基于DLBR的航空发动机性能模型重构方法
基于dlbr的航空发动机性能模型重构方法
技术领域
1.本发明属于涡扇发动机气路特性参数的重构技术领域。
背景技术:
2.航空发动机是飞机的心脏,结构复杂,工况恶劣。在使用过程中,航空发动机的健康状态会逐渐发生变化,当其功能或性能衰退到一定程度时,发动机就需要拆发送修,使其功能或性能得到一定程度的恢复。为了提高发动机的可维修性,现在航空发动机普遍采用结构单元体化的设计原则。随着民航领域发动机单元体设计原则的提出和实施,发动机健康管理(engine health management,ehm)需要从单元体层面来分析发动机健康状况,进而制定合理的维修方案。面向单元体的维修管理模式明显节省了维修时间、降低了维修费用。因此,单元体性能状况的准确评估,对合理地确定单元体/整机性能恢复情况以及制定单元体送修等级具有重要意义。目前单元体性能评估可采用两种方法:第一种是oem(original equipment manufacturer)发动机手册中给出的单元体效率计算方法。该方法基于高度抽象和经验取值的设计模型计算气路单元体效率,判断单元体是否发生劣化。但是过于抽象和简化的模型难以表达复杂服役状态下的单元体性能劣化程度,只能作为参考;第二种是数据驱动方法。oem通过收集各个运营公司的飞行数据和劣化数据,经过大数据分析,给出了单元体性能与整机气路位置参数的映射空间(单元体特性空间),并基于运营商返回的数据建立了参考单元体特性模型,部分单元体特性模型如图1所示,退化的低压涡轮会导致低压压气机的转速降低,从而降低了低压压气机出口压强p
25
和温度t
25
;退化的风扇、高压压缩机和高压涡轮都会导致低压压气机以更高的功率运行以保持稳定的发动机压比,从而提高了低压压气机出口压强和温度。但是oem也指出,由于发动机构型、运行工况不同,oem所提供的单元体特性模型仅供运营商参考,实际的单元体特性模型需根据实际的机队数据建立,以真实反映发动机单元体的性能状态。
3.然而建立单元体特性模型所需的全部气路特性参数往往只有当发动机送回oem进行试车时才能获取。在飞机服役阶段或者在oem以外的地方进行维修时,无法获取构建单元体特性模型所需的全部特性参数。如何基于部分可获得的特性参数数据重构出完整的发动机整机特性数据,支持单元体特性模型建立以实现单元体性能准确评估,从而为航空公司以及维修企业提供运维数据支持是目前亟需研究的科学问题。
技术实现要素:
4.本发明是为了解决航空发动机上仅有少量的传感器能够采集器特性参数,导致构建航空发动机性能模型所需的特性参数不完整、模型无法建立的问题,现提供基于dlbr的航空发动机性能模型重构方法。
5.基于dlbr的航空发动机性能模型重构方法,包括以下步骤:
6.步骤一:将航空发动机完备气路特性参数x输入至训练好的自编码器中对x进行降维与重构,获得重构结果
7.步骤二:以可测气路特性参数s作为输入,以自编码器的特征空间h作为输出,构建基于lstm的s与h之间的映射模型,
8.步骤三:将步骤二构建的映射模型与步骤一中的自编码器建立联系,获得以可测气路特性参数s作为输入、以重构结果作为输出的航空发动机性能重构模型。
9.进一步的,上述步骤一中对x进行降维与重构的具体过程包括:
10.编码过程:
11.将航空发动机完备气路特性参数x经过编码函数f
encoder
(
·
)映射到特征空间h:
12.h=f
encoder
(x)=g(w*x+b),
13.其中,g(
·
)为编码激活函数,w为编码权重矩阵,b为编码偏置向量;
14.解码过程:
15.将特征空间h经过非线性映射函数f
decoder
(
·
)重构获得重构结果
[0016][0017]
其中,w
′
为解码权重矩阵,b
′
为解码偏置向量。
[0018]
进一步的,上述编码激活函数g(
·
)为relu函数。
[0019]
