一种基于多维指标分析的期刊动态评价方法与流程
1.本发明涉及人工智能和自然语言处理领域,具体涉及一种基于多维指标分析的期刊动态评价方法。
背景技术:
2.近年来,人工智能技术不断发展,在图像、音频、文本等领域都产生众多成果。各行各业都开始或已经受人工智能技术影响。
3.在期刊评价方面,国外学术期刊评价方式主要有定性评价和定量评价两种。
4.基于同行评议的定性评价使期刊评价过程变得主观,目前美国utd24、澳大利亚abdc、英国abs和ft50和法国cnrs等是较为著名的同行评议期刊列表。
5.在定量评价法中,一些与期刊出版行为相关的单一指标是最为重要的客观评价方法。常见的分类有以期刊影响因子jif为代表的引文指标,以h指数为代表的引文指标,以pagerank为代表的引文指标,以altmetrics为代表的引文指标等。目前最常见的还是第一种,主要评价指标包括期刊影响因子、5年影响因子、总引用次数、期刊被引用半衰期等。
6.然而,尽管目前自然语言处理技术已经在期刊评价领域得到一些应用,如:期刊研究热点分析、期刊指标评价等等,这些应用虽然各有所长,但存在着单个技术应用面窄、对文本数据挖掘不深、没有针对多维指标动态评价等问题,因此基于人工排序和单指标排序的期刊评价仍然具有一定局限性。
技术实现要素:
7.本发明目的是提供一种基于多维指标分析的期刊动态评价方法,能够解决单指标排序的局限性,通过动态综合多维指标数据评价期刊影响力。
8.本发明为通过以下技术方案实现上述目的:
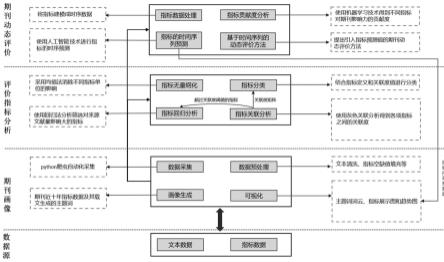
9.一种基于多维指标分析的期刊动态评价方法,包括步骤:
10.(1)从期刊平台收集期刊指标并记录、排序,获取期刊指标数据集;
11.(2)对结构化数据进行预处理,构建期刊时序数据集;
12.(3)对期刊指标数据集进行归一化处理,运用灰色关联分析方法以及回归分析方法,对评价指标进行分析;
13.(4)基于期刊指标数据集,选择传统机器学习、简单神经网络、深层神经网络方法用于期刊评价方向的回归任务,进行期刊评价指标重要性和相关性分析;
14.(5)基于期刊时序数据集和评价指标分析结果,构建期刊指标时间序列数据集,基于该数据集构建动态期刊评价预测模型,进行科技期刊动态评价。
15.每一条期刊指标包括包含3类期刊概述属性和18类期刊评价指标,所述期刊概述属性为期刊名、期刊种类、指标记录年份,所述期刊评价指标为地区分布数、基金论文比、平均作者数、平均引文数、引用半衰期、扩展h指标、扩展他引率、扩展即年指标、扩展学科影响指标、扩展学科扩散指标、扩展引用刊数、扩展总被引频次、扩展被引半衰期、文献选出率、
机构分布数、来源文献量、海外论文比、扩展影响因子。
16.为同时支持机器学习与深度学习的时间序列预测方法,且便于不同单位或量级的指标能够进行比较和加权,将时序数据集中的各类指标从有量纲表达式变成无量纲表达式,进行了归一化处理。
17.构建期刊时序数据集的方法为:完成数据进行特征矩阵和因变量的提取,采用删除或计算平均值填补的方法处理缺失的数据,并对数据进行特征缩放,在特征缩放中,期刊指标均处于相同的范围中,而每一指标数据的分布和特征缩放前保持一致,对数据集采用标准化方法,其公式如下:
[0018][0019]
其中,x为原始值,mean为平均值,a为标准差,x'为标准化后的值;
[0020]
最后将数据集分为训练集和测试集。
[0021]
灰色关联分析方法为:
[0022]
将n个期刊指标分别定义为x
′1,x
′2…
,x
′n,收集m个期刊样本的历年文献指标数据得到如下矩阵:
[0023][0024]
确定参照数据列,采用均值化方法对指标数据进行无量纲化:
[0025][0026]
无量纲化后数据矩阵如下:
[0027][0028]
逐个计算待分析指标列与参照列对应元素的绝对差值:
[0029]
|x0(k)-x1(k)| (i=0,1,...,n;k=1,...,m)
[0030]
计算关联系数,分别计算每个待分析指数列和参照列对应元素的关联系数。
[0031][0032]
其中ρ为分辨系数,0《ρ《1;
[0033]
求关联度:
[0034][0035]
其中,r为灰色关联度;
[0036]
最后比较各个文献指标的关联度大小。
[0037]
回归分析方法为:选择一种或多种机器学习方法以及神经网络用于期刊评价方向的回归任务,基于回归任务训练得出的模型获得期刊各指标对影响因子的贡献度。
