一种基于结构可重参数化的轻量级视频行为识别方法
1.本发明涉及一种基于结构可重参数化的轻量级视频行为识别方法,属于计算机人工智能学科技术领域。
背景技术:
2.视频行为识别是通过对一段视频片段进行分析从而得到视频中人物的动作行为,在安防监控、驾驶员或乘客行为识别、短视频审核等具有广泛的应用前景。
3.使用3d卷积能够有效的捕捉到时间维度和空间维度的信息,但直接基于3d卷积的视频行为识别网络(d.tran,l.bourdev,r.fergus,l.torresani and m.paluri.learning spatiotemporal features with 3d convolutional networks.proceedings of the ieee international conference on computer vision(iccv).2015:4489-4497.)往往会造成参数量大和浮点计算量高等问题,无法直接在算力受限的边缘设备上应用与普及。
4.为了解决上述问题,使用直接基于轻量化网络扩展而来的3d结构网络模型虽然拥有较小的参数量和计算量,然而精度损失严重,基于slowfast的视频行为识别网络通过快慢双分支通道提取视频帧中的运动信息和背景信息,虽然一定程度上减小了模型的大小,但最终的模型仍然相对较为臃肿,难以直接部署和使用,这就限制了基于3d卷积的视频行为识别的使用与普及。
技术实现要素:
5.为了解决目前的视频行为识别方法无法同时保证精度和计算效率的问题,本发明提供了一种基于结构可重参数化的轻量级视频行为识别方法,所述技术方案如下:
6.本发明的第一个目的在于提供一种轻量级视频行为识别方法,包括以下步骤:
7.步骤一:获取待识别的行为视频;
8.步骤二:对所述待识别的行为视频进行预处理,得到行为图像序列;
9.步骤三:将所述行为图像序列输入基于结构可重参数化的轻量级视频行为识别网络;
10.步骤四:所述基于结构可重参数化的轻量级视频行为识别网络对所述行为图像序列进行计算并输出行为识别结果。
11.可选的,所述基于结构可重参数化的轻量级视频行为识别网络的构建过程包括:
12.步骤1:将dbb模块结构扩展为3d结构,即使用3d卷积替换原2d卷积,使用2d池化操作替换原2d池化操作,构建3d-dbb模块;
13.步骤2:使用所述3d-dbb模块构建结构可重参数化的深度卷积,即3d-dbb-depthwise模块;
14.步骤3:使用所述3d-dbb模块构建结构可重参数化的逐点卷积,即3d-dbb-pointwise模块;
15.步骤4:将所述3d-dbb-depthwise模块和3d-dbb-pointwise模块进行堆叠,构建结
构可重参数化的深度可分离卷积,即dp3dbb模块;
16.步骤5:以轻量级网络为骨干网络,将所述轻量级网络中的深度可分离卷积替换为所述dp3dbb模块。
17.可选的,所述步骤5中的轻量级网络包括:mobilenet系列网络和/或shufflenet系列网络。
18.可选的,所述步骤5中的替换方式为:将所述shufflenet系列网络的基本模块和下采样模型的两分支各看作一个整体,将分支路上含深度可分离结构直接替换为仅含有一个所述dp3dbb模块的分支结构。
19.可选的,所述步骤5中的替换方式为:将所述shufflenet系列网络的基本模块和下采样模型的两分支上的每个单元看作一个独立的个体,即每个单元均替换成所述dp3dbb模块。
20.可选的,所述3d-dbb模块的激活函数为hardswish激活函数。
21.可选的,所述步骤二中对所述待识别的行为视频进行预处理的过程包括:归一化、随机裁剪、分辨率调整。
22.可选的,所述分辨率调整为224x 224。
23.本发明的第二个目的在于提供一种视频行为识别系统,包括:
24.视频获取模块,用于采集待识别的行为视频;
25.视频预处理模块,用于对采集的行为视频进行处理并输出行为图像序列;
26.上述的基于结构可重参数化的轻量级视频行为识别网络,用于对所述行为图像序列进行计算;
27.输出显示模块,用于根据所述基于结构可重参数化的轻量级视频行为识别网络的计算结果输出行为识别结果。
28.可选的,视频行为识别系统还包括报警装置,用于根据行为识别结果发出警报信号。
29.本发明有益效果是:
30.本发明的轻量级视频行为识别方法,基于3d卷积结构的轻量化问题,利用3d结构的重参数化使得网络能够继续使用3d卷积能够提取时空上的特征的优点,并且在经过重参数化后仍能达到轻量化网络模型的目的,最终能够以较小的参数量和计算量去部署模型和进行模型推理,即以较大的参数量去训练网络,在推理时以较小的模型进行推理并保证模型精度不会下降。3d结构的重参数化设计达到了轻量化了3d网络模型的目的并保持模型的精度不会过分丢失。
31.利用本发明构建的轻量级网络进行视频行为识别,不仅可以提升识别效率,且同时保证了识别精度。
附图说明
32.为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
33.图1是本发明的3d-dbb模块结构图。
34.图2是本发明的3d-dbb-depthwise模块结构图;
35.图3是本发明的3d-dbb-pointwise模块结构图;
36.图4是本发明的dp3dbb模块结构图。
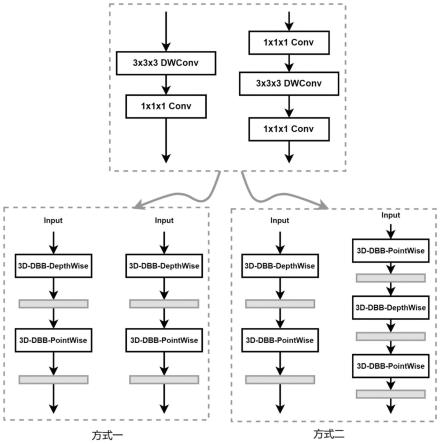
37.图5是本发明的两种不同的深度可分离卷积替换方式结构图。
38.图6是本发明的shuffledbbv1的基础模块结构替换设计图。
39.图7是本发明的shuffledbbv1的下采样模块结构替换设计图。
40.图8是本发明的shuffledbbv2基础模块和下采样模型结构替换设计图。
具体实施方式
41.为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。
42.实施例一:
43.本实施例提供一种轻量级视频行为识别方法,包括:
44.步骤一:获取待识别的行为视频;
45.步骤二:对所述待识别的行为视频进行预处理,得到行为图像序列;
46.步骤三:将所述行为图像序列输入基于结构可重参数化的轻量级视频行为识别网络;
47.步骤四:所述基于结构可重参数化的轻量级视频行为识别网络对所述行为图像序列进行计算并输出行为识别结果。
48.实施例二:以3d-shufflenetv2为骨干网络,使用第一种替换方式替换深度可分离结构本实施例提供一种轻量级视频行为识别方法,包括:
49.步骤一:获取待识别的行为视频;
50.可采用摄像头采集实时视频,或者采用现有的包含行为的视频。
51.步骤二:对待识别的行为视频进行预处理,得到行为图像序列,预处理的过程主要包括:抽取视频帧,对视频帧进行归一化、随机裁剪等操作,获得行为图像序列,本实施例将输入图像序列的分辨率控制在224x 224。
52.步骤三:将所述行为图像序列输入基于结构可重参数化的轻量级视频行为识别网络;
53.该识别网络的构建过程如下:
54.步骤1:为了适用于视频行为识别这种带有时间序列维度的数据,本实施例将dbb(diverse branch block)结构通过膨胀的方式,即使用3d卷积替换原2d卷积,使用2d池化操作替换原2d池化操作,从而能够提取到时空维度上的特征,使其能够适用于基于三维卷积的任务当中,膨胀后得到的3d-dbb模块结构如图1所示。
55.步骤2:使用3d-dbb模块构建结构可重参数化的深度卷积,并命名为3d-dbb-depthwise模块,模块结构如图2所示,将标准的3d-dbb模块中的各个卷积进行分组,从而模拟出标准深度可分离卷积的核心对卷积进行分组卷积,达到减少参数量和计算量的目的。
56.步骤3:使用步骤1所提出的3d-dbb模块构建结构可重参数化的逐点卷积,并命名为3d-dbb-pointwise模块,模块结构如图3所示,即将标准的3d-dbb模块中所有的3x3x3卷
积全部使用1x1x1卷积进行替换,从而模拟标准深度可分离卷积的逐点卷积的效果。
57.步骤4:将步骤二的3d-dbb-depthwise模块和3d-dbb-pointwise模块进行堆叠,构建结构可重参数化的深度可分离卷积,即dp3dbb模块,dp3dbb结构如图4所示。
58.步骤5:以3d-shufflenetv2为骨干网络,使用替换方式一构建结构可重参数化的轻量级shuffledbbv1网络,替换方式一如图5所示,将3d-shufflenetv2的基本模块和下采样模型的两分支各看作一个整体,将分支路上含深度可分离结构直接替换为仅含有一个dp3dbb结构分支结构。初始3d-shufflenetv2的基本模块和下采样分别如图6(a)和图7(a)所示,采用方式一直接使用dp3dbb模块替换掉原分支路上含有深度可分离结构的卷积结构,替换后的基础模块和下采样模块结构分别如图6(b)和图7(b)所示,将其进行结构重参数化后,最终推理结构的基础模块和下采样模块分别如图6(c)和图7(c)所示。
