一种基于NIC-400交叉矩阵的异构多核处理器架构的制作方法
一种基于nic-400交叉矩阵的异构多核处理器架构
技术领域
1.本发明涉及异构多核处理器技术领域,尤其是指一种基于nic-400交叉矩阵的异构多核处理器架构。
背景技术:
2.随着多媒体应用、图像处理、虚拟现实、计算机视觉等新兴移动终端多媒体相关行业的快速发展,对系统级多媒体解决方案提出了更严苛的要求。处理事务的并行度致使异构多核的互联更为复杂,实时高性能并行计算对通信带宽和延迟的敏感度越来越大,异构多核处理器在先进制程结点的时序收敛愈发艰难。因此,对系统级多媒体的架构优化、并行计算和物理实现成为当今研究的热点。
3.系统级多媒体芯片集成了多种专用的处理器核,例如用于通用复杂逻辑运算的cpu、大规模并行计算的渲染架构gpu、视频编解码处理器vpu、多种显示格式处理器dpu,数据驱动的神经网络加速器npu以及专用的海量数据处理器单元dpu等等。可通过合适的总线架构释放各异构处理器核的性能以解决并行计算,通信带宽,系统功耗,访问延迟等等问题。
技术实现要素:
4.为此,本发明所要解决的技术问题在于克服当前系统级异构多核处理器的低效率并行事务处理、全局同步传输的高功耗、总线仲裁导致的低通信带宽等问题,提出了基于异步交叉矩阵的并行传输互联架构,以释放各异构核的最大效能,提高并行传输速率和交互延迟。
5.为解决上述技术问题,本发明的一种基于nic-400交叉矩阵的异构多核处理器架构,所述的架构包括各异构处理器核统一编址、异构核与nic-400异步通信以满足带宽需求、物理层实现和多节点并行计算,另外其中异构处理器由多个异构核组成,异构核分别为用于复杂计算的cpu内核、高吞吐率的并行计算单元gpu、支持多种视频解码单元vpu,以及支持多种格式的显示引擎dpu;所述的异构核具有不同的流水线结构、各异构核作为主机可独立完成运算,各异构核通过可拆分异步桥与互联网络通信;此外,其完全可配置性、无闭塞性、低延迟性和低功耗等特性,可以从体系结构的层面解决移动终端多媒体soc对ppa的需求。
6.在本发明的一个实施例中,所述的nic-400包括与网络接口一一对应的路由节点,且相邻两个节点之间连接有截止数据反馈的连接线,基于nic-400交叉矩阵的各异构核接口的位宽和频率可任意配置;以满足目标主机在更低的功耗和面积下实现高性能并行通信计算需求。
7.在本发明的一个实施例中,所述的nic-400交叉矩阵中各异构核接口采用全异步时钟设计,交叉矩阵具有多个可配的参数以满足系统对ppa的需求,根据各个主机所能执行的ot需求,可以任意调节全局id位宽以减少平均访存延迟;根据应用场景需求,各异构核接
口类型、时钟域以及接口的位宽均任意可配,此外各接口通道可独立插入寄存器片以满足时序和延迟的需求。
8.nic-400可以最大化高吞吐率应用的性能、最小化移动终端设备的功耗、并保证系统通信的服务质量。先进的qos-400根据不同的配置可以动态调节整个网络的通信事务,qvn-400qos虚拟网络可有效防止仲裁阻塞,tlx-400可降低路由阻塞并很容易实现长路径的时序收敛。
9.在本发明的一个实施例中,所述异步桥是基于握手形式的可拆分结构集成,同时异步桥的主机侧和从机侧均具有各时钟域的fifo,axi接口的五个通道分别具有独立的fifo,每个fifo的宽度为当前通道所有信号位宽的总和;利用该fifo可完成大批量数据的可靠性传送,以满足异构核的高带宽并行计算需求。
10.在本发明的一个实施例中,所述异构核中cpu与gpu之间采用共享内存的方式,可有效降低异构内核之间的通信开销;两种内核的频繁访存会在系统内存控制器处形成阻塞,基于两种内核对延迟和带宽需求的差异,具有qvn-400和qos-400功能的nic-400可有效解决这些问题。
11.在本发明的一个实施例中,所述的异构处理器中的任意接口带宽可扩展的nic-400;gpu进行大量特征相似性的并行计算,cpu完成更多的通用事务和更复杂逻辑的高性能计算,可扩展的nic-400 提高异构多核系统的并行计算性能和并发事务处理能力,灵活配置成多级总线架构以减少访存延迟。