[0038]
机器学习方法采用多元线性回归、随机森林和xgboost三种;
[0039]
(1)多元线性回归的实现方式为:选取影响因子作为因变量,其余期刊指标作为自变量,对数据进行标准化后,开始多元线性回归模型的训练,拟合出如下的多元线性函数:
[0040][0041]
其中,为第i个期刊的影响因子预测值,θ0为函数偏置,θn为期刊第n个评价指标权重,为第i个期刊的第n个评价指标值;
[0042]
将欧几里得距离作为目标函数,当目标函数尽可能小时,多元线性函数拟合完成,多元线性回归模型的训练也完成,此时获取各评价指标的权重即θn,将其作为各期刊评价指标对影响因子的贡献度,在这些权重中,正数表示正相关,负数表示负相关,贡献度计算公式如下:
[0043]
importancei=θi[0044]
其中,importancei是第i个期刊评价指标对期刊评价影响因子的预测贡献度,θi是第i个期刊评价指标在多元线性回归模型中的权重;
[0045]
(2)随机森林的实现方式为:将cart决策树作为弱学习器,在生成每一个树时,每个树使用bootstrap采样从训练集中随机采集一个随机的子数据集,并随机选取少量的期刊指标作为决策树的输入,而选择的期刊指标数为总指标数的开方,在训练过程中,随机森林算法中每一棵树生成根节点,判定是否满足该节点下训练样本个数小于预定阈值或节点不纯度小于预定阈值,若满足则停止生成,若不满足,则遍历所选的期刊评价指标及其取值,分别作为切分变量和切分点,并且通过切分后各子节点的绝对平均误差的加权和a(xi,v
ij
)来评判切分的好坏,选择切分效果最好的作为该节点的切分变量和切分点,并且根据切分变量和切分点生成新的左右子树,再次对左右字数进行新一轮的划分或停止生成,a(xi,v
ij
)的计算公式如下:
[0046][0047]
其中,xi为某一个切分变量,即期刊评价指标,v
ij
为切分变量的一个切分值,n
left
、n
right
,ns分别为切分后左子节点的训练样本个数、右子节点的训练样本个数以及当前节点所有训练样本的个数,x
left
、x
right
分别为左右子节点的训练样本集合,h(x)为衡量节点不纯度的函数,在回归任务中用绝对平均误差h(ω)计算,其公式如下:
[0048][0049]
其中,ω为该节点上的样本集合,n为样本集合ω中样本总数,为当前节点训练样本影响因子的平均值,yi为样本集合中第i个样本的影响因子值;
[0050]
当一棵回归决策树生成叶子节点后,该树的训练完成,接下来将采用sklearn提供的方法进行期刊评价指标对期刊影响因子的贡献度排序。首先,对于某一节点k,其重要性计算如下:
[0051]
ik=wk×ak-w
left
×aleft-w
right
×aright
[0052]
其中,wk,w
left
,w
right
分别为节点k以及其左右子节点中训练样本个数和总训练样本数目的比例,ak,a
left
,a
right
分别为节点k以及左右子节点的不纯度,在某一节点的重要性后,通过以下公式获得某一期刊评价指标的重要性。
[0053][0054]
其中,ψ为以期刊评价指标i为切分变量的节点,all nodes即随机森林中所有节点;
[0055]
(3)xgboost的实现方式为:由于xgboost与随机森林都是用分类回归树cart作为弱分类器,但随机森林将每一个弱分类器的相互独立的预测得分求平均值作为强分类器的预测得分,而xgboost则是将每一个弱分类器的预测得分相加作为强分类器的预测得分,因此训练时影响因子为yi的第n棵树的影响因子真实值其中为第n-1棵树对期刊影响因子预测结果;
[0056]
对于第i个期刊评价指标,其贡献度计算公式如下:
[0057][0058]
其中,c
ti
为第i个评价指标在第t棵树上作为切分变量的次数,c
t
为第t棵树的总结点数,φ为以第i个评价指标为切分变量的分类回归树。
[0059]
神经网络用于期刊评价方向的回归任务采用简单神经网络和深层神经网络;
[0060]
简单神经网络在模型训练阶段,将期刊评价影响因子作为真值,将其它期刊评价指标作为模型的输入特征矩阵,简单神经网络模型结构中共4层隐藏层,一层输入层,一层输出层,各隐藏层中神经元个数分别为200、100、50、25,最后一层输出层神经元个数为1且无需softmax层,模型的优化采用自适应矩估计;模型训练完成后,基于输入扰动、相关系数、权重分析或混合前三种方法来计算特征重要性;