进一步的,上述在对自编码器进行训练时,采用自编码器下降算法反向传播误差以调整自编码器参数{θ,θ
′
}={w,b;w
′
,b
′
},使得重构结果与航空发动机完备气路特性参数x之间的均方误差最小。
[0020]
进一步的,上述重构结果与航空发动机完备气路特性参数x之间的均方误差的表达式为:
[0021][0022]
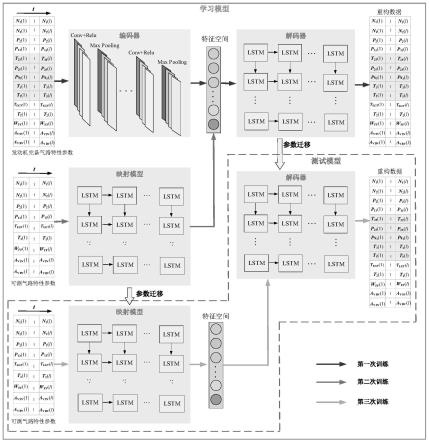
本发明提出了基于dlbr的航空发动机性能模型重构方法主要是基于发动机可测气路特性参数构建的非线性系统与发动机完备气路特性参数构建的非线性系统应一致的基本思想来实现系统重构的。由于发动机气路参数是时序型数据,本发明建立了一种cnn-lstm自编码网络来学习发动机气路系统的特征空间,由于自编码网路可以自定义空间维度数量,因此可以根据气路特性参数维度要求,调整空间维度数量,从而实现发动机两种非线性空间保持一致性的要求。
[0023]
发动机可测气路特性参数空间重构出发动机完备气路特性参数空间的问题,实质上就是用低维空间数据重构出高维空间的过程,通过对自编码器原理分析可知自编码器的解码部分就是从低维空间到高维空间的映射过程。然而,自编码器得到的特征空间是原始数据空间的嵌入空间,如果想使发动机完备气路特性参数空间的嵌入表达与发动机可测气路特性参数空间的嵌入表达保持一致,就需要建立一个二者的映射模型,以便间接实现从发动机可测气路特性参数空间重构发动机完备气路特性参数空间,如图3所示本发明将发动机完备气路特性参数的特征空间(图中特征空间2)为学习目标,建立特征空间2与发动机可测量气路特性参数空间的映射模型(图中模型4),间接将发动机可测气路特性参数空间映射为发动机完备气路特性参数的特征空间2。
[0024]
由于通过映射模型4映射到特征空间2一定存在误差,这个误差经过再一次重构映
射(解码器3)会使得最终气路空间与原始发动机气路完备空间误差较大。经分析可知,在整个重构过程中,重点并不在于映射模型4必须准确无误的映射到特征空间2,而在于将特征空间2作为中间媒介利用发动机可测量气路特性参数空间准确重构原始空间的能力。因此,在自编码器完成发动机完备气路特性参数的特征空间学习后,利用迁移学习方法将解码器3的学习参数作为初始学习参数,设计从映射模型2和解码器3的再学习过程,进一步提高从发动机可测量气路特性参数到发动机完备气路特性参数的映射精度。
附图说明
[0025]
图1为单元体特性空间上的特性模型图;
[0026]
图2为民航发动机基本构型及传感器位置示意图;
[0027]
图3为基于可测气路特性参数重构发动机完备气路特性参数示意图;
[0028]
图4为dlbr重构模型图;
[0029]
图5为自编码器原理示意图;
[0030]
图6为lstm网络结构图;
[0031]
图7为多部件闭环仿真系统结构示意图;
[0032]
图8为仿真系统参数划分甘特图;
[0033]
图9为基于仿真数据的实验结果柱状图;
[0034]
图10为发动机参数划分甘特图;
[0035]
图11为基于发动机数据的mse均值实验结果柱状图;
[0036]
图12为基于发动机数据的mse方差实验结果柱状图;
[0037]
图13为基于scheme3方法的重构误差图。
具体实施方式
[0038]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其它实施例,都属于本发明保护的范围。需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
[0039]
