基于机器学习的空调异常识别方法与流程
1.本发明涉及空调控制领域,具体是一种基于机器学习的空调异常识别方法。
背景技术:
2.随着信息通讯的不断发展,通信基站的正常运转已经是社会进行正常生产生活的重要保障,而基站内的空调又是保障基站正常运行的重要角色。目前,大多数基站处于无人值守状态,空调异常的发现源于对空调的定期巡检和空调发生故障时的故障码,存在较大的信息滞后性,这使得对空调异常的发现和识别比较被动,从而无法及时发现空调出现异常,影响故障的及时排除;另一方面,温度、空调的运行数据及基站外环境信息没有得到充分利用,无法发挥辅助空调故障排除的作用。
技术实现要素:
3.为了准确及时的发现空调异常,本技术提供了一种基于机器学习的空调异常识别方法。
4.本发明解决上述问题所采用的技术方案是:
5.基于机器学习的空调异常识别方法,包括:
6.步骤1、获取空调运行数据及运行环境数据;
7.步骤2、数据预处理并排序以得到时序数据;
8.步骤3、对时序数据进行混频处理以统一数据的时间颗粒度;
9.步骤4、对步骤3获取的数据进行聚类以获取异常数据簇;
10.步骤5、根据空调开关状态对异常数据簇进行业务重定位;
11.步骤6、构建kmbod模型对步骤5获取的数据进行异常识别以得到对应的异常类别。
12.为了便于数据处理,所述步骤1在获取数据时获取的是结构化数据。
13.进一步地,所述步骤2中数据预处理包括去重、审查和校验。
14.进一步地,所述步骤3中采用em算法对数据进行混频处理,具体为:
15.步骤31、确定目标时间颗粒度[t1,t2,t3,
…
,ti];
[0016]
步骤32、利用em算法对目标时间颗粒度以外的数据进行数据扩展:设待混频处理的时间为[t'1,t'2,t'3,
…
,t'j],对应的数据为[q
21
,q
22
,q
23
,
…
,q
2j
],数据扩展步骤为:
[0017]
基于[q
21
,q
22
,q
23
,
…
,q
2j
]及em算法估计出模型参数为θ1,
[0018]
根据θ1估计[q
21
,q
22
,q
23
,
…
,q
2j
]在[t1,t2,t3,
…
,ti]对应的值为
[0019]
根据[q
21
,q
22
,q
23
,
…
,q
2j
]和估计并更新模型参数为θ2,
[0020]
根据θ2估计并更新[q
21
,q
22
,q
23
,
…
,q
2j
]在[t1,t2,t3,
…
,ti]对应的值为
[0021]
根据[q
21
,q
22
,q
23
,
…
,q
2j
]和估计并更新模型参数为θ3,
[0022]
根据θ3估计并更新数据,如此进行迭代直至模型参数收敛,最后估计出[q
21
,q
22
,q
23
,
…
,q
2j
]在[t1,t2,t3,
…
,ti]对应的值为[q'
21
,q'
22
,q'
23
,
…
,q'
2i
];
[0023]
步骤33、将扩展后的数据与目标时间颗粒度[t1,t2,t3,
…
,ti]原有数据进行融合。
[0024]
进一步地,所述步骤4采用dbscan模型对数据进行聚类,具体为:
[0025]
步骤41、利用历史数据构建模型训练数据,包括训练集和测试集;
[0026]
步骤42、利用训练数据训练dbscan模型;
[0027]
步骤42、利用构建的模型对步骤3得到的数据进行分类,得到异常数据簇。
[0028]
进一步地,所述步骤4获取异常数据簇后还包括:将异常数据簇内的数据进行时间排序;根据时序化的异常数据簇提取异常开始发生时刻及其前后时间