[0061]
(1)基于输入扰动计算特征重要性的公式为:
[0062][0063]
其中,importancei为第i个期刊评价指标对于期刊评价影响因子预测的贡献度,u为期刊评价指标总数,maei为第i个期刊评价指标扰乱后的绝对平均误差;
[0064]
(2)基于相关系数计算特征重要性需先计算皮尔逊相关系数,其计算公式如下:
[0065][0066]
其中,correlation为皮尔逊相关系数,q为期刊总数,x
it
为第i个期刊中第t个期刊指标的值,yi为第i个期刊中期刊影响因子的值,为所有期刊第t个期刊指标的平均值,为所有期刊中期刊影响因子的平均值;在完成对所有期刊评价指标与期刊影响因子间皮尔逊相关系数的计算后,通过以下公式获得期刊评价指标对期刊影响因子预测的贡献度:
[0067][0068]
其中,correlationi为第i个期刊评价指标与期刊影响因子间的皮尔逊相关系数;
[0069]
(3)基于权重分析计算特征重要性的方式为:
[0070][0071]
其中,weighti为第i个期刊评价指标到隐藏层的总权重;
[0072]
(4)混合方法提出一个参数d:
[0073][0074]
其中,m为期刊评价指标总数,ii为第i个期刊评价指标在输入扰动算法下计算出对期刊影响因子预测的贡献度,为所有期刊评价指标在输入扰动算法下计算出对期刊影响因子预测的贡献度的均值;最终贡献度importancei的计算方式为:
[0075]
importancei=weight_imi+d*inputpertubation_imi+(1-d)*correlation_imi[0076]
其中,weight_imi为第i个期刊评价指标在权重分析算法下计算出对期刊影响因子预测的贡献度,inputpertubation_imi为第i个期刊评价指标在输入扰动算法下计算出对期刊影响因子预测的贡献度,correlation_imi为第i个期刊评价指标在相关系数算法下计算出对期刊影响因子预测的贡献度;
[0077]
深层神经网络在模型训练阶段的隐藏层中神经元个数分别为50、1024、2048、4096、2048、1024、50,最后输出层的神经元个数为1且无需softmax激活函数,每一个全连接层后均紧跟着批归一化层,且均实现drop out方法,模型的优化器采用随机梯度下降优化器;完成模型的训练后,用viann和garson两种算法来获得各期刊评价指标对期刊评价影响因子的贡献度并进行排序;
[0078]
viann算法在每次迭代结束权重更新时,更新当前运动方差,先计算第n次迭代后该权重的运动方差varn和均值mn,计算公式如下:
[0079][0080][0081]
其中,v
n-1
和m
n-1
分别为第n-1次迭代后某权重所有更新值的平方和和平均值,xn为第n次迭代后更新的权重;当所有迭代结束后,获取最后一次更新后输入层和第一隐藏层间的所有权重,用于计算每一个期刊评价指标对期刊影响因子预测的贡献度,计算公式如下:
[0082][0083]
其中,t为与第i个输入期刊评价指标相连的第一隐层神经元,var
it
为第i个期刊评价指标与第t个神经元间连接权重的运动方差,last_weight
it
为最后一次更新后第i个期刊评价指标与第t个神经元间连接权重的值;
[0084]
garson算法需要获得深度神经网络中输入层与第一隐层间的权重矩阵w1和最后
隐层与输出层的间的权重矩阵w2,按以下公式计算即可得到期刊评价指标对于期刊影响因子预测的贡献度组成的向量:
[0085]
importance=stu(w1×
w2)
[0086]
其中,stu()为归一化函数。
[0087]
构建动态期刊评价预测模型选择机器学习和深度学习方法构建,包括:(1)将期刊指标时序数据集处理成一维输入向量与单个target的监督学习形式来训练机器学习方法构建的预测模型,并输入数据集的数据进行训练;(2)将期刊指标时序数据集处理成时间步*特征值数尺寸的二维向量与单个target的形式来训练深度学习方法构建的预测模型,对数据进行归一化处理后输入模型中进行训练;
[0088]
机器学习方法包括多元线性回归、随机森林、xgboost、lightgbm,所述深度学习方法包括lstm、gru、conv-1d、wavenet和ann。
