用户数据的处理方法、设备和计算机可读存储介质与流程
1.本技术涉及数据处理技术领域,尤其涉及一种用户数据的处理方法、数据处理设备和计算机可读存储介质。
背景技术:
2.用户在线情况分析是企业或单位战略分析的依据,对于企业或单位的决策起到关键的作用,比如,企业通过对观看视频节目的用户在线情况进行分析,以根据实时统计的用户在线数量判断出该视频节目的受欢迎程度,进而可根据受欢迎程度决定是否改变播放的时间和次数以及确定未来制作电视节目类型的方向等。在相关技术中,通过将采集的用户在线数据分配到各个分析模块,各个分析模块结合当前采集的用户在线数据与公共外部缓存库中记录的用户在线数据,确定当前时段的实时用户在线情况。然而,由于各个分析模块共用一个外部缓存库,在用户数据急剧增加时,会造成对外部缓存库的频繁读写,使得外部缓存无法支撑数据分析的要求,从而导致用户在线情况分析结果不准确。
3.上述内容仅用于辅助理解本发明的技术方案,并不代表承认上述内容是现有技术。
技术实现要素:
4.本技术实施例通过提供一种用户数据的处理方法、设备和计算机可读存储介质,旨在解决由于各个分析模块共用一个外部缓存库,在用户数据急剧增加时,会造成对外部缓存库的频繁读写,使得外部缓存无法支撑数据分析的要求,从而导致用户在线情况分析结果不准确的技术问题
5.为实现上述目的,本发明实施例提供一种用户数据的处理方法,所述用户数据的处理方法包括以下:
6.获取采集的用户在线数据;
7.根据所述用户在线数据的用户标识,确定所述用户在线数据对应的分析算子,并将所述用户在线数据发送至所述分析算子;
8.通过所述分析算子对接收到的所述用户在线数据进行数据处理,并根据处理结果更新所述缓存单元和实时在线数据库。
9.可选地,所述根据所述用户在线数据的用户标识,确定所述用户在线数据对应的分析算子,并将所述用户在线数据发送至所述分析算子的步骤包括:
10.根据所述用户在线数据的用户标识,确定所述用户在线数据对应的分析算子;
11.根据所述用户在线数据的上报时间确定所述用户在线数据所属的暂存队列,控制所述用户在线数据入队;
12.在所述暂存队列创建时间大于或者等于预设延时时长时,将所述暂存队列中的所述用户在线数据发送至所述分析算子。
13.可选地,所述通过所述分析算子对接收到的所述用户在线数据进行数据处理,并
根据处理结果更新所述缓存单元和实时在线数据库的步骤包括:
14.获取所述用户在线数据中的用户标识;
15.确定所述缓存单元中,在线用户集合对应的历史用户标识;
16.当不存在与所述用户标识相同的历史用户标识时,将所述用户标识对应的用户信息添加至所述缓存单元的在线用户集合,并更新所述缓存单元中的用户上线数量;
17.当存在与所述用户标识相同的历史用户标识时,忽略所述用户在线数据,或者根据所述用户在线数据更新所述历史用户标识关联的数据。
18.可选地,所述分析模块包括更新算子,所述通过所述分析算子对接收到的所述用户在线数据进行数据处理,并根据处理结果更新所述缓存单元和实时在线数据库的步骤之前,还包括:
19.获取所述缓存单元中保存的各个历史用户的下线时间;
20.当所述下线时间满足下线条件时,控制所述历史用户下线,并更新所述缓存单元保存的在线用户数据。
21.可选地,所述分析模块包括分析算子,所述通过所述分析算子对接收到的所述用户在线数据进行数据处理,并根据处理结果更新所述缓存单元和实时在线数据库的步骤,包括:
22.通过所述分析算子对接收到的所述用户在线数据进行数据处理,并根据处理结果更新所述缓存单元;
23.根据更新后的所述缓存单元中的数据确定历史用户在线数量、所述用户上线数量和用户下线数量;
24.根据所述历史用户在线数量和所述用户上线数量以及所述用户下线数量,确定当前时间的用户在线数量;
25.将所述用户在线数量更新至所述缓存单元,并基于所述分析算子将所述用户上线数量和所述用户下线数量以及所述用户在线数量更新至所述实时在线数据库,在终端展示。
26.可选地,所述用户在线数据分析系统包括查询模块,所述获取采集的用户在线数据的步骤之后,还包括:
27.对所述采集的用户在线数据进行数据清洗,并将数据清洗之后的所述用户在线数据实时更新至所述实时在线数据库。
28.可选地,所述用户在线分析系统包括查询模块,所述对所述采集的用户在线数据进行数据清洗,并将数据清洗之后的所述用户在线数据实时更新至所述实时在线数据库的步骤之后,包括:
29.通过所述查询模块接收查询指令;