建立单元体特性模型所需的参数往往只有当发动机送回oem进行试车时才能获取。在飞机正常飞行或者在oem以外的地方进行维修时,无法获取构建单元体特性模型所需的所有参数。因此,利用发动机部分可测数据中的有用信息反演出发动机单元体的物理参数,对单元体特性建模具有重要意义。本发明研究的涡扇航空发动机主要由风扇(fan)、低压压气机(low pressure compressor,lpc)、高压压气机(high pressure compressor,hpc)、燃烧室(combustor,cc)、低压涡轮(low pressure turbine,lpt)和高压涡轮(high pressure turbine,hpt)等6个主要单元体组成,如图2所示。图2中还给出了航空发动机的通用部件构成和状态参数测量位置的布置方案。该发动机采用双转子结构,其机内测试系统能够对多个气路位置的气流状态进行测量:其中工况参数及系统外部输入包含进气道总温t2、进气道总压p2、可调静子转叶(variable stator vane,vsv)开度avsv、可调放气活门(variable bleed valve,vbv)开度avbv、低压转子转速n1、lpc出口总温t25、lpc出口总压
p25、燃烧室总温t3、燃烧室静压ps3、燃油流量wff、发动机排气温度tegt、低压涡轮出口总温t5、高压转子转速n2、外涵道进口总压p13。图2中除了上面所提及的14个传感器外,还包括了另外13个通常不可测量的参数,当27个传感器测得的参数就是航空发动机完备气路特性参数。考虑到成本、安全和可维护性等因素,t25、p25、t5、ps3、t3等传感器仅在少数发动机上安装,而其他大多数机队发动机则因为成本、安全、可维护性或者其它因素或多或少有所缺失,所以14个可测量的传感器测得的参数就是可测气路特性参数。
[0040]
发动机在工作过程中,其状态参数及工况参数之间具有很强的耦合性。测量参数之间不具有显式关联,因而难以直接求解。针对以上问题,本实施方式设计了基于自编码器的物理场重构模型。dlbr模型的任务是基于少量测量数据s=[s1,s2,...,sn]最大程度上准确全面地反演出全局物理参数信息x=[x1,x2,...,xm],如图4所示。具体实施方式如下:
[0041]
本实施方式所述的基于dlbr的航空发动机性能模型重构方法,包括以下步骤:
[0042]
步骤一:作为在无监督学习中使用的神经网络,自编码器的输入与期望输出均为无标签样本,而特征空间输出则是样本的抽象特征表示。自编码器的训练过程包括编码和解码2个阶段,如图5所示,自编码器首先接收输入数据,将其转换成高效的抽象表示,而后再输出原始样本的重构。输入层到中间特征空间是编码过程,而由中间特征空间到输出层是属于解码过程。若用x∈rm表示输入向量,h∈rr表示特征向量,表示输出层向量。其中,r<m。具体过程如下:
[0043]
编码过程:
[0044]
将航空发动机完备气路特性参数x经过编码函数f
encoder
(
·
)映射到特征空间h:
[0045]
h=f
encoder
(x)=g(w*x+b),
[0046]
其中,g(
·
)为编码激活函数,具体选用relu函数。w为编码权重矩阵,b为编码偏置向量。
[0047]
解码过程:
[0048]
将特征空间h经过非线性映射函数f
decoder
(
·
)重构获得重构结果
[0049][0050]
其中,w
′
为解码权重矩阵,b
′
为解码偏置向量。与x维度相同。
[0051]
在对自编码器进行训练时,采用自编码器下降算法反向传播误差以调整自编码器参数{θ,θ
′
}={w,b;w
′
,b
′
},使得重构结果与航空发动机完备气路特性参数x之间的均方误差最小。重构结果与航空发动机完备气路特性参数x之间的均方误差的表达式为:
[0052]
在实际训练过程中,通常采用mini-batch(批大小)梯度方法来寻找最优参数。具体地,将训练集划分为若干个mini-batch,即每次调整参数前所选取的样本数量,每次将一个mini-batch输入到模型中,以整个mini-batch的均方误差的作为损失函数。