[0089]
进一步,本方案公开的基于多维指标分析的期刊动态评价方法还包括步骤:基于期刊指标数据集生成主题词,将指标可视化,构建科技期刊画像。
[0090]
构建科技期刊画像的方法为:利用词性标记定义主题词分块语法,将名词及其单一变形设定为所需关键词的语法规则,对主题句进行分析得到主题句对应的语法树,进而对主题句进行分块以提取其中的关键词作为论文主题词;利用关键词云方法对期刊自身信息进行标准化处理并画像。
[0091]
本发明的优点在于:
[0092]
本发明构建期刊时序数据集,该数据集涵盖数据量大、时间跨度长的特性,使其非常适合分析各指标对期刊评价的贡献,其自带的时序特征也可以帮助相关研究者动态的分析期刊的发展,将时间序列数据预测引入了期刊评价场景中并通过实验得到了一定的可用结果;
[0093]
本发明采用的灰色关联分析法,能够进行不同指标之间的强弱分析、关联分析,计划使用基于时变参数的状态空间方程从动态视角分析评价指标之间的关系强弱变化;xgboost算法将各指标作为参数输入,通过调参判断得到参数的重要性程度作为指标的贡献度,从中得到权重,比较不同评价指标的重要性,大幅度提升计算速度,简化模型,避免过拟合;证实了时间序列数据分析领域主流的机器学习与深度学习共9种方法在期刊评价场景下综合动态评价任务上具有一定的泛化性,为后续对该任务的算法优化打下基础并起到一定的方向指引作用;
[0094]
本发明通过文本分析技术提取期刊关键词,并进行可视化,生成主题词词云,同时将期刊的评价属性清晰地展示,能够直观地对期刊的发展动态进行展示,掌握期刊结构变化,了解通函竞争竞争态势和期刊市场需求,从而为学术期刊栏目策划提供数据支持。
附图说明
[0095]
图1为基于多维指标分析的期刊动态评价方法的流程图;
[0096]
图2为基于多维指标分析的期刊动态评价方法评价指标对期刊影响因子贡献度的获得流程图。
具体实施方式
[0097]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
[0098]
本实施例公开了一种基于多维指标分析的期刊动态评价方法,包括步骤:
[0099]
(1)基于知网和万方的期刊指标数据集,针对各个期刊收集18类评价指标,获取期刊指标数据集;
[0100]
(2)对结构化数据进行特征矩阵和因变量区分等预处理,构建期刊时序数据集;
[0101]
(3)基于期刊指标数据集,使用人工智能和自然语言处理技术生成主题词,并使指标可视化,构建科技期刊画像;
[0102]
(4)对期刊指标数据集进行无量纲化等归一化处理,运用灰色关联分析方法以及回归分析方法,对评价指标进行分析;
[0103]
(5)基于期刊指标数据集,选择传统机器学习、简单神经网络、深层神经网络方法用于期刊评价方向的回归任务,进行期刊评价指标重要性和相关性分析;
[0104]
(6)基于期刊时序数据集和评价指标分析结果,构建期刊指标时间序列数据集,基于该数据集使用机器学习、深度学习共9种方法构建动态期刊评价预测模型,进行科技期刊动态评价。
[0105]
上述各步骤的技术细节阐述如下,请参照图1进行对照:
[0106]
步骤1、构建期刊时序数据集
[0107]
本实施例使用的数据集是通过收集中国万方数据知识服务平台中历年期刊指标数据而制成的,该平台是中国著名的涵盖期刊、会议纪要、论文、学会成果的学术数据库,期刊时序数据集包含27125条期刊指标记录,每条记录由21类元素组成。为保证其多样性,本实施例在12个领域对期刊指标记录进行收集,数据集包含5425种期刊,每种期刊包括2017-2021每年的21类指标记录。
[0108]
每一条期刊指标包括包含3类期刊概述属性和18类期刊评价指标,所述期刊概述属性为期刊名、期刊种类、指标记录年份,所述期刊评价指标为地区分布数、基金论文比、平均作者数、平均引文数、引用半衰期、扩展h指标、扩展他引率、扩展即年指标、扩展学科影响指标、扩展学科扩散指标、扩展引用刊数、扩展总被引频次、扩展被引半衰期、文献选出率、机构分布数、来源文献量、海外论文比、扩展影响因子。
[0109]