30.根据所述查询指令确定所述实时在线数据库的实时用户在线数据,在终端展示。
31.可选地,所述用户在线数据分析系统包括快照模块,所述用户数据的处理方法还包括:
32.通过所述快照模块基于预设间隔时间,采集所述用户在线数据分析系统的快照,并生成快照文件,以供在所述用户在线数据分析系统出现故障时,根据所述快照文件进行恢复。
33.此外,本发明为实现上述目的,本发明还提供数据处理设备,所述数据处理设备包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的用户数据的处理程序,所述用户数据的处理程序被所述处理器执行时实现如上所述的用户数据的处理方法的步骤。
34.此外,本发明为实现上述目的,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有用户数据的处理程序,所述用户数据的处理程序被处理器执行时实现如上所述的用户数据的处理方法的步骤。
35.本发明一实施例提出的一种用户数据的处理方法,数据处理设备和计算机可读存储介质,通过获取采集的用户在线数据,根据用户在线数据的用户标识,确定用户在线数据对应的分析算子,并将用户在线数据发送至分析算子,进而通过分析算子对接收到的所述用户在线数据进行数据处理,并将处理结果更新缓存单元和实时在线数据库。通过在分析槽设置分析算子和与分析算子相对应的缓存单元,使每个缓存单元只需存储部分用户数据,以及通过用户在线数据的用户标识确定对应的分析算子,保证了同一用户在线数据自始至终由同一分析算子处理,以及由同一缓存单元存储该用户对应的历史用户信息,进而达成降低缓存性能要求的同时,提高数据处理的准确性的效果。
附图说明
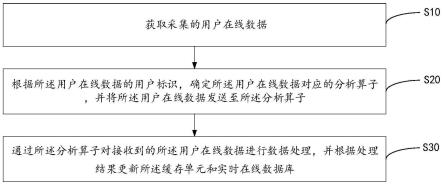
36.图1为本发明用户数据的处理方法的一实施例的流程示意图;
37.图2为本发明用户数据的处理方法涉及的用户在线数据分析系统的框架示意图;
38.图3为本发明用户数据的处理方法涉及的用户在线数据分析系统的另一框架示意图;
39.图4为本发明用户数据的处理方法的第二实施例中步骤s20的细化流程示意图;
40.图5为本发明用户数据的处理方法的第三实施例中步骤s30的细化流程示意图;
41.图6为本发明用户数据的处理方法的第三实施例中步骤s30的另一细化流程图;
42.图7为本发明用户数据的处理方法的第四实施例的流程示意图;
43.图8是本发明实施例方案涉及的硬件运行环境的终端结构示意图。
44.本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
45.应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
46.由于在相关技术中,通过将采集的用户在线数据分配到各个分析模块,各个分析模块结合当前采集的用户在线数据与公共外部缓存库中记录的用户在线数据,确定当前时段的实时用户在线情况。然而,由于各个分析模块共用一个外部缓存库,在用户数据急剧增加时,会造成对外部缓存库的频繁读写,使得外部缓存无法支撑数据分析的要求,从而导致用户在线情况分析结果不准确。
47.为解决相关技术中的上述缺陷,本发明提出一种用户数据的处理方法,其主要解决步骤包括以下:
48.通过获取采集的用户在线数据,根据用户在线数据的用户标识,确定用户在线数据对应的分析算子,并将用户在线数据发送至分析算子,进而通过分析算子对接收到的所
述用户在线数据进行数据处理,并将处理结果更新缓存单元和实时在线数据库。通过在分析槽设置分析算子和与分析算子相对应的缓存单元,使每个缓存单元只需存储部分用户数据,以及通过用户在线数据的用户标识确定对应的分析算子,保证了同一用户在线数据自始至终由同一分析算子处理,以及由同一缓存单元存储该用户对应的历史用户信息,进而达成降低缓存性能要求的同时,提高数据处理的准确性的效果。
49.为了更好地理解上述技术方案,下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整地传达给本领域的技术人员。
50.参照图1,在本发明用户数据的处理方法的一实施例中,所述一种用户数据的处理方法包括以下步骤:
51.步骤s10:获取采集的用户在线数据;
