一种应用于推荐系统的多阶知识蒸馏方法
1.本发明涉及智能深度学习推荐技术领域,具体涉及一种应用于推荐系统的多阶知识蒸馏方法。
背景技术:
2.推荐系统能够为每个用户提供个性化的项目排名列表。但由于深度学习的快速发展,推荐系统变得越来越复杂,参数量也急剧增加,一般来说,参数量大的推荐模型可以实现更好的性能但同时也存在一些问题:这种模型有很大的推理延迟,且需要巨大的内存和计算成本。因此,采用庞大的推荐模型对于需要快速响应的在线部署是不合适的。
3.近年来,知识蒸馏被广泛应用在推荐系统领域来压缩较大的推荐模型。其由预先训练的大型教师模型学到的知识作为额外监督信息转移到小型学生模型上,使学生模型的性能尽可能地接近教师模型。大量研究已经验证了在推荐性能和推理速度方面,用知识蒸馏技术训练的学生模型优于没有使用任何蒸馏技术的原始学生模型。
4.尽管知识蒸馏在推荐系统领域的应用有效地解决了在线推理延迟问题,并迅速为用户提供项目排名列表,但在如何为不同的用户生成他们真正感兴趣的个性化排名列表方面仍存在很多问题。因此,必须提高学生模型的排名性能,以接近甚至超越教师模型的性能。但是现有教师模型和学生模型之间存在巨大的性能差距;由于大型教师模型有更多的参数,它可以捕获包含丰富信息的知识来实现性能提升。但用教师模型的监督标签训练的小型学生模型仍然难以理解如何正确应用二进制训练集的软标签。
技术实现要素:
5.本发明的目的在于,提供一种应用于推荐系统的多阶知识蒸馏方法,通过引入缓冲模型来缩小教师模型和学生模型之间巨大的排名差异,同时设计了一个过滤器,用来筛选每个推荐器要转移的知识,缩短模型训练及推理时间。
6.为实现上述目的,本技术提出一种应用于推荐系统的多阶知识蒸馏方法,包括:
7.预训练参数量较多的大规模教师模型、较小参数量的小规模学生模型和参数量介于教师模型和学生模型之间的缓冲模型;
8.用二进制训练集和教师模型输出的监督知识联合训练缓冲模型,该监督知识是通过带有tanh饱和激活函数的过滤器筛选的;
9.用二进制训练集和缓冲模型输出的监督知识联合训练学生模型,该监督知识是通过带有sigmoid饱和激活函数的过滤器筛选的;
10.用二进制训练集和学生模型输出的高置信度知识联合训练教师模型,该高置信度知识是通过带有exp函数的过滤器筛选的推荐排名列表里前k个项目的采样概率。
11.进一步的,由于每轮更新一次列表会降低在线推理速度,每p个epoch更新每个模型的推荐排名列表
,
其中一个epoch表示训练集里所有数据在网络中都进行了一次前向传播和一次反向传播,一般p的取值为20。
12.进一步的,利用协同过滤技术训练教师模型t,缓冲模型b以及学生模型s。
13.进一步的,所述缓冲模型的训练是将缓冲模型的协同过滤损失以及蒸馏损失按一定比例加起来进行训练,使缓冲模型尽可能多的学习到教师模型知识。
14.进一步的,带有tanh饱和激活函数的过滤器,采样概率正比于排名差异超过阈值的项目被均匀地采样,其中表示教师模型和缓冲模型的排名差异,ξb(》0)是控制概率平稳性的超参数。
15.更进一步的,所述学生模型的训练是将学生模型的协同过滤损失以及蒸馏损失按一定比例加起来进行训练,使学生模型尽可能多的学习到缓冲模型知识以及缓冲模型学到的教师模型知识。
16.更进一步的,带有sigmoid饱和激活函数采样概率正比于其中表示缓冲模型和学生模型的排名差异,ξs(》0)是控制概率平稳性的超参数。
17.更进一步的,所述教师模型的训练是将教师模型的协同过滤损失以及蒸馏损失按一定比例加起来进行优化,优化后的教师模型也可以进一步提升学生模型的性能。
18.作为更进一步的,带有exp函数的过滤器,采样概率正比于其中表示学生模型和教师模型的排名差异,ξ
t
(》0)是控制概率平稳性的超参数。