按年份收集大量期刊指标记录并使用excel记录;随后依据期刊名与唯一标识筛选出包含连续五年记录的期刊,按照期刊名进行拼接,按照期刊名、记录年份进行排序;最后对拼接好的数据进行了缺失值填充、文本转化等清洗操作。对于缺失值,采用了以下两种方法来处理缺失的数据,第一种是统计数据集中缺失数据的具体行数,然后删除这些特定行,由于数据集的样本量足够大,因此删除这些数据并不会影响实验的准确性,依旧能获得较准确的答案,第二种则是通过计算平均值来处理缺失的数据,若五年全部缺失则直接以0填充;对于文本,将其转化为数值形式的元素以作为模型输入,最终构成了本文的期刊时序数据集。
[0110]
在时序数据集中,包含多个多变量、短时的时间序列。数据集中的每个期刊都包含近五年每年的指标记录,因此可看作5425条5时间步18维变量的时间序列样本,能够支持使用多种时间序列预测方法进行实验。为同时支持机器学习与深度学习的时间序列预测方
法,且便于不同单位或量级的指标能够进行比较和加权,将时序数据集中的各类指标从有量纲表达式变成无量纲表达式,进行了归一化处理。
[0111]
构建期刊时序数据集的方法为:用pandas库中的iloc方法完成了特征矩阵和因变量的提取,完成结构化数据的缺失处理,并对数据进行特征缩放,在多元线性回归中尤为重要,而在随机森林和xgboost中则不需要进行这一步。在特征缩放中,17种指标均处于相同的范围中,而每一指标数据的分布和特征缩放前保持一致。这样就可以保证在进行多元线性回归实验中,进行欧几里得距离计算时,在保持各指标自身特征不受影响的情况下,指标之间不会出现某变量支配其它的变量的问题。对数据集采用标准化方法,其公式如下:
[0112][0113]
其中,x为原始值,mean为平均值,a为标准差,x'为标准化后的值;最后将数据集分为训练集和测试集。数据集的70%被用作训练集,剩余的30%作为测试集。
[0114]
对指标进行关联分析,应用灰色理论中最广泛的分析法——灰色关联度分析方法。灰色关联分析法是对系统态势发展变化进行量化分析的方法,实质上就是比较评价对象与某一具体对象之间的接近程度,两者愈接近,评价对象的关联度就愈大。关联度是两个对象的指标之间关联程度大小的量度,它可以定量地描述对象之间相对变化的情况。主要解决某个包含多个因素的系统中,哪些因素是主要的,哪些因素是次要的,哪些因素影响大,哪些因素影响小等问题。针对期刊指标数据样本少的特点,灰色关联度分析可以克服传统数学分析所需的大量样本和计算量大的缺点,能较好地适用于动态过程分析。
[0115]
以影响因子和其他指标的关系分析为例,变量符号说明:将影响因子定义为x
′0,总被引频次定义为x
′1,即年指标定义为x
′2,他引率定义为x
′3,引用刊数定义为x
′4,开放因子定义为x
′5,扩散因子定义为x
′6,权威因子定义为x
′7,被引半衰期定义为x
′8等。
[0116]
利用收集期刊历年文献指标数据得到如下矩阵:
[0117][0118]
其中m是收集到的期刊样本数,n是文献指标数,确定影响因子为参照数据列,采用均值化方法对指标数据进行无量纲化,无量纲化处理的方法比较多,本发明使用均值化处理:
[0119][0120]
无量纲化后数据矩阵如下:
[0121][0122]
逐个计算待分析指标列与参照列对应元素的绝对差值:
[0123]
|x0(k)-x1(k)| (i=0,1,...,n;k=1,...,m)
[0124]
计算关联系数,分别计算每个待分析指数列和参照列对应元素的关联系数。
[0125][0126]
其中ρ为分辨系数,0<ρ<1;若ρ越小,关联系数间差异越大,区分能力越强,通常ρ取0.5。
[0127]
求关联度:
[0128][0129]
其中,r为灰色关联度。灰色关联度数值反映了相关影响因素与影响因子之间的关联程度,其值越大,反映了相关评价指标对影响因子影响的程度越大。
[0130]
最后比较各个文献指标的关联度大小。
[0131]
本发明分别选择多元线性回归、随机森林和xgboost三种机器学习方法,以及简单神经网络、深层神经网络方法用于期刊评价方向的回归任务,并基于回归任务训练得出的模型获得期刊各指标对影响因子的贡献度,流程请参照图2。
[0132]
(1)多元线性回归的实现方式为:将各期刊的影响因子作为因变量,将其余17种期刊指标作为自变量,在对数据进行标准化后,开始多元线性回归模型的训练,拟合出如下的多元线性函数:
[0133][0134]
其中,为第i个期刊的影响因子预测值,θ0为函数偏置,θn为期刊第n个评价指标权重,为第i个期刊的第n个评价指标值;
[0135]
