一种基于数据耦合微特征相关性分析的质量缺陷预测方法
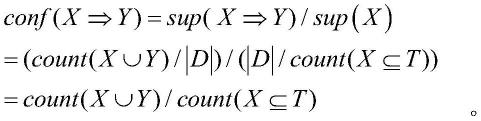
1.本发明属于制造过程质量预测控制技术领域,具体涉及一种基于数据耦合微特征相关性分析的质量缺陷预测方法。
背景技术:
2.制造过程中的各项特性总是波动的,为了满足人们的需求,需要使其在人们能接受的范围内波动。系统因素和偶然因素给各类质量特性数据带来波动,后者往往是背离制造过程设计初衷的,也是造成质量缺陷的原因。在当下各类传感器与数据库系统的广泛应用的条件下,综合多元的质量特性耦合数据进行质量缺陷分析成为可能。同时,由于制造过程的时序性,借助质量预测模型,在制造过程中对可能出现的质量缺陷进行预防能有效降低制造成本。对导致质量缺陷的因素进行有效解耦,构建质量缺陷预测模型,使用关键质量特性参数进行实时预测,能有效地实现制造质量控制。
3.针对质量缺陷分析手段,有结合以控制图为代表的spc手段形成和控制图模式识别方法,有以神经网络判断质量缺陷的方法,有基于ga进行质量缺陷关联规则提取的方法,有结合模糊推理与stateflow进行质量缺陷分析的方法,有综合cbr(case based reasoning)与knn(k-nearest neighbor algorithm)算法推测案例的相似性度量,运用案例库进行质量诊断的方法。但较多研究都集中在最终特征输出,模型的解释性较差,不利于质量解耦,其中以神经网络方法尤甚。针对预测模型,已有如贝叶斯网络、随机森林、lgbm(light gradient boost machine)、多层感知机、rnn(recurrent neural network)、深度神经网络等较为广泛适用的模型,但对于数据的模糊性的处理效果不是很好,而若结合模糊理论进行处理,发现在实际试验过程中可能会产生过多的模糊区间,降低算法效率。
技术实现要素:
4.为解决上述技术问题,本发明提出了一种基于数据耦合微特征相关性分析的质量缺陷预测方法。
5.本发明采用的技术方案为:一种基于数据耦合微特征相关性分析的质量缺陷预测方法,具体步骤如下:
6.s1、构建数据耦合微特征相关性分析方法,对质量特性耦合数据进行区间划分并识别质量特性耦合数据间的关联关系,通过置信阈值高低,从高频微特征项集里面提取显著缺陷特征数据;
7.s2、搭建基于耦合数据微特征相关性规则的制造过程质量缺陷预测模型,完成对质量缺陷的预测。
8.进一步地,所述步骤s1中,具体如下:
9.初始化k个点μ={μ1,μ2,
…
,μk}作为类中心。
10.对于每一个质量缺陷耦合数据微特征样例i,计算其应该属于的特征类,定义损失函数:
[0011][0012]
其中,c表示类集合,μ表示集合中心点,xi表示第i个样本,ci表示xi所属的类,μ
ci
表示类对应中心点,n表示样本总数。
[0013]
对于每一个样本xi,将其分配到距离最近的中心所属的类:
[0014][0015]
其中,表示第t次迭代的第i类,表示第t次迭代的第k中心点。
[0016]
对于每一个中心点μi,迭代计算该类的微特征核心值
[0017][0018]
其中,μ表示集合中心点。
[0019]
在质量特性耦合数据有k个区间的情况下,多次迭代下到特征核心值稳定在小范围内。
[0020]
在确定质量特性耦合数据微特征区间后,确定微特征相关性的支持域值与置信域值。依据支持域值产生与强相关规则依据置信域值生成微特征高频项集。
[0021]
支持域值由某项集x的微特征模式数与微特征模式数据库d总数比计算,计算式为:
[0022][0023]
其中,t表示目标模式数。
[0024]
最小支持域值是微特征规则项集中的设置的最小支持阈值,记为sup_min,支持域值大于等于sup_min的项集叫做微特征高频项集。
[0025]
通过置信域值发现强关联规则,其含义是同时包含项集x与y的微特征模式数与只包含x的微特征模式数的比率,其计算表达式为:
[0026][0027]
进一步地,所述步骤s1中,质量耦合数据微特征相关性规则分析任务中,具体如下:
[0028]
产生高频模式项集:对于所有达到最小支持度阈值要求的微特征项集,提取这些微特征项集,并且称这些项集为高频微特征项集。
[0029]
产生微特征强相关规则:根据置信阈值高低,从高频微特征项集里面提取规则。
[0030]
进一步地,所述步骤s2中,具体如下:
[0031]
将耦合数据微特征样本数据映射到多维空间,并进行回归,从而拟合出一个连续函数,即模型函数f(x)=wx+b,表示样本点(x,y)在法向量w,偏移量b的线性面上,以线性函数为中心,其两侧定义“微距区域”,位置在微距区域内的样本,不考虑模糊异常区间;而位置在微距区域之外的,则成为模糊异常区间函数中一员,最后,通过最小化微距区域的宽
度,将模糊异常区间降到最低,从而建立最优化预测模型。
[0032]
引入两隔离变量ξ(正微距区偏移常数)与ξ*(负微距区偏移常数)使模型对样本点有一定清晰度。
[0033]
其中,f(x)=wx+b是最终要求得的模型函数;f(x)+ε与f(x)-ε表示微距区域的上下界限,ε表示模糊异常区间系数。
[0034]
可用公式表述为:
[0035][0036][0037]
其中,ξi表示第i个样本对应的正微距区偏移常数;yi表示第i个样本对应的y轴向量;表示第i个样本对应的负微距区偏移常数。
[0038]
对于任意样本xi,如果它在微距区域里面或者在微距区域界限上,则ξ与ξ
*
都为0;如果它在微距区域上界限上方,则ξ》0,ξ
*
=0;如果它在微距区域下界限下方,则ξ=0,ξ
*
》0。
[0039]
最优化预测问题的数学描述可以表示为:
[0040][0041]
f(xi)-yi≤ε+ξi;
[0042][0043][0044]
其中,关键质量特性耦合数据微特征相关性规则构造输入向量,以制造质量为输出,对质量预测模型进行训练。训练过程使用ga对超参数进行优化,优化参数为质量预测模型的相关性系数c和模糊异常区间系数ε。
[0045]
本发明的有益效果:本发明的方法通过构建数据耦合微特征相关性分析方法,对质量特性耦合数据进行区间划分并识别质量特性耦合数据间的关联关系,通过置信阈值高低,提取显著缺陷特征数据,搭建基于耦合数据微特征相关性规则的制造过程质量缺陷预测模型,完成对质量缺陷的预测。本发明的方法能够实时预测制造质量,对导致输出质量缺陷的关键质量特性数据和对该质量特性有影响作用的制造过程多元输入参数进行分析与预测,利于多元质量特性耦合数据进行质量解耦,发现质量缺陷形成机理,进行多链溯源,具有较好的成因解释性,能有效解决质量特性耦合数据区间划分以及模糊算法在小值域上产生过多的模糊区间的问题。
附图说明
[0046]
图1为本发明的一种基于数据耦合微特征相关性分析的质量缺陷预测方法的流程图。
[0047]
图2为本发明实施例中基于耦合数据微特征相关性规则的质量缺陷预测模型构建图。
[0048]
图3为本发明实施例中模具温度、熔融温度和注射时间的聚类图。
[0049]
图4为本发明实施例中保压时间和保压温度聚类图。
[0050]
图5为本发明实施例中ga-mfccd与ga-elm对比图。
具体实施方式
[0051]
下面结合附图与实施例对本发明作进一步的说明。
[0052]
首先在实施例1中,如图1所示,本发明的一种基于数据耦合微特征相关性分析的质量缺陷预测方法流程图,具体步骤如下:
[0053]
s1、构建数据耦合微特征相关性分析方法,对质量特性耦合数据进行区间划分并识别质量特性耦合数据间的关联关系,通过置信阈值高低,从高频微特征项集里面提取显著缺陷特征数据;
[0054]
s2、搭建基于耦合数据微特征相关性规则的制造过程质量缺陷预测模型,完成对质量缺陷的预测。
[0055]
在本实施例中,所述步骤s1中,具体如下:
[0056]
初始化k个点μ={μ1,μ2,
…
,μk}作为类中心。
[0057]
对于每一个质量缺陷耦合数据微特征样例i,计算其应该属于的特征类,定义损失函数:
[0058][0059]
其中,c表示类集合,μ表示集合中心点,xi表示第i个样本,ci表示xi所属的类,表示类对应中心点,n表示样本总数。
[0060]
对于每一个样本xi,将其分配到距离最近的中心所属的类:
[0061][0062]
其中,表示第t次迭代的第i类,表示第t次迭代的第k中心点。
[0063]
对于每一个中心点μi,迭代计算该类的微特征核心值
[0064][0065]
其中,μ表示集合中心点。
[0066]
在质量特性耦合数据有k个区间的情况下,多次迭代下到特征核心值稳定在小范围内。
[0067]
在确定质量特性耦合数据微特征区间后,确定微特征相关性的支持域值(support)与置信域值(confidence)。依据支持域值产生与强相关规则(strong rule)依据置信域值生成微特征高频项集(frequent itemset)。
[0068]
支持域值由某项集x的微特征模式数与微特征模式数据库d总数比计算,计算式为:
[0069][0070]
其中,t表示目标模式数。
[0071]
最小支持域值是微特征规则项集中的设置的最小支持阈值,记为sup_min,支持域值大于等于sup_min的项集叫做微特征高频项集。
[0072]
通过置信域值发现强关联规则,其含义是同时包含项集x与y的微特征模式数与只包含x的微特征模式数的比率,其计算表达式为:
[0073][0074]
在本实施例中,所述步骤s1中,质量耦合数据微特征相关性规则分析任务中,具体如下:
[0075]
产生高频模式项集:对于所有达到最小支持度阈值要求的微特征项集,提取这些微特征项集,并且称这些项集为高频微特征项集。
[0076]
产生微特征强相关规则:根据置信阈值高低,从高频微特征项集里面提取规则。
[0077]
在本实施例中,所述步骤s2中,具体如下:
[0078]
如图2所示,w表示w的向量形式,将耦合数据微特征样本数据映射到多维空间,并进行回归,从而拟合出一个连续函数,即模型函数f(x)=wx+b,表示样本点(x,y)在法向量w,偏移量b的线性面上,以线性函数为中心,其两侧定义“微距区域”,位置在微距区域内的样本,不考虑模糊异常区间;而位置在微距区域之外的,则成为模糊异常区间函数中一员,最后,通过最小化微距区域的宽度,将模糊异常区间降到最低,从而建立最优化预测模型。
[0079]
由于质量耦合数据模糊相关性使得微特征模式样本点位置都在微距区域内,为进一步区间清晰化,引入两隔离变量ξ(正微距区偏移常数)与ξ
*
(负微距区偏移常数)使模型对样本点有一定清晰度。
[0080]
其中,f(x)=wx+b表示最终要求得的模型函数;f(x)+ε与f(x)-ε表示微距区域的上下界限;ε表示模糊异常区间系数;
[0081]
可用公式表述为:
[0082][0083][0084]
其中,ξi表示第i个样本对应的正微距区偏移常数;yi表示第i个样本对应的y轴向量;表示第i个样本对应的负微距区偏移常数;
[0085]
对于任意样本xi,如果它在微距区域里面或者在微距区域界限上,则ξ与ξ
*
都为0;如果它在微距区域上界限上方,则ξ》0,ξ
*
=0;如果它在微距区域下界限下方,则ξ=0,ξ
*
》0。
[0086]
最优化预测问题的数学描述可以表示为:
[0087][0088]
f(xi)-yi≤ε+ξi;
[0089]
[0090][0091]
其中,关键质量特性耦合数据微特征相关性规则构造输入向量,以制造质量为输出,对质量预测模型进行训练。训练过程使用ga(genetic algorithm)对超参数进行优化,优化参数为质量预测模型的相关性系数c和糊异常区间系数ε。
[0092]