59.步骤6:训练和测试基于结构可重参数化和轻量化网络相结合的网络模型,在训练时,使用结构重参数化前的网络进行训练,在推理测试时,使用结构重参数化后的网络进行推理测试。
60.步骤6.1:使用egogesture、jester和ucf-101三个视频行为数据集进行测试改进的模型的有效性,对数据集的视频数据集进行抽取视频帧操作。
61.步骤6.2:对视频帧进行预处理操作,如归一化、随机裁剪等。将输入图像序列的分辨率控制在224x 224。
62.步骤6.3:将经过预处理操作的连续16帧视频帧序列输入给网络模型,进行模型训练。通过网络的前向计算,以及损失函数计算网络误差,并将该误差反向传播,计算网络每一层权重的误差梯度,并进行权值更新,逐渐缩小网络误差值。不断循环执行上述过程,寻找最有效的网络训练参数,使得网络损失降低至最小即完成网络的训练过程,获得网络模型,此过程可以简单概括为参数寻优。
63.步骤6.4:测试并计算网络模型重参数化之前和之后的参数量、浮点计算量、以及在gpu和cpu上的推理延迟。
64.步骤四:所述基于结构可重参数化的轻量级视频行为识别网络对所述行为图像序列进行计算并输出行为识别结果。
65.实施例三:以3d-shufflenetv2为骨干网络,使用第二种替换方式替换深度可分离结构本实施例提供一种轻量级视频行为识别方法,包括:
66.实施步骤与实施例二基本相同,仅步骤5替换方式不同,实施例三步骤5具体替换方式如下:
67.以3d-shufflenetv2为骨干网络,使用替换方式二构建结构可重参数化的轻量级shuffledbbv2网络,替换方式二如图5所示,将shufflenetv2的基本模块和下采样模型的两分支上的每个单元看作一个独立的个体,即每个单元均替换成对应的3d-dbb模块结构。替换过程如图8所示,其中图8(a)是原shufflenet的基本模块,(b)是方式二替换后的结构重参数化后的下采样模块,(c)是原shufflenet的下采样模型,(d)是方式二替换后的结构重参数化后的下采样模块。
68.实施例四:以3d-mobilenetv1为骨干网络
69.本实施例提供一种轻量级视频行为识别方法,包括:
70.实施步骤与实施例二基本相同,仅步骤5替换方式不同,实施例三步骤5具体替换
方式如下:
71.以3d-mobilenetv1为骨干网络,使用dp3dbb模块替换3d-mobilenetv1网络中的深度可分离结构。具体的网络结构如表1所示。
72.表1mobilev1dbb网络结构
[0073][0074]
为了证明本发明的有益效果,进行了全面的对比实验,将本发明的视频行为方法与直接基于轻量化网络扩展而来的轻量级视频行为识别方法以及先进的视频行为识别网络进行了比较,实验数据如表2和表3所示,其中表1是本实施例与经典视频行为识别网络已经直接基于轻量级网络扩展而来的网络模型的参数量、浮点计算量、在egogesture、jester和ucf-101数据集上的准确率,以及在cpu和gpu上的推理延迟对比数据。表2是本实施例与先进的视频行为识别网络的在使用预训练模型后在egogesture数据集上的准确率对比。
[0075]
表2各个视频行为识别模型的参数量、浮点计算量、在egogesture、jester和ucf-101数据集上的准确率,以及在cpu和gpu上的推理延迟
[0076][0077]
表3使用预训练模型后在egogesture数据集上的结果对比
[0078][0079]
由表2的数据可以看出,本发明与经典视频行为识别网络以及直接基于轻量化网络扩展而来的网络相比,准确率显著提高,并且在经过重参数化后,速度可以与直接基于轻量化网络扩展而来的视频行为识别网络相媲美。由表3数据可以看出,本实施例在参数量仅为resnext-101网络1/50的情况下,准确率仅下降0.42%。
[0080]
综上所述,本发明的轻量级视频行为识别方法,基于3d卷积结构的轻量化问题,利用3d结构的重参数化使得网络能够继续使用3d卷积能够提取时空上的特征的优点,并且在经过重参数化后仍能达到轻量化网络模型的目的,最终能够以较小的参数量和计算量去部署模型和进行模型推理,即以较大的参数量去训练网络,在推理时以较小的模型进行推理并保证模型精度不会下降。3d结构的重参数化设计达到了轻量化了3d网络模型的目的并保持模型的精度不会过分丢失。
[0081]
本发明实施例中的部分步骤,可以利用软件实现,相应的软件程序可以存储在可读取的存储介质中,如光盘或硬盘等。
[0082]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1