52.在本实施例中,用户数据的处理方法应用于用户在线数据分析系统,用户在线数据分析系统包括至少一个分析模块,分析模块设置有多个分析槽,分析槽设置有分析算子和与分析算子对应的缓存单元。分析算子用于将接收到的用户在线数据结合缓存单元中记录的历史用户信息,进行数据处理,以实时统计用户在线数量。用户在线数据分析系统还包括采集模块,采集模块用于实时采集用户在线数据,且在采集到用户在线数据之后,根据用户在线数据的用户标识确定对应的消息队列,进而将该用户在线数据发送至该消息队列。消息队列与分析模块一一对应,也即消息队列中存储的用户在线数据都由对应的分析模块进行接收并处理。分析模块包括读取算子,用于读取与分析模块相对应的消息队列中存储的用户在线数据,并将读取到的用户在线数据分配至对应的分析算子,由对应的分析算子进行数据处理,以实时统计用户在线数量,并更新缓存单元,以及更新实时在线数据库。通过在分析模块中设置多个分析槽,并且每个分析槽设置有分析算子和与分析算子对应的缓存单元,使得将缓存单元与分析算子联系起来,并且对缓存单元的访问不再需要通过网络,避免在网络异常或卡顿时,无法访问缓存单元的问题。并且每个缓存单元只存储部分用户在线数据,且只由对应的分析算子读写更新,各个分析算子之间完全独立,进而达成降低缓存性能要求,以及提高数据处理效率的效果。
53.示例性的,假如有1000万在线用户,每秒产生10万条用户在线数据,5万用户信息发生变更,消息队列分了10个分区。传统的方法,部署10台服务器对用户在线数据进行采集,启动10个分析模块,则每秒至少需要读外部缓存10万次,更新外部缓存5万次,外部缓存至少需要支持每秒15万次的读写能力,那么外部缓存总共用存储1000万用户信息。而本发明只需部署5台服务器对用户在线数据进行采集,启动5个分析模块,每个分析模块启动4个分析槽,总共20个数据分析算子,每个分析算子每秒只需读自己的缓存单元5000次,更新缓存单元2500次,缓存单元只需要支持每秒7500次的读写能力,那么每个缓存单元平均只需要存储5万用户信息,进而达成降低缓存性能要求,以及提高数据处理效率的效果。
54.可选地,采集模块可通过集群的方式部署多个采集服务器实现对用户在线数据的采集,各个采集服务器与对应的采集模块相对应,构成采集集群,可提高用户在线数据的采集速率。
55.可选地,采集模块在采集到用户在线数据时,可根据用户在线数据中的用户标识
进行哈希运算确定对应的哈希数值,进而将得到的哈希数值与消息队列的数量进行取余,根据得到的余数确定要发送的消息队列。由于得到的哈希数值是唯一的,进而保证同一个用户的在线数据自始至终被分配到同一个消息队列,而消息队列与分析模块一一对应,进而也保证同一个用户的数据自始至终被分配到同一个分析模块中处理。用户在线数据中各个用户所对应的用户标识并不相同。
56.步骤s20:根据所述用户在线数据的用户标识,确定所述用户在线数据对应的分析算子,并将所述用户在线数据发送至所述分析算子;
57.在本实施例中,用户标识可以是用户编号。由于分析模块包括至少一个分析槽,且每一个分析槽包括分析算子和与分析算子相对应的缓存单元。为了保证同一用户标识的用户在线数据都会发送到下游的同一个分析算子,读取算子可将当前时间要发送至分析算子的用户在线数据的用户标识的哈希数值除以分析算子数量取余,根据得到的余数确定对应的分析算子,进而将用户在线数据发送至该分析算子,进行数据处理,而分析算子又与缓存单元相对应,进而也使得同一用户的用户信息被保存于同一个缓存单元,从而达成提高数据处理结果的准确性的效果。
58.可选地,可根据用户在线数据的数据量在分析模块中设置多个分析槽,以提高数据处理的效率。由于各个分析算子之间完全独立,更利于水平扩容,以提高数据处理效率。故可根据用户在线数据的数据量在一个分析槽中设置一个或多个分析算子和与分析算子相对应的缓存单元,进而提高数据处理的效率。
59.需要说明的是,分析算子处理用户在线数据时,是单线程处理,即依次对用户在线数据中的用户数据进行处理,避免存在线程安全问题,同时也提高数据处理结果的准确性的效果。
60.步骤s30:通过所述分析算子对接收到的所述用户在线数据进行数据处理,并根据处理结果更新所述缓存单元和实时在线数据库。
61.在本实施例中,各个分析算子在接收到对应的用户在线数据时,根据接收到的用户在线数据和对应缓存单元中存储的历史用户信息,进行数据处理,并更新缓存单元,以及更新实时在线数据库,以基于实时在线数据库获取用户在线数据进而在终端进行展示。比如,读取实时在线数据库的用户在线数据在数据应用大屏端、手机端和报表系统等终端进行展示,本实施例对此不做具体限定。