将欧几里得距离作为目标函数,当目标函数尽可能小时,多元线性函数拟合完成,多元线性回归模型的训练也完成,此时获取各评价指标的权重即θn,将其作为各期刊评价指标对影响因子的贡献度,在这些权重中,正数表示正相关,负数表示负相关,贡献度计算公式如下:
[0136]
importancei=θi[0137]
其中,importancei是第i个期刊评价指标对期刊评价影响因子的预测贡献度,θi是第i个期刊评价指标在多元线性回归模型中的权重。
[0138]
(2)随机森林的实现方式为:将cart决策树作为弱学习器,在生成每一个树时,每个树使用bootstrap采样从训练集中随机采集一个随机的子数据集,并随机选取少量的期刊指标作为决策树的输入,而选择的期刊指标数为总指标数的开方,即为4,这样就保证了特征的随机性,此时输入的数据无需标准化。在训练过程中,随机森林算法中每一棵树生成根节点,判定是否满足该节点下训练样本个数小于预定阈值或节点不纯度小于预定阈值,若满足则停止生成,若不满足,则遍历所选的期刊评价指标及其取值,分别作为切分变量和切分点,并且通过切分后各子节点的绝对平均误差的加权和a(xi,v
ij
)来评判切分的好坏,选择切分效果最好的作为该节点的切分变量和切分点,并且根据切分变量和切分点生成新的左右子树,再次对左右字数进行新一轮的划分或停止生成,a(xi,v
ij
)的计算公式如下:
[0139][0140]
其中,xi为某一个切分变量,即期刊评价指标,v
ij
为切分变量的一个切分值,n
left
、n
right
,ns分别为切分后左子节点的训练样本个数、右子节点的训练样本个数以及当前节点所有训练样本的个数,x
left
、x
right
分别为左右子节点的训练样本集合,h(x)为衡量节点不纯度的函数,在回归任务中用绝对平均误差h(ω)计算,其公式如下:
[0141][0142]
其中,ω为该节点上的样本集合,n为样本集合ω中样本总数,为当前节点训练样本影响因子的平均值,yi为样本集合中第i个样本的影响因子值;
[0143]
当一棵回归决策树生成叶子节点后,该树的训练完成,接下来将采用skleam提供的方法进行期刊评价指标对期刊影响因子的贡献度排序。首先,对于某一节点k,其重要性计算如下:
[0144]
ik=wk×ak-w
left
×aleft-w
right
×arig
[0145]
其中,wk,w
left
,w
right
分别为节点k以及其左右子节点中训练样本个数和总训练样本数目的比例,ak,a
left
,a
right
分别为节点k以及左右子节点的不纯度,在某一节点的重要性后,通过以下公式获得某一期刊评价指标的重要性。
[0146][0147]
其中,ψ为以期刊评价指标i为切分变量的节点,all nodes即随机森林中所有节点。
[0148]
(3)xgboost的实现方式为:由于xgboost与随机森林都是用分类回归树cart作为弱分类器,但随机森林将每一个弱分类器的相互独立的预测得分求平均值作为强分类器的预测得分,而xgboost则是将每一个弱分类器的预测得分相加作为强分类器的预测得分,因此训练时影响因子为yi的第n棵树的影响因子真实值其中为第n-1棵树对期刊影响因子预测结果;
[0149]
对于第i个期刊评价指标,其贡献度计算公式如下:
[0150][0151]
其中,c
ti
为第i个评价指标在第t棵树上作为切分变量的次数,c
t
为第t棵树的总结点数,φ为以第i个评价指标为切分变量的分类回归树。
[0152]
根据以上方式,得到的贡献度top5排名如下:
[0153]
methodsrank1rank2rank3rank4rank5xgboost扩展h指标即年指标来源文献量机构分布数平均引文数random forest扩展h指标即年指标平均引文数来源文献量机构分布数linear regression即年指标扩展h指标学科影响指标来源文献量基金论文比
[0154]
神经网络用于期刊评价方向的回归任务采用简单神经网络和深层神经网络:
[0155]
(1)简单神经网络
[0156]
在模型训练阶段,我们将期刊评价影响因子作为ground truth,将其它17种期刊评价指标作为模型的输入特征矩阵。该模型结构中共4层隐藏层,一层输入层,一层输出层,各隐藏层中神经元个数分别为200、100、50、25,最后一层输出层神经元个数为1且无需softmax层,因为这是一个回归任务,仅输出预测的影响因子即可。模型的优化采用自适应矩估计(adam),该优化算法既引入冲量又可以自适应改变学习率大小,有效的预防了梯度震荡和稀疏梯度等问题。模型的初始学习率设为0.01,批大小设为32,根据作者建议,训练集中75%用于训练,25%用于验证。