[0053]
本步骤中以发动机完备气路特性参数x为模型输入,以均方误差(mean square error,mse)为损失函数训练自编码器模型,以adam作为优化器,提取特征空间h。通过编码与解码的过程,实现对输入数据的降维与重构。
[0054][0055]
其中,f
encoder
和f
decoder
分别表示图5中的编码器和解码器。此外,在自编码器中,特征空间h为高度压缩的低维空间,在一定程度上实现了对高维物理场的降维和去噪处理。
[0056]
步骤二:考虑到发动机数据集是典型的时间序列数据,长短期记忆网络(long short-term memory,lstm)学习模型在处理时间序列数据具有很好的效果。因此考虑将lstm作为映射模型。
[0057]
标准的循环神经网络,每个时刻的隐藏层状态由当前输入和前隐藏层的状态同时决定,记忆容量有限而且容易造成梯度消失的问题。lstm网络在rnn的基础上进行改进,主要特征是包含遗忘门、输入门和输出门,如图6所示。
[0058]
图6中的σ表示sigmoid激活函数,输出范围是0~l,tanh用于调节数值大小的函数,输出范围是-1到1之间。基于步骤一得到的特征空间h,建立以可测气路特性参数s为输入,以特征空间h为输出的映射模型:
[0059][0060]
其中,f
reg
表示映射模型,即lstm学习模型。
[0061]
步骤三:x通过编码器f
encoder
得到的特征空间h与可测气路特性参数s通过映射模型f
reg
得到的特征空间h存在误差,当通过步骤一中训练好的解码器进行重构时则放大了此误差。因此,为了消除此误差,将步骤二构建的映射模型与步骤一中的自编码器建立联系,获得以可测气路特性参数s作为输入、以重构结果作为输出的航空发动机性能重构模型:
[0062][0063]
其中,f
′
reg
是在f
reg
的基础上进行精细训练,f
′
decoder
是在f
decoder
的基础上进行精细训练。由于f
encoder
和f
reg
先后进行过训练,因此在第三次训练时调小学习率。
[0064]
考虑到工业领域所应用的多部件闭环系统的结构多变性,测试基于dlbr的重构模型在所有类型系统上的适应性极为困难。为了使数据实验不失一般性,本实施方式搭建了一个具有代表意义的多部件闭环仿真系统,其结构如图7所示。在多部件闭环仿真系统当中,四个部件的局部模型被穿插于其中的信息关联连接起来,形成了系统闭环。观察这些信息关联可以发现,该系统包含了一个并联结构、两个串联结构、一个连接交汇点、以及一个回路。该回路包含一组等式约束e,规定了μ
′1、μ
′4之间的数值关联,从而提供了一个反馈回路以使系统闭环可控。该仿真系统包含了变量之间关联的所有基本类型,并且具有控制变量、不可测量变量、可测量变量等所有在工业系统建模领域问题中的要素,因此在数学意义上能够代表大多数多部件闭环系统。本实施方式定义ω2、ω3、ω4的传递函数如下:
[0065][0066]
式中,εi为1%高斯噪声;ci为可调系数。
[0067]
相应的,与ω2、ω3、ω4所不同的是,传递函数ω1由约束集合e所隐式地定义:
[0068][0069]
各个仿真系统的采样数据通过如下方式生成:首先,在[μ
′1,μ
′4]的矢量空间当中随机抽取500个样本点并求解式e以得到和的数值,而后将和分别输入到ω2和ω3当中得到y2和y3,最后将μ
′4、y2和y3输出到ω4当中得到y4,最终隐藏和y2以模拟系统中的不可测参数,仿真系统的参数划分如图8所示。
[0070]
在该实验当中,为了保证数据集的普遍性,随机选择了10组可调系数(如表1所示),并且通过该10组可调系数分别生成了10个仿真系统。针对每个仿真系统,从其工作空间当中选取了以系统输入矢量[μ
′1,μ