62.示例性的,参照图2,采集模块采集用户在线数据后,获取用户在线数据的用户标识,并确定用户标识对应的哈希数值,确定哈希数值除以消息队列的数量的余数为2,那么将该用户在线数据发送至消息队列标识为2的消息队列,以对采集到的用户在线数据进行存储,进而各个分析模块中的读取算子读取与分析模块相对应的消息队列中存储的用户在线数据,根据用户在线数据的上报时间,将上报时间一致的放到同一个暂存队列,进而根据上报时间的先后顺序依次将暂存队列中的用户在线数据发送至对应的分析算子,以优先处理上报时间早的用户在线数据,在将上报时间早的暂存队列中的用户在线数据发送至对应的分析算子时,可根据用户在线数据的用户标识确定对应的哈希数值,以将确定的哈希数值与分析算子的数量进行取余操作,得到的余数为4,那么则将该队列中的用户在线数据发送至分析算子标识为4的分析算子,确保同一个用户的用户数据被发送至同一个分析算子进行处理,并且分析算子与缓存单元相对应,进而提高数据处理的准确度,分析算子在接收
到用户在线数据时,结合缓存单元中存储的历史用户信息,进行数据处理,并更新缓存单元,以及更新实时在线数据库,以基于实时在线数据库获取用户在线数据进而在终端进行展示。
63.可选地,在一些实施例中,参照图3,实时在线数据库可以是mpp(massiv ely parallel processing)数据库。用户在线数据分析系统包括查询模块,用于对mpp数据库中的实时用户在线数据进行查询,并生成分析报告,进而在终端进行展示。可在获取采集的用户在线数据之后由分析模块对用户在线数据进行清洗,以去除用户在线数据中的脏数据,例如去除重复记录的用户数据,将用户在线数据转换为符合mpp数据库规范的数据,本实施例对此不做具体限定。在对用户在线数据进行清洗之后直接将清洗后的用户在线数据发送至mpp数据库,进而终端可将对应的查询指令输入查询模块,查询模块基于输入的查询指令实时对mpp数据库中的实时用户在线数据进行查询输出或者统计用户在线数量,并生成对应的分析报告,在终端进行展示。不需要在分析模块中设置分析槽以及使用分析算子和缓存单元对用户数据进行数据处理,在对用户在线数据进行数据清洗后,直接更新至mpp数据库,终端可通过查询语句从mpp数据库中获取实时用户在线数据和统计用户在线数量,进而达成提升用户体验的效果。查询指令可以是sql语句,本实施例对此不做具体限定。
64.在本实施例提供的技术方案中,通过获取采集的用户在线数据,根据用户在线数据的用户标识,确定用户在线数据对应的分析算子,以确保同一用户数据被分配至同一个分析算子进行处理,进而确保同一用户的历史用户信息被存储于同一缓存单元,进而提高数据处理的准确度,之后通过分析算子对接收到的用户在线数据进行数据处理,并将处理结果更新缓存单元,以及更新实时在线数据库,以基于实时在线数据库获取用户在线数据进而在终端进行展示。通过在分析模块中设置多个分析槽,以及每个分析槽设置有分析算子和与分析算子对应的缓存单元,使得每个缓存单元只存储部分的用户在线数据,达成降低缓存性能要求的效果,且各个分析算子之间完全独立,使得能够对数据分析算子进行水平扩容,以在同一时间能够处理更多的用户在线数据,从而提高数据处理的效率。
65.参照图4,在第二实施例中,基于第一实施例,所述步骤s20,包括:
66.步骤s40:根据所述用户在线数据的用户标识,确定所述用户在线数据对应的分析算子;
67.步骤s50:根据所述用户在线数据的上报时间确定所述用户在线数据所属的暂存队列,控制所述用户在线数据入队;
68.步骤s60:在所述暂存队列创建时间大于或者等于预设延时时长时,将所述暂存队列中的所述用户在线数据发送至所述分析算子。
69.在本实施例中,分析模块包括读取算子,用于读取与分析模块相对应的消息队列中存储的用户在线数据,并将读取到的用户在线数据分配至对应的分析算子。读取算子可根据用户在线数据的上报时间先后依次发送至对应的分析算子。故读取算子可通过创建暂存队列,获取用户在线数据中各个用户的上报时间,将上报时间一致的放到同一个暂存队列,进而根据上报时间的先后顺序依次将暂存队列中的用户在线数据发送至对应的分析算子,以优先处理上报时间早的用户在线数据。由于控制用户在线数据入队需要时间,故为了避免数据晚到问题,在暂存队列创建时间大于或者等于预设延时时长时,将暂存队列中的用户在线数据发送至所述分析算子,进而保证能够将暂存队列中的所有数据发送至分析算