[0157]
在完成模型的训练后,我们用以下4种方法来获得各期刊评价指标对期刊评价影响因子的贡献度并进行top5的排序:
[0158]
①
基于输入扰动计算特征重要性
[0159][0160]
其中,importancei为第i个期刊评价指标对于期刊评价影响因子预测的贡献度,u为期刊评价指标总数,maei为第i个期刊评价指标扰乱后的绝对平均误差。
[0161]
②
基于相关系数计算特征重要性
[0162]
需先计算皮尔逊相关系数,其计算公式如下:
[0163][0164]
其中,correlation为皮尔逊相关系数,q为期刊总数,x
it
为第i个期刊中第t个期刊指标的值,yi为第i个期刊中期刊影响因子的值,为所有期刊第t个期刊指标的平均值,为所有期刊中期刊影响因子的平均值;在完成对所有期刊评价指标与期刊影响因子间皮尔逊相关系数的计算后,通过以下公式获得期刊评价指标对期刊影响因子预测的贡献度:
[0165][0166]
其中,correlationi为第i个期刊评价指标与期刊影响因子间的皮尔逊相关系数。
[0167]
③
基于权重分析计算特征重要性:
[0168][0169]
其中,weighti为第i个期刊评价指标到隐藏层的总权重。
[0170]
④
混合方法
[0171]
前三种方法中,有的要么只依赖于数据集,要么只依赖于已经完成训练的模型,因此,这里实现了一种混合方法,结合前三种方法提出一个参数d:
[0172][0173]
其中,m为期刊评价指标总数,ii为第i个期刊评价指标在输入扰动算法下计算出对期刊影响因子预测的贡献度,为所有期刊评价指标在输入扰动算法下计算出对期刊影响因子预测的贡献度的均值;最终贡献度importancei的计算方式为:
[0174]
importancei=weight_imi+d*inputpertubation_imi+(1-d)*correlation_imi[0175]
其中,weight_imi为第i个期刊评价指标在权重分析算法下计算出对期刊影响因子预测的贡献度,inputpertubation_imi为第i个期刊评价指标在输入扰动算法下计算出对期刊影响因子预测的贡献度,correlation_imi为第i个期刊评价指标在相关系数算法下计算出对期刊影响因子预测的贡献度。
[0176]
简单神经网络方法获得的贡献度top5排名为:
[0177][0178]
(2)深层神经网络
[0179]
在模型训练阶段的隐藏层中神经元个数分别为50、1024、2048、4096、2048、1024、50,最后输出层的神经元个数为1且无需softmax激活函数,每一个全连接层后均紧跟着批归一化层,且均实现drop out方法,模型的优化器采用随机梯度下降优化器;完成模型的训练后,用viann和garson两种算法来获得各期刊评价指标对期刊评价影响因子的贡献度并进行排序;
[0180]
①
viann算法
[0181]
在每次迭代结束权重更新时,更新当前运动方差,先计算第n次迭代后该权重的运动方差varn和均值mn,计算公式如下:
[0182][0183][0184]
其中,v
n-1
和m
n-1
分别为第n-1次迭代后某权重所有更新值的平方和和平均值,xn为第n次迭代后更新的权重;当所有迭代结束后,获取最后一次更新后输入层和第一隐藏层间的所有权重,用于计算每一个期刊评价指标对期刊影响因子预测的贡献度,计算公式如下:
[0185][0186]
其中,t为与第i个输入期刊评价指标相连的第一隐层神经元,var
it
为第i个期刊评价指标与第t个神经元间连接权重的运动方差,last_weight
it
为最后一次更新后第i个期刊评价指标与第t个神经元间连接权重的值;
[0187]
②
garson算法
[0188]
需要获得深度神经网络中输入层与第一隐层间的权重矩阵w1和最后隐层与输出层的间的权重矩阵w2,按以下公式计算即可得到期刊评价指标对于期刊影响因子预测的贡献度组成的向量:
[0189]
importance=stu(w1×
w2)
[0190]
其中,stu()为归一化函数。