′4]所标定的500个工作点数据作为初始数据集,然后通过求解得到其它参数值。仿真数据集如表2所示,完整数据集可在mendeley数据库中获取。
[0071]
表1仿真系统的10组可调系数
[0072][0073][0074]
表2仿真数据集
[0075][0076]
考虑到发动机数据集是典型的时间序列数据,并且一维卷积神经网络(one-dimensional convolution neural network,1dcnn)和长短期记忆网络(long short-term memory,lstm)两种学习模型在处理时间序列数据具有很好的效果,虽然仿真数据集并不是时间序列数据,但由于1dcnn和lstm也有较好的非线性特征提取能力。因此,本实施方式选择这两种算法作为自编码器或者映射模型。对于dlbr模型,本实施方式组合两种学习模型设计了三种不同的气路特性参数重构模型,分别命名为scheme1、scheme2、scheme3,如表3所示。由于1dcnn,rbfnn,svr,bpnn,lstm等算法具有较好的回归能力,同时为了能和上述重构模型的重构结果进行比较,将1dcnn,rbfnn,svr,bpnn,lstm作为对比实验,即将μ
′1,μ
′4,y3,y4输入到上述五个算法中,输出y2的值。
[0077]
表3三种气路特性参数重构模型
[0078][0079]
每一种方法都在随机划分的训练和测试数据集上重复运行10次。训练集与测试集的数据量之比为3:2。所有算法在10个仿真模型上运行共计100次。该100次重构中所得到的mse的均值和方差均被记录作为各个算法的性能评判指标。每种方法在各个参数的重构实验中的性能评判指标在表4中给出。表中的粗体字表示各种方法当中的最优性能指标。实验结果如表4所示,与表4对应的柱状图如图9所示。
[0080]
表4仿真数据实验结果
[0081]
[0082][0083]
如表4所示,bpnn,lstm,rbfnn,scheme1,scheme2,scheme3对所有参数的重构精度都比较高,几乎所有的mse的均值都低于10-3
。在这六种算法当中,scheme3对和的重构精度最高,并且在和的重构实验当中所表现出的鲁棒性要好于其它算法。对于重构参数y2而言,lstm的重构精度最高,并且表现出的鲁棒性要好于其它算法。经分析,这是由于lstm的输出门层由sigmoid函数与tanh函数相乘所得到,而sigmoid函数包含指数函数,与传递函数ω2一致,会提升参数y2的重构精度。表4中运行时间包含训练和测试时间,scheme3所花费的时间最长,所需时间为64.7秒,这个时间仍然在接受的范围内。当输入测试集到输出重构结果的测试时间仅为0.22秒。通过对表4的分析和上述说明就重构精度和鲁棒性而言,scheme3的重构效果要优于其它算法。
[0084]
为了进一步验证所提模型对未知非线性黑箱系统的适应性,将采用发动机服役数据集进一步检验。发动机数据实验验证:
[0085]
本实施方式选用了机队中某台测量条件完备的发动机气路特性数据,样本覆盖500个循环,部分数据见,完整传感器数据集可在mendeley数据库中获取,如表5所示。训练过程在随机划分的训练集和测试集上共执行10次,训练集与测试集大小的比值为3:2,所获得的mse的均值、方差、以及运行时间被用作评估算法性能。基于发动机数据的实验结果如表6所示,与表6对应的柱状图如图11和图12所示。发动机可测参数与待重构参数的划分如图10所示。
[0086]
表5测量条件完备发动机的部分传感器数据
[0087][0088]
表6发动机数据实验结果
[0089]
[0090][0091]
如表6所示,在重构参数p25,t25,ps3,t3时,scheme3都给出了这八种方法中最低的重构精度,其mse均值约为10-4
数量级,虽然与其它算法最优精度处于同一数量级,但均为最优结果。尤其t25的mse均值为10-5