子,进而提高数据处理的准确性。上报时间的粒度为秒,上报时间的格式可以为时间戳,本实施例对此不做具体限定。预设延时时长的粒度为秒,为提高预设延时时长的精确度,提高数据处理效率,可记录用户在线数据开始入队至入队完成的时间,进而根据开始入队至入队完成的时间确定预设延时时长。比如多次记录用户在线数据开始入队至入队完成的时间,确定开始入队至入队完成的时间对应的时长,进而取其平均值,将计算得到的开始入队至入队完成的时间对应的时长平均值作为预设延时时长。
70.可选地,在一些实施例中,可根据上报时间将采集的用户在线数据放到对应的暂存队列,可设置暂存队列的优先级,采集的用户在线数据中用户的上报时间越早则放到优先级越高的暂存队列中,进而读取算子可按照暂存队列的优先级依次将暂存队列中的用户在线数据发送至分析算子,即优先级高的暂存队列中的用户在线数据被最先发送至分析算子。
71.示例性的,读取算子在从与分析模块对应的消息队列中读取到采集的用户在线数据之后,创建暂存队列,并将上报时间一致的用户在线数据存放至对应的暂存队列,并在暂存队列的创建时间大于或等于预设延时时长时,按照上报时间的先后将暂存队列中的用户在线数据分别发送至对应的分析算子,进而达成提高数据处理的准确度的效果。
72.在本实施例提供的技术方案中,通过读取算子根据用户在线数据的上报时间确定用户在线数据所属的暂存队列,进而控制用户在线数据入队,为了避免数据晚到问题,并不直接将暂存队列中的用户在线数据发送至对应的分析算子,而是在暂存队列创建时间大于或者等于预设延时时长时,将暂存队列中的用户在线数据发送至分析算子,以使得上报时间一致的用户在线数据能够被一次性发送至分析算子,进而达成提高数据处理的准确性的效果。
73.参照图5,在第三实施例中,基于上述任一实施例,步骤s30,包括:
74.步骤s31:获取所述用户在线数据中的用户标识;
75.步骤s32:确定所述缓存单元中,在线用户集合对应的历史用户标识;
76.步骤s33:当不存在与所述用户标识相同的历史用户标识时,将所述用户标识对应的用户信息添加至所述缓存单元的在线用户集合,并更新所述缓存单元中的用户上线数量;
77.步骤s34:当存在与所述用户标识相同的历史用户标识时,忽略所述用户在线数据,或者根据所述用户在线数据更新所述历史用户标识关联的数据。
78.在本实施例中,用户在线数据包括用户标识和用户信息。分析算子对接收到的用户在线数据的处理步骤包括:实时计算用户上线数量,并对缓存单元中的相关信息进行更新,以进行下一次的用户上线数量的计算,达成提高数据处理准确度的效果。分析算子对用户在线数据的处理为单线程处理,即依次处理用户在线数据中的用户数据,避免存在线程安全问题,并提高数据处理的准确度。在线集合用于存储历史在线用户的历史用户信息。获取用户在线数据中的用户标识,进而在缓存单元中查询是否存在与该用户标识相同的历史用户标识,若存在,则表明该用户当前已在线,此时将该用户标识对应的用户信息与该历史用户标识对应的历史用户信息相比,判断是否有更新,即是否相同,若相同,则忽略该用户在线数据,跳过处理下一条数据,若不相同,表明用户标识对应的用户信息有更新,进而将该用户标识对应的用户信息更新至缓存单元中的在线用户集合,或者更新至所述历史用户
标识相关联的历史用户信息。
79.示例性的,分析算子获取用户在线数据中的用户标识,根据该用户标识在缓存单元中的在线用户集合中查询该用户的历史用户信息,若查询结果为空,则表明在线集合中不存在该用户标识对应的历史用户信息,该用户为新的在线用户,将该用户标识对应的用户信息添加至在线集合,并更新缓存单元中的用户上线数量,用户上线数量加1,以记录当前时间上线的用户数量,若查询到有该用户标识对应的历史用户信息,表明该用户已上线,进一步将历史用户信息与该用户的用户信息进行比较,确定该用户信息是否有更新,若有更新,则将该用户标识对应的用户信息更新至缓存单元中的在线用户集合,若没有更新,则直接跳过继续处理下一条用户数据。
80.可选地,参照图6,所述控制分析算子对接收到的所述用户在线数据进行数据处理,并更新缓存单元,以及更新实时在线数据库的步骤之前,还包括:
81.步骤s70:获取所述缓存单元中保存的各个历史用户的下线时间;
82.步骤s80:当所述下线时间满足下线条件时,控制所述历史用户下线,并更新所述缓存单元保存的在线用户数据。