本发明还提供了实施例2,对注塑过程中质量缺陷的分析,具体如下:
[0093]
塑料的注射成型过程中,事前要进行产品缺陷分析,产品质量监测,以及及时改良产品的参数,以满足企业的质量要求。
[0094]
根据实际注塑生产经验反馈,以下五个是影响注塑过程质量的关键参数:模具温度t1(℃),熔体温度t2(℃),注射时间s1(s),保压时间s2(s),保压压力p(%)。采用高密度聚乙烯hdpe(high-density polyethylene)作为实验材料,部分原始数据如表1所示:
[0095]
表1
[0096][0097]
如图3、图4所示,原数据包含有正常质量产品,出现凹陷产品,出现翘曲产品。因此根据耦合数据微特征相关性分析方法,将影响因素分别聚类可得到影响因素的大致分类。
[0098]
其中,图3中模具温度为x轴,熔体温度为y轴,注射时间数据分类为z轴;图4中保压时间为x轴,保压压力数据分类为y轴。
[0099]
由于该分类结果并非最适结果,因此基于后面算法的实现结果,进行了区间范围的调整,调整结果如表2:
[0100]
表2
[0101][0102]
由表2可知,共有12个数据区间,因此将数据区间表示如表3所示:
[0103]
表3
[0104][0105]
根据耦合数据微特征相关性分析方法,得到不同区间之间以及区间与最终质量结果之间的相关性关联规则,部分关联规则如表4所示:
[0106]
表4
[0107][0108]
因此根据耦合数据微特征相关性分析方法所得出的以上三条规则可知:
[0109]
(1)对于质量正常的产品来说,质量规则为:
[0110]
(20.1≤t1≤58.3)∩(123.0≤t2≤256.2)∩(0.21≤s1≤1.19)∩(3.1≤s2≤10.2)∩(61.3≤p≤78.1)
[0111]
(2)对于凹陷产品来说,质量规则为:
[0112]
(t1》62.1)∩(t2》273.3)∩(p《58.1)
[0113]
(3)对于翘曲产品来说,质量规则为:
[0114]
(t1》68.5)∩(s2》17.5)∩(p》84.4)
[0115]
因此,在注塑产品的生产过程中,要注意控制这些影响因素在合理范围内,从而实现高效率管理。
[0116]
不考虑干扰等偶然因素的情况下,选取生产过程中产生的100组数据作为训练集和测试集,进行过程质量的预测,并最终得出预测值。
[0117]
通过mfccd模型得出了预测结果以及与原数据相比的预测误差百分比。此处与ga进行了优化的隐含层自适应增长极端学习机(ga-elm)模型进行对比,对比具体如图5及表5所示:
[0118]
表5
[0119]
[0120]
rmse(root mean square error)为均方根误差,计算公式为:
[0121][0122]
其中,n表示样本总数,prediction表示预测值,target表示真实值。
[0123]
由图及表可知,ga-mfccd的预测误差相对较小。ga-mfccd方法预测结果中,最大误差为3.58%,最小为0.87%。总体而言,本发明的方法可以较为准确地预测出注塑凹陷直径。
[0124]
综上所述,本发明的方法通过构建数据耦合微特征相关性分析方法,对质量特性耦合数据进行区间划分并识别质量特性耦合数据间的关联关系,通过置信阈值高低,从高频微特征项集里面提取显著缺陷特征数据,搭建基于耦合数据微特征相关性规则的制造过程质量缺陷预测模型,完成对质量缺陷的预测。本发明的方法能够实时预测制造质量,对导致输出质量缺陷的关键质量特性数据和对该质量特性有影响作用的制造过程多元输入参数进行分析与预测,利于多元质量特性耦合数据进行质量解耦,发现质量缺陷形成机理,进行多链溯源,具有较好的成因解释性,能有效解决质量特性耦合数据区间划分以及模糊算法在小值域上产生过多的模糊区间的问题。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1