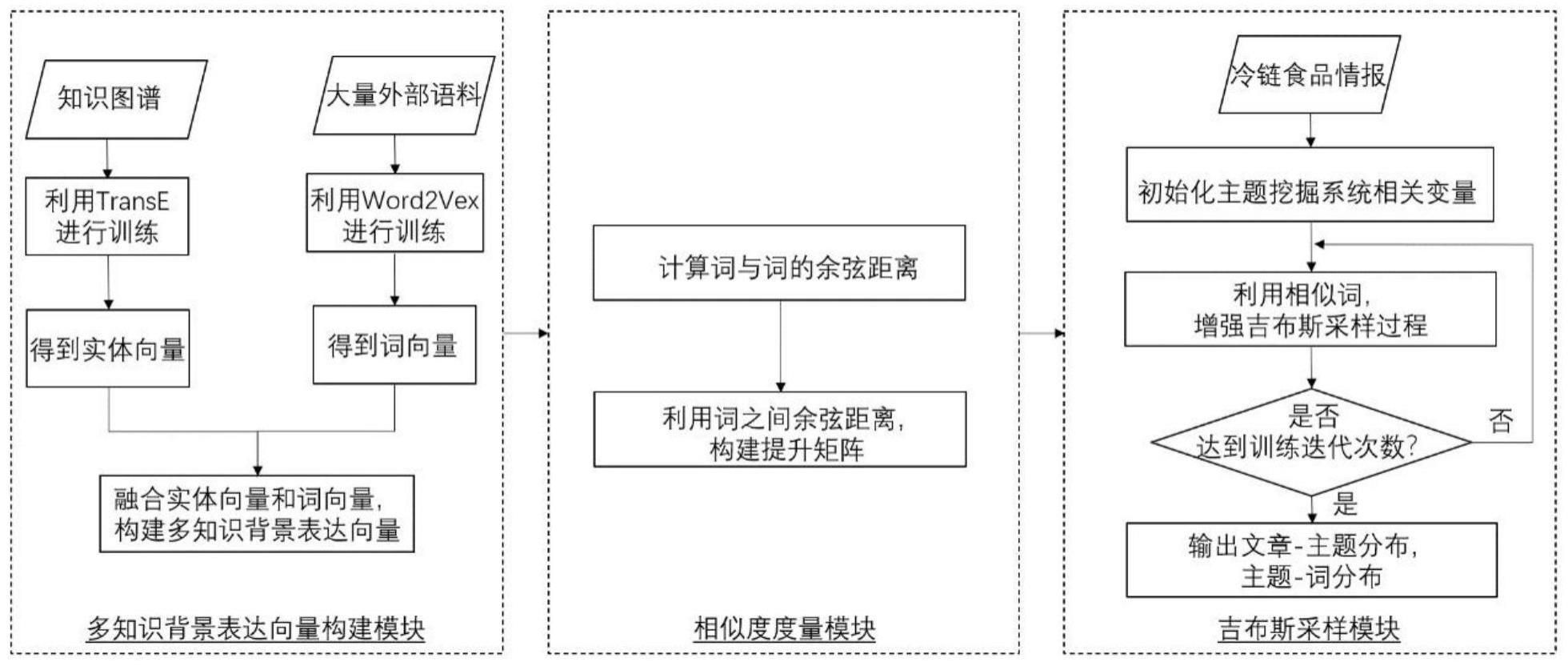
3、一种冷链食品短文本情报主题挖掘系统,包括多知识背景向量构建模块、多知识背景下的相似度度量模块以及相似词增强的吉布斯采样模块,所述多知识背景向量构建模块用于将预先训练好的词向量和实体向量融合形成单词的多知识背景向量;
4、所述相似度度量模块用于计算单词的多知识背景向量之间夹角的余弦距离,并利用余弦距离构建提升矩阵;
5、所述吉布斯采样模块用于将具有相似知识背景的单词尽可能分配到同一主题下。
6、一种冷链食品短文本情报主题挖掘方法,包括以下步骤:
7、s1、定义符号:假定语料库中包含n个文档,文档由m个词组成,且被表示为d=wd,1,wd,2,…,wd,m,其中每个单词wd,m(m∈{1,2,…,m})为词表中的一项,词表大小为v;通过从语料库中挖掘出来k个隐主题zd的生成式模型生成文档d中每一个词wd,m;其实现方法包括以下步骤:首先,根据语料库对应的主题分布θ采样一个隐主题zd;再根据隐主题zd对应的词分布采样对应的词wd,m;
8、s2、多知识背景向量构建:通过多知识背景向量构建模块将预先训练好的词向量和实体向量融合形成单词的多知识背景向量,以存储单词与单词之间在语义背景和基于现实世界知识背景下的关系;
9、s3、相似度度量:通过相似度度量模块计算两个单词的多知识背景向量之间夹角的余弦距离,并利用余弦距离构建提升矩阵,以确定单词与单词之间的相似性;
10、s4、吉布斯采样:通过吉布斯采样模块将具有相似知识背景的单词尽可能分配到同一主题下,以提升短文本情报主题挖掘能力。
11、作为本发明进一步的方案:所述多知识背景向量构建模块的具体工作方法包括以下步骤:
12、s21、通过知识表达学习模型transe训练知识图谱中实体的关系特征,并将知识图谱中的实体映射成高维空间向量,得到实体向量;通过知识表达学习模型word2vec训练大量的外部语料,得到词向量,其中,词向量保存了单词间的语义关系,实体向量则捕捉到实体之间面向事实的关系;
13、s22、将预先训练好的词向量和实体向量融合形成单词的多知识背景向量,通过多知识背景向量存储词与词之间在语义背景和基于现实世界知识背景下的关系。
14、作为本发明再进一步的方案:所述相似度度量模块的具体工作方法包括以下步骤:
15、s31、计算两个单词的多知识背景向量之间的余弦距离,通过余弦距离来度量单词与单词之间的相似性,其中,距离越近则表示单词间相似度越高;
16、s32、预先设定一个相似性阈值,比较两个单词之间的余弦距离与相似性阈值的大小,选出知识背景高度相似的单词,并构建提升矩阵,如果两个单词之间的余弦距离大于该阈值,则认为这两个单词的知识背景是高度相似的,如果两个单词之间的余弦距离小于该阈值,则认为这两个单词的知识背景不是高度相似的。