83.在本实施例中,在基于分析算子对接收到的用户在线数据进行数据处理之前,需要将缓存单元中满足下线条件的历史用户强制下线,以提高最后计算的用户在线数量的准确性。接收到的用户在线数据包括下线时间,进而在将接收到的用户在线数据更新至缓存单元时,同时也将用户在线数据的下线时间更新至缓存单元中,进而在对缓存单元中的历史用户进行下线清理时,可通过获取缓存单元中保存的各个历史用户的下线时间,进而判断是否满足下线条件,在满足下线条件时,控制该历史用户下线,并将该历史用户信息删除,以及记录用户下线数量,在不满足下线条件时,则跳过继续处理下一条数据。历史用户可以是存储在缓存单元中的在线集合中的数据,进而在满足下线条件时,将该在线集合中该历史用户对应的历史用户信息删除,并更新缓存单元中记录的用户下线数量。在当前时间为下线时间时可判定为满足下线条件。
84.可选地,用户在线数据分析系统可预设在线时长或者用户在上线登陆时可设置在线时长,进而根据设置的在线时长以及上报时间确定下线时间,采集模块采集到的用户在线数据包括下线时间。进而在缓存单元中,在线用户集合中存储的历史用户的最近一次上报时间大于或等于下线时间时,即可判定为满足下线条件,进而强制该用户下线,并将在线集合中该用户对应的历史用户信息删除,以及更新缓存单元中的用户下线数量,若该用户最近一次的上报时间小于下线时间时,则跳过继续处理下一条数据。比如,当前用户的上报时间为18:23:13,设置的在线时长为3h,那么下线时间为21:23:13,进而在该用户最近一次的上报时间大于或等于21:23:13时,即可强制该用户下线,并将在线集合中该历史用户对应的历史用户信息删除,以及更新缓存单元中的用户下线数量,若该用户最近一次的上报时间小于下线时间时,则跳过继续处理下一条数据。
85.可选地,分析模块包括更新算子,用于将各个分析算子计算得到的用户在线数量和用户上线数量以及用户下线数量进行整理后更新至实时在线数据库,以基于实时在线数据库获取用户在线数据进而在终端进行展示。缓存单元中包括历史用户在线数量,即上次记录的用户在线数量。在统计完用户上线数量和用户下线数量之后,需要对当前时间的用户在线数量进行计算。可根据历史用户在线数量标识获取缓存单元中的历史用户在线数
量,进而根据历史用户在线数量和计算的用户上线数量以及用户下线数量,确定当前时间的总用户在线数量,之后将缓存单元中的历史用户在线数量替换为计算得到的用户在线数量,进而基于更新算子将用户上线数量和用户下线数量以及用户在线数量,以及将在线集合中的用户在线数据更新至实时在线数据库,以基于实时在线数据库对当前时间的用户在线数据以及用户在线数据在终端进行展示。可通过设置历史用户在线数量标识,进而将记录的历史用户在线数据与该历史用户在线数量标识相关联,历史用户在线数量标识可以是缓存单元中存储该历史用户在线数量对应的列名称。
86.示例性的,根据历史用户在线数量标识获取缓存单元中存储的历史用户在线数量,若该历史用户在线数量存在,那么将历史用户在线数量加上用户上线数量以及减去用户下线数量即可得到当前时间的用户在线数量,若该历史用户在线数量不存在,那么遍历在线集合中的用户数据,将遍历得到的在线集合用户在线数量作为当前时间的用户在线数量,进而通过分析算子将得到的用户在线数量和用户上线数量以及用户下线数量更新至实时在线数据库,以基于实时在线数据库获取用户在线数据进而在终端进行展示。
87.在本实施例提供的技术方案中,分析算子在对接收到的用户在线数据进行处理之前,先获取缓存单元中存储的历史用户的下线时间,在下线时间满足下线条件时,控制该历史用户下线,并将该缓存单元中该历史用户对应的历史用户信息删除,并记录用户下线数量,在下线时间不满足下线条件时,则跳过处理下一条数据,进而在进行下线清理操作之后,获取用户在线数据中的用户标识,确定缓存单元中,在线用户集合对应的历史用户标识,当不存在与用户标识相同的历史用户标识时,将用户标识对应的用户信息添加至缓存单元的在线用户集合,并更新缓存单元中的用户上线数量,当存在与用户标识相同的历史用户标识时,忽略用户在线数据,或者根据用户在线数据更新历史用户标识关联的数据,之后通过获取缓存单元中记录的历史用户在线数量、用户上线数量和用户下线数量确定当前时间的用户在线数量,进而缓存单元中的历史用户在线数量替换为计算得到的用户在线数量,并基于更新算子将用户上线数量和用户下线数量以及用户在线数量更新至实时在线数据库,以基于实时在线数据库获取用户在线数据进而在终端进行展示,以达成提高数据处理的准确度的效果。
88.参照图7,在第四实施例中,基于上述任一实施例,所述用户数据处理方法还包括:
89.步骤s90:通过所述快照模块基于预设间隔时间,采集所述用户在线数据分析系统的快照,并生成快照文件,以供在所述用户在线数据分析系统出现故障时,根据所述快照文件进行恢复。
90.在本实施例中,快照是分析集群状态全局一致镜像的通用术语,快照包含有关输入源的位置信息,以及数据源读取到的偏移量信息以及整个应用程序状态信息。快照的作用是能够进行在线数据备份与恢复。当存储设备发生应用故障或者文件损坏时可以进行快速的数据恢复,将数据恢复至某个可用的时间点的状态。快照的另一个作用是为存储用户提供了另外一个数据访问通道,当原数据进行在线应用处理时,用户可以访问快照数据,还可以利用快照进行测试等工作。用户在线数据分析系统包括快照模块,用于采集用户在线数据分析系统的运行状态信息,并生成快照文件,以供在用户在线数据分析系统出现故障时,根据采集的快照文件进行恢复。采集快照可手动控制执行或者基于预设间隔时间执行,本实施例对此不做具体限定。
91.可以理解的是,步骤s70可在步骤s10、步骤s20和步骤s30中的任意一个步骤之间执行,本实施例对此不做具体限定。
92.可选地,生成的快照文件包括指向每个数据源的指针(例如,到文件或消息队列分区的偏移量)以及每个分析模块的有状态运算符的状态副本,该状态副本是处理了数据源偏移位置之前所有的事件后而生成的状态。可基于不同需求采集不同类型的快照,在对用户在线数据分析系统进行重新部署、升级或者缩放操作时,可使用savepoints(保存点)快照,进而在重新部署、升级或缩放操作之后可从采集的savepoints快照中对上次用户在线数据分析系统的数据进行恢复,进而能够接着从最后一次数据处理时间之后的时间对用户在线数据进行处理。比如在升级或重启过程中,分析模块停止运作时,自动采集savepoints快照,并生成快照文件,进而在分析模块启动时可从快照文件中自动恢复上次采集的快照,包含消息队列分区偏移量、最后一次数据处理时间和缓存单元中的数据等,然后接着从最后一次数据处理时间之后的时间开始对用户在线数据进行处理。为防止用户在线数据分析系统失败重启或异常退出,可基于预设间隔时间自动采集checkpoints(检查点)快照,进而在用户在线数据分析系统或用户在线数据分析系统中的各个模块失败重启或异常退出时,可以从最近一次采集的checkpoints快照中进行手工恢复,包含消息队列分区偏移量、最后一次数据处理时间和缓存单元中的数据等,然后接着从最后一次数据处理时间之后的时间开始对用户在线数据进行处理。快照文件的格式可以是hadoop分布式文件系统(简称hdfs)。
93.在本实施例提供的技术方案中,通过快照模块基于预设间隔时间,采集用户在线数据分析系统的快照,并生成快照文件,以供在用户在线数据分析系统出现故障时,根据快照文件进行恢复,采集的快照包含消息队列分区偏移量、最后一次数据处理时间和缓存单元中的数据等,进而在进行回复之后可接着从最后一次数据处理时间之后的时间开始对用户在线数据进行处理,不仅达成提高数据处理的效率的效果,还达成提高数量处理准确度的效果。
94.参照图8,图8为本发明实施例方案涉及的硬件运行环境的终端结构示意图。
95.本发明实施例终端可以是数据处理设备。
96.如图8所示,该终端可以包括:处理器1001,例如cpu,网络接口1004,用户接口1003,存储器1005,通信总线1002。其中,通信总线1002用于实现这些组件之间的连接通信。用户接口1003可以包括显示屏(display)、输入单元比如键盘(keyboard)、鼠标等,可选用户接口1003还可以包括标准的有线接口、无线接口。网络接口1004可选的可以包括标准的有线接口、无线接口(如wi-fi接口)。存储器1005可以是高速ram存储器,也可以是稳定的存储器(non-volatile memory),例如磁盘存储器。存储器1005可选的还可以是独立于前述处理器1001的存储装置。
97.本领域技术人员可以理解,图8中示出的终端结构并不构成对终端的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
98.如图8所示,作为一种计算机存储介质的存储器1005中可以包括操作系统、网络通信模块、用户接口模块以及用户数据的处理方法。
99.在图8所示的终端中,网络接口1004主要用于连接后台服务器,与后台服务器进行数据通信;处理器1001可以用于调用存储器1005中存储的用户数据的处理方法,并执行以
下操作:
100.获取采集的用户在线数据;