数量级,其它算法最优精度为10-4数量级,远高于其它算法精度。在mse方差方面,scheme3在p25,t25,t3重构实验当中所表现出的鲁棒性要远好于其它算法,mse方差为10-8
数量级,而其它算法在均为10-7
数量级。scheme3重构参数ps3所得到的mse方差为2.93
×
10-7
,虽然所得到的结果并不最优,但与最优结果为同一数量级,且非常接近。在重构参数t5时,scheme3所得到的mse均值和方差与最优结果均为同一数量级。由于发动机气路系统不像仿真系统那样由基础log、exp等基函数构成的非线性系统,而是一个黑箱复杂非线性系统所以lstm的重构精度相比于其它算法并不具有优势。通过对表4和表的观察不难分析出,相比于仿真数据样本,scheme3在发动机数据样本的重构结果上表现最好的参数不仅量多,而且具有数量级别上的精度提升,而表现非最优的个别参数,其精度与最优的相比是在同一数量级,且非常接近。通过对表4和表的运行时间分析,可以看出发动机数据样本相比于仿真数据样本所需时间更长,这是因为在输入样本数量相同的情况下,样本的维度越大所需要的计算时间越大。在表中,scheme3所需最大时间仅为80.1s,这个结果包括训练和测试时间,仍在可接受的范围内。通过上述分析和说明,scheme3相比于其它算法具有精度和鲁棒性上的双重优势。scheme3能够较好重构发动机气路特性参数的能力。
[0092]
为了进一步量化评估scheme3所得到的重构结果,以前300个循环数据作为训练集,后200个循环数据作为测试集,发动机气路特性参数的重构结果分别如表6和图13所示。
[0093]
表6发动机气路特性参数重构的相对误差
[0094][0095]
图13中的r表示相关系数,代表重构值与原始值之间的相关程度,越接近1表示二者之间的正相关性越大。通过
[0096]
表6可知参数p25,t25,ps3,t3的平均相对误差小于1%,最大相对误差小于4%,说明采用scheme3作为dlbr深度网络模型的基础模型具有较高精度的重构结果。然而对于t5的重构结果相比于其它四个参数而言,精度有明显的下降。通过观察表的重构结果可以发现其它回归算法对于t5的重构结果误差也远高于其它四个参数。上述现象充分说明了t5自身具有难以重构的基本性质,而本文方法所得到的平均相对误差也接近1%,仍在可接受的范围内。一种对t5的难以重构特性的可信解释是,航空发动机低压涡轮的出口界面比较宽阔且气流比较紊乱,因此使得t5的传感器读数难以代表整体气流截面的平均读数。同时也使得t5的传感器测量结果波动大。
[0097]
本实施方式对发动机气路系统中测量多个气路位置的气流状态的传感器进行分析,对可测参数和待重构参数进行划分,确定需要重构的参数。采用了仿真数据和发动机服役数据集进行验证。实现结果表明,相比于回归模型bpnn,svr,lstm,1dcnn,rbfnn,scheme3具有更好的重构精度和鲁棒性。同时也说明了本实施方式搭建的以学习模型为基础模型的新的学习模型,以深度学习为技术模型的dlbr(deep learning-based reconstruction,基于深度学习的重构)网络模型可以建立传感器测量数据与高维物理场数据之间的映射关系,具有实现高维物理场重构的能力。
[0098]
虽然在本文中参照了特定的实施方式来描述本发明,但是应该理解的是,这些实施例仅仅是本发明的原理和应用的示例。因此应该理解的是,可以对示例性的实施例进行许多修改,并且可以设计出其他的布置,只要不偏离所附权利要求所限定的本发明的精神和范围。应该理解的是,可以通过不同于原始权利要求所描述的方式来结合不同的从属权利要求和本文中所述的特征。还可以理解的是,结合单独实施例所描述的特征可以使用在其它所述实施例中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1