12.在本发明的一个实施例中,所述的nic-400交叉矩阵内采用具有不同时钟域和可配数据宽度的 switch和bridge,以满足主机的性能需求,采用层次化的时钟门控技术可有效降低空闲时钟域主机的功耗;此外,连接多个主机的switch可拆分成小的switch以提高频率并缩减关键路径的延迟。
13.在本发明的一个实施例中,所述nic-400具有系统级特性的,且可完成系统架构的自动优化,以及通过gpv可动态实现nic-400的参数配置;以满足实际的带宽或性能需求,thin-link可以解决物理实现时的布线拥堵问题。
14.在本发明的一个实施例中,所述nic-400也具有ip套件可通过内置算法,评估和优化子系统或子模块的面积和主机访问从机的延时。
15.本发明的上述技术方案相比现有技术具有以下优点:本发明所述的基于nic-400交叉矩阵的异构多核处理器架构,通过合适的总线架构释放各异构处理器核的性能以优化效能,提高并行传输速率和交互延迟,可使异构核与交叉矩阵接口变的更加简单,布线简单高效更有利于实现物理时序收敛。
附图说明
16.为了使本发明的内容更容易被清楚的理解,下面根据本发明的具体实施例并结合附图,对本发明作进一步详细的说明。
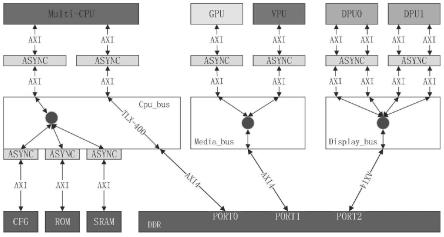
17.图1是本发明的基于nic架构的异构多核处理器架构示意图;
18.图2是本发明基于nic-400交叉矩阵的处理器总线拓扑示意图;
19.图3是本发明所述各类型主机的qos策略示意图;
20.图4是本发明所述各类型主机的qvn策略示意图。
具体实施方式
21.如图1所示,本实施例提供一种基于nic-400交叉矩阵的异构多核处理器架构,所述的架构包括各异构处理器核统一编址、异构核与nic-400异步通信以满足带宽需求、物理层实现和多节点并行计算,另外其中异构处理器由多个异构核组成,异构核分别为用于复杂计算的cpu内核、高吞吐率的并行计算单元gpu、支持多种视频解码单元vpu,以及支持多种格式的显示引擎dpu;所述的异构核具有不同的流水线结构、各异构核作为主机可独立完成运算,各异构核通过可拆分异步桥与互联网络通信。
22.基于异步corelink-nic400交叉矩阵的系统级异构多核处理器架构,该交叉矩阵的各主机接口参数完全独立配置,并采用异步通信的方式以便物理实现;为了满足各异构核的带宽和访存延迟,cpu 单独占有处理器总线,gpu和vpu占用多媒体总线,而实时性主机dpu单独占显示总线。
23.而进一步地,如图1所示,cpu为64axi3@667mhz接口,处理器总线上搭载的rom用于cpu启动一级boot,sram作为cpu应用程序的变量缓存或栈空间,提高cpu启动的速度,rom和sram均为支持多个ot的axi3接口,以提高指令和数据的并行性。
24.gpu和vpu分别为128axi4@500mhz和250mhz的接口,该贪婪型主机同时占用音视频总线,而从机侧只有一个ddr,该策略以满足gpu和vpu对通信带宽和低访存延迟的需求。
25.dpu为64axi4@250mhz的接口,为了满足dpu的实时性,dpu单独占用显示总线,从机侧只有一个ddr,满足dpu的实时性和带宽需求。
26.如图2所示,异构多核处理器总线架构的拓扑结构,其中各axi接口均可配置,处理器总线采用同步设计只有一个全局时钟。主机接口配置读写发射事务分别为10和22,qos优先级类型为主机控制和非锁定传输,qos策略采用trr和lr的仲裁策略。可以插入寄存器片以解决时序问题,该配置视情况而定。此外,访问ddr的主机接口采用thinlinks连接,switch的接口类型为axi。
27.异构多核处理器中的多媒体总线和显示总线可以参考处理器总线的配置方式,其中多媒体总线主机接口的qos优先级类型为主机控制和非锁定传输,qos策略采用ott策略。其中switch的结构参考图1。显示总线的主机接口的qos优先级类型为主机控制和非锁定传输,qos策略采用lr仲裁策略。
28.配置全局id和优化选项从而得到最优的总线架构。启动rtlvalidation完成对rtl代码的校验和配置参数的准确性。