101.根据所述用户在线数据的用户标识,确定所述用户在线数据对应的分析算子,并将所述用户在线数据发送至所述分析算子;
102.通过所述分析算子对接收到的所述用户在线数据进行数据处理,并根据处理结果更新所述缓存单元和实时在线数据库。
103.进一步地,处理器1001可以调用存储器1005中存储的用户数据的处理方法,还执行以下操作:
104.根据所述用户在线数据的用户标识,确定所述用户在线数据对应的分析算子;
105.根据所述用户在线数据的上报时间确定所述用户在线数据所属的暂存队列,控制所述用户在线数据入队;
106.在所述暂存队列创建时间大于或者等于预设延时时长时,将所述暂存队列中的所述用户在线数据发送至所述分析算子。
107.进一步地,处理器1001可以调用存储器1005中存储的用户数据的处理方法,还执行以下操作:
108.获取所述用户在线数据中的用户标识;
109.确定所述缓存单元中,在线用户集合对应的历史用户标识;
110.当不存在与所述用户标识相同的历史用户标识时,将所述用户标识对应的用户信息添加至所述缓存单元的在线用户集合,并更新所述缓存单元中的用户上线数量;
111.当存在与所述用户标识相同的历史用户标识时,忽略所述用户在线数据,或者根据所述用户在线数据更新所述历史用户标识关联的数据。
112.进一步地,处理器1001可以调用存储器1005中存储的用户数据的处理方法,还执行以下操作:
113.获取所述缓存单元中保存的各个历史用户的下线时间;
114.当所述下线时间满足下线条件时,控制所述历史用户下线,并更新所述缓存单元保存的在线用户数据。
115.进一步地,处理器1001可以调用存储器1005中存储的用户数据的处理方法,还执行以下操作:
116.通过所述分析算子对接收到的所述用户在线数据进行数据处理,并根据处理结果更新所述缓存单元;
117.根据更新后的所述缓存单元中的数据确定历史用户在线数量、所述用户上线数量和用户下线数量;
118.根据所述历史用户在线数量和所述用户上线数量以及所述用户下线数量,确定当前时间的用户在线数量;
119.将所述用户在线数量更新至所述缓存单元,并基于所述分析算子将所述用户上线数量和所述用户下线数量以及所述用户在线数量更新至所述实时在线数据库,在终端展示。
120.进一步地,处理器1001可以调用存储器1005中存储的用户数据的处理方法,还执行以下操作:
121.对所述采集的用户在线数据进行数据清洗,并将数据清洗之后的所述用户在线数据实时更新至所述实时在线数据库。
122.进一步地,处理器1001可以调用存储器1005中存储的用户数据的处理方法,还执行以下操作:
123.通过所述查询模块接收查询指令;
124.根据所述查询指令确定所述实时在线数据库的实时用户在线数据,在终端展示。
125.进一步地,处理器1001可以调用存储器1005中存储的用户数据的处理方法,还执行以下操作:
126.通过所述快照模块基于预设间隔时间,采集所述用户在线数据分析系统的快照,并生成快照文件,以供在所述用户在线数据分析系统出现故障时,根据所述快照文件进行恢复。
127.此外,本发明为实现上述目的,本发明还提供数据处理设备,所述数据处理设备包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的用户数据的处理程序,所述用户数据的处理程序被所述处理器执行时实现如上所述的用户数据的处理方法的步骤。
128.此外,本发明为实现上述目的,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有用户数据的处理程序,所述用户数据的处理程序被处理器执行时实现如上所述的用户数据的处理方法的步骤。
129.需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
130.上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
131.通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在如上所述的一个存储介质(如rom/ram.磁碟.光盘)中,包括若干指令用以使得一台终端设备(数据处理设备、手机、电脑、平板电脑)执行本发明各个实施例所述的方法。
132.以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1