17、作为本发明再进一步的方案:所述吉布斯采样模块的工作方法包括以下步骤:
18、s41、输入冷链食品情报的短文本情报;初始化短文本情报的相关变量;
19、s42、采用吉布斯采样的方式对短文本情报中单词进行采样,并基于广义波利亚罐子模型的采样策略,利用相似度度量模块获得的相似词,增强、提升吉布斯采样过程;判断采样是否达到训练迭代次数,如果没有达到,则返回上一级,如果达到,则输出主题-词分布以及文章-主题分布,从而将具有相似知识背景的单词尽可能分配到同一主题下,提高挖掘出主题的质量。
20、作为本发明再进一步的方案:所述22步骤中多知识背景向量的定义公式如下:
21、sw=r×vw+(1-r)×ew(1)
22、上式(1)中,sw为多知识背景向量;vw为词向量;ew为实体向量;r为贡献度权重,由于每种知识对模型理解文章内容的贡献程度是不一样的,因此,通过贡献度权重来衡量。
23、作为本发明再进一步的方案:所述s31步骤中余弦距离的计算公式如下:
24、
25、上式(2)中,wi和wj为分别为两个单词;si和sj分别为两个单词对应的多知识背景向量。
26、作为本发明再进一步的方案:所述s32步骤中提升矩阵的定义如下:
27、
28、上式(3)中,为提升矩阵,表示在采样过程中一个单词对另一个单词的提升度;wi和wj为分别为两个单词;μ为超参数,表示高度相似词之间的提升度,σ为相似性阈值。
29、作为本发明再进一步的方案:所述s42步骤中主题-词分布的计算公式如下:
30、
31、上式(3)中,为主题-词分布;为单词w出现在主题k的频数,nk表示词表中所有单词分配给主题k的总频数且v为词表大小;β为预定义的dirichlet超参数;
32、所述s42步骤中吉布斯采样的条件分布公式如下:
33、
34、上式(5)中,为吉布斯采样的条件分布,为分配给主题k的文章数,而为文章d被排除在当前计数过程中;α和β为预定义的dirichlet超参数。
35、与现有技术相比,本发明的有益效果:
36、本发明通过多知识背景向量构建模块将预先训练好的词向量和实体向量融合形成单词的多知识背景向量,以存储单词与单词之间在语义背景和基于现实世界知识背景下的关系;通过相似度度量模块计算两个单词的多知识背景向量之间夹角的余弦距离,并利用余弦距离构建提升矩阵,以确定单词与单词之间的相似性;通过吉布斯采样模块将具有相似知识背景的单词尽可能分配到同一主题下,从而显著提升了短文本情报主题挖掘能力。
- 还没有人留言评论。精彩留言会获得点赞!