19.作为更进一步的,训练推荐模型时,在citeulike和foursquare两个数据集上以及bpr和cdae两个base模型上的参数设置如下:学习率均为10-5
,批次均为1024,优化器为adam,使用hit ratio和normalized discounted cumulative gain作为评判指标,教师模型参数量为学生模型的十倍,蒸馏温度为2。
20.本发明采用的以上技术方案,与现有技术相比,具有的优点是:本发明有效缩小了大型教师模型和小型学生模型之间巨大的排名性能差距,使得学生模型的性能更接近于教师模型。同时,通过过滤器为每个模型筛选出排名差异得分最大的前k个项目,极大地缩短了模型的在线推理时间。
附图说明
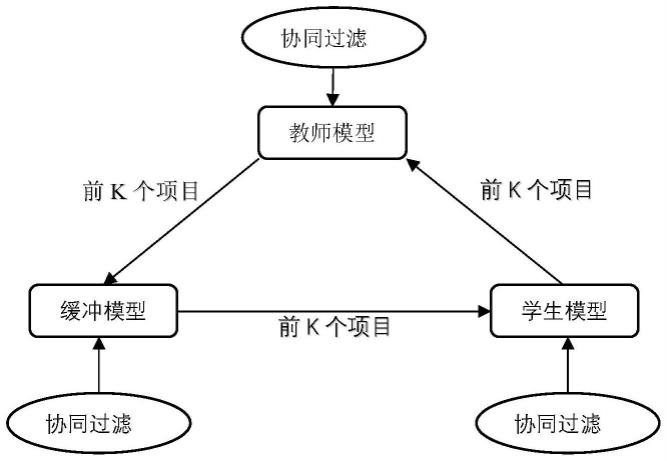
21.图1为一种应用于推荐系统的多阶知识蒸馏方法流程图;
22.图2为实施例中的目标模型联合训练过程图;
23.图3为实施例中的过滤器示意图;
24.图4为推荐模型更新排名列表示意图;
25.图5为多阶知识蒸馏使用效果示意图。
具体实施方式
26.为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行描述和说明。应当理解,此处所描述的具体实施例仅用以解释本技术,并不用于限定本技术。基于本技术提供的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本技术保护的范围。
27.如图1所示,本实施例提供一种应用于推荐系统的多阶知识蒸馏方法,包括教师模型、缓冲模型、学生模型以及过滤器筛选的k个高分项目。其用中等规模的缓冲模型来学习大型教师模型产生的复杂软标签,它可以比小型学生模型更好地学习教师模型的软标签。此外,学生模型可以从缓冲模型中获取更多有用的知识。其可以应用在任何大型推荐模型上,将大模型压缩成小模型实现在线推理。该推荐系统可以设置在需要对用户进行实时推荐的推荐应用中,这些推荐应用可以是购物网站、综合性内容发布网站及相关app等。
28.由于让学生模型学习教师模型的所有知识是很耗时的。因此,提出了一个教师模型、缓冲模型和学生模型的排名差异采样策略,以选择关键的输出信息。基于该策略,每个模型学习它排名较低但被其源模型排名较高的项目,并使学生模型获得教师模型所学习到的不同项目广泛知识。
29.本实施例在推荐模型上提出了一个新的知识蒸馏框架,名为msd,它是一个即插即用的部分,缩小了源模型和目标模型之间巨大的排名性能差距。msd进一步提高了在线推理的速度,增强了每个推荐模型的性能,并降低了计算成本。其具体实施过程如下:
30.s1.利用协同过滤技术分别预训练大规模教师模型t、中等规模缓冲模型b以及小规模学生模型s;
31.s2.用二进制训练集和教师模型输出的监督知识联合训练缓冲模型,该监督知识是通过带有tanh饱和激活函数的过滤器筛选的;
32.具体的,如图2所示,本实例将缓冲模型视为另一个小型的监督模型来缩小教师模型和学生模型之间巨大的排名差异。利用二进制u-i交互矩阵以及教师模型的知识同时训练缓冲模型。缓冲模型的训练方法如下:
[0033][0034]
其中,θ
*
表示参数;表示任何推荐器的协同过滤损失。是本技术提出的msd损失。超参数λ
t
→b是用于控制msd损失的权重。
[0035]
s3.用二进制训练集和缓冲模型输出的监督知识联合训练学生模型,该监督知识是通过带有sigmoid饱和激活函数的过滤器筛选的;
[0036]
具体的,如图2所示,学生模型可以利用缓冲模型作为桥梁来更好地模拟教师模型的输出。学生模型的训练方法如下:
[0037][0038]
其中,θ
*
表示参数。表示任何推荐器的协同过滤损失。是本技术提出的msd损失。超参数λb→s是用于控制msd损失的权重。
[0039]