[0191]
深层神经网络方法所获贡献度top5排名为:
[0192]
methodsrank1rank2rank3rank4rank5
viann被引半衰期即年指标扩展h指标扩展他引率文献选出率garson即年指标被引半衰期扩展h指标扩展他引率文献选出率
[0193]
由于简单神经网络中输入扰乱对于期刊影响因子的贡献度排名与其它方法有着较大的差别,所以再次在更深层次的神经网络中使用了input perturbation方法来重新计算贡献度,并与扰乱前进行对比,计算了它们的平均平方误差mse和平均绝对值误差mae,期刊评价指标扰乱前后对期刊影响因子预测损失对比如下表所示:
[0194]
factormsemaenull0.29930.2941地区分布数0.433050.534394基金论文比0.433300.534522平均作者数0.432880.534569平均引文数0.430930.533971引用半衰期0.432860.534738扩展h指标0.428290.533240扩展他引率0.433020.534505即年指标0.432880.534471学科影响指标0.433040.534521学科扩散指标0.432560.534354扩展引用刊数0.423430.534203总被引频次0.432340.553242被引半衰期0.432910.534099文献选出率0.433020.534546机构分布数0.438380.541738来源文献量0.434400.555592海外论文比0.433110.534530
[0195]
构建动态期刊评价预测模型选择机器学习和深度学习方法构建,包括:(1)将期刊指标时序数据集处理成一维输入向量与单个target的监督学习形式来训练机器学习方法构建的预测模型,并输入数据集的数据进行训练;(2)将期刊指标时序数据集处理成时间步*特征值数尺寸的二维向量与单个target的形式来训练深度学习方法构建的预测模型,对数据进行归一化处理后输入模型中进行训练;
[0196]
机器学习方法包括多元线性回归、随机森林、xgboost、lightgbm,所述深度学习方法包括lstm、gru、conv-1d、wavenet和ann。
[0197]
九种方法构建的动态期刊评价预测模型预测情况如下表所示:
[0198][0199]
实施例2
[0200]
在实施例1的基础上,本发明还公开了构建科技期刊画像的评价模型的具体实现方式,包括数据采集,数据处理和可视化三个部分。期刊画像构建需要选取规模合理且易于抽取的数据来源,能够准确展示期刊属性特征与动态发展。为了匹配期刊模型构建方法,研究过程需要对采集到的数据进行处理,包括归一化和数据清洗的过程,最终对期刊画像进行可视化展示。
[0201]
(1)期刊画像组成信息
[0202]
期刊画像是从与期刊高度相关的信息中提炼出来能体现期刊属性特征,并将属性特征中的实体信息与抽象信息分别构建并组合起来形成的一个生动立体的期刊模型。将期刊自身信息与定量评价相结合,全面地对学术期刊开展综合评价,期刊画像被划分为实体期刊画像和抽象期刊画像两个部分,实体期刊画像主要包含期刊核心论文自身信息,抽象期刊画像主要包含期刊历年指标数据信息,如下表所示:
[0203][0204]
(2)主题词的生成
[0205]
针对相关期刊的文本数据,其中期刊论文主题句需要处理成主题词,由于摘要文本太长,很难确定核心表达,因而可以考虑用主题词代替摘要。论文主题句“hightlight”部分内容主要是作者对自己论文最核心的部分进行描述,往往也是核心要点的表述数据,具有重要的研究意义。首先利用词性标记定义主题词分块语法,将名词及其单一变形(具有单一修饰的单数名词词块或名词词块本身变形)设定为所需关键词的语法规则,然后对主题句进行分析,得到主题句对应的语法树,进而对主题句进行分块以提取其中的关键词作为论文主题词。示例见下表:
[0206][0207]
(3)主题词和指标可视化
[0208]
根据上述数据采集和处理方法,利用关键词云方法对期刊自身信息进行标准化处理并画像。将采集到的期刊指标数据与对应年份作为期刊画像的组成元素以构建每本学术期刊画像,利用绘图工具即可对表格文件进行数据可视化展示。
[0209]
最后应说明的是,以上所述仅为本发明的优选实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1