29.各异构处理器核通过fifo深度可调节的异步桥与交叉矩阵总线的主机接口互联,fifo将该通道的所有信号重组并同一时刻发送到主机接口,主机接口处的fifo再将信号打散以完成通道信息的可靠性传输。时钟门控、动态电压和频率调节可根据需求有效降低功耗。
30.采用互锁的双向通信异步桥,握手信号的宽度依据传输情况自动调节,主机侧与从机侧没有公共时钟基准,不需要异构核和交叉矩阵具有严格的时序关系。该异步桥可有效匹配异构核和交叉矩阵总线的带宽,可拆分的特性可使异构核与交叉矩阵接口变的更加简单,布线简单高效更有利于实现物理时序收敛。
31.nic-400交叉矩阵总线可兼容多种amba协议总线接口的主机和从机,主机接口通过多级switch 与从机接口连接,该策略可有效减少主机与从机的通信线路。互连线的减少
可有效提高总线频率并解决带宽问题,整体性能更能满足异构多核的应用需求。
32.如图3所示,列出了各类型主机的优先级策略和qos值,根据该表配置各主机接口的仲裁策略以满足各主机的带宽、延迟等需求。
33.如图4所示,配置各主机接口的qvn特性,每个接口配置一个虚拟网络,并配置为预分配令牌的策略,以保证每个事务均会被从机接收。配置qvn防止共享switch处出现事务阻塞。
34.配置先进的质量服务qos和虚拟网络qvn-400高效管理数据传输,以满足主机的可接受的带宽和延迟约束。cpu属于延迟敏感型主机、gpu属于交易事务型主机、dpu显示相关的主机属于实时性主机。因此qos调制策略首先确保实时性主机的延迟最小,之后延迟敏感型主机的延迟最小,最后为事务交易型主机分配带宽。
35.cpu接口采用trr和lr策略以保证ot传输的数量并减少事务延迟。gpu接口采用ott策略以保证同步ot传输的数量并防止事务阻塞。实时性dpu接口采用lr策略以保证事务交易的实时性。qos 的优先级值来源于主机事务辅助信息,通常dpu等实时显示相关的qos值最高,ot事务繁多的gpu 等主机的qos值最小,cpu的qos处于中间状态。
36.qvn虚拟网络防止接口阻塞以确保每个交易事务都能被接收,每个主机发送的事务必须获得相应从机的令牌。每个主机均采用预分配令牌的配置。
37.而进一步,通用处理器采用具有多媒体加速单元的对称多核架构,该架构提高事务并行处理能力和性能的同时,功耗也得到有效的下降。为了发挥通用处理器的最佳性能,分离的l1cache均采用 32kb的组关联映射结构,以及1mb的用于多核共享缓存的l2cache。配置加速器一致性端口以维持各核心的高速缓存一致性。此外,通过该端口可与其他模块共享高速缓存内容,并支持所有标准的读写,无需额外一致性功能模块,在不增加功耗的情况下,提升多核处理器的整体性能。
38.通用处理器的多媒体加速单元neon可以辅助视频编解码单元vpu完成多种编码标准的快速解码操作,neon将复杂视频编解码器的性能提高60~150%。
39.neon的时钟和供电均可单独门控,从而在整体上节约了大量的动态和静态功耗。
40.采用深度任务划分和调度来隐藏通用处理器与异构核的通信开销。将子线程进一步拆分,一部分子任务由通用处理器cpu执行,一部分子任务由其他异构核执。cpu负责任务调度,而其他异构核负责加速运算,因此可将数据相关度很大的gpu、vpu和数据采集设备置于同一总线以减少互访延迟。
41.主从接口的增多会导致扇出、电容和走线的增加,从而必须通过插入寄存器来提高总线频率。在不降低主机ot访问数量的前提下,访问延迟会急剧增加。因此,nic-400交叉矩阵采用单级switch 串联的2x4的交叉矩阵配置。
42.nic-400交叉矩阵时钟同步,各master和slave接口均采用异步桥解耦连接,ddr控制器与交叉矩阵同步设计以提高通信带宽并减少访存延迟。接口的位宽配置为128bits,cpu内核总线的频率为667mhz以满足ddr的频率需求。
43.显然,上述实施例仅仅是为清楚地说明所作的举例,并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引申出的显而易见的变化或变动仍处于本发明创造的保护范围之中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1