s4.用二进制训练集和学生模型输出的高置信度知识联合训练教师模型,该高置信度知识是通过带有exp函数的过滤器筛选的推荐排名列表里前k个项目的采样概率。
[0040]
具体的,教师模型可以通过选择学生模型有较高置信度的知识来进一步提高排名
能力。教师模型的训练方法如下:
[0041][0042]
其中,θ
*
表示参数。表示任何推荐器的协同过滤损失。是本技术提出的msd损失。超参数λs→
t
是用于控制msd损失的权重。
[0043]
s5.获取各推荐模型的蒸馏损失,方式如下:
[0044][0045][0046][0047]
其中,表示经典的二进制交叉熵损失,是用户通过过滤器选择的未交互项目集。推荐模型利用得分对未观察到的项目从高到低进行排序。其中,σ(
·
)为激活函数,z
ui
为logit,t为msd的温度。随着温度的升高,概率分布通常会变得更平缓。
[0048]
用户对未观察到的项目的潜在偏好由转移。在u-i矩阵中用户未观察到的项目只被标记为0,用户交互过的项目被标记为1。通过msd,学生模型可以进一步了解这些项目被大型教师模型预测的分值来实现性能提升。
[0049]
如图3所示,本实例提出了一个过滤器来确定哪些知识应该转移给下一个推荐器,同时为过滤器设计了一个采样策略,为每个推荐器设计不同的函数,以更好地决定哪些知识应该转移到另一个推荐器上。
[0050]
本发明实例设计了一个概率函数来确定哪些教师模型排名的项目应该被采样出来作为知识传递给缓冲模型,该函数的定义如下:
[0051][0052]
其中,表示教师模型和缓冲模型的排名差异,ξb(》0)是控制概率平稳性的超参数,a
∝
b表示a与b成正比。tanh(
·
)表示饱和函数,排名差异超过阈值的项目被几乎均匀地采样。
[0053]
为了缩小教师模型和学生模型之间巨大的排名能力差异,本发明实例设计了一个概率函数来确定哪些缓冲模型排名的项目应该被采样出来作为知识传递给学生模型,该函数的定义如下:
[0054][0055]
其中,表示缓冲模型和学生模型的排名差异,ξs(》0)是控制概率平稳性的超参数;sigmoid(
·
)表示饱和激活函数。
[0056]
学生模型排名很高的项目在教师模型中可能排名很低,因此本发明实例设计了一
个概率函数来确定哪些学生模型排名的项目应该被采样出来作为知识传递给教师模型,该函数的定义如下:
[0057][0058]
其中,表示学生模型和教师模型的排名差异,ξ
t
(》0)是控制概率平稳性的超参数。exp(
·
)表示指数函数。
[0059]
如图4所示,推荐模型更新排名列表示意图,每轮迭代都更新推荐列表需要大量的运算时间,不适用于在线推理任务,本发明实例设计每p个epoch更新每个模型的推荐列表,一般来说p的取值是20。
[0060]
如图5所示,本技术多阶知识蒸馏方法可以应用在任何推荐系统常用模型,如lightgcn,bpr,cdae,neumf等。
[0061]
本实施例设计了一个缓冲模型作为教师模型和学生模型之间知识传递的桥梁,提升学习模型的排名能力。同时设计了一个过滤器来筛选源推荐模型排名高的前k个项目,提升模型的在线推理速度。本发明实例不仅提升了学生模型的排名能力,使其能够运用到需要实时更新的推荐任务中,还提高了在线推理速度,给用户带来更好的交互体验。
[0062]
前述对本发明的具体示例性实施方案的描述是为了说明和例证的目的。这些描述并非想将本发明限定为所公开的精确形式,并且很显然,根据上述教导,可以进行很多改变和变化。对示例性实施例进行选择和描述的目的在于解释本发明的特定原理及其实际应用,从而使得本领域的技术人员能够实现并利用本发明的各种不同的示例性实施方案以及各种不同的选择和改变。本发明的范围意在由权利要求书及其等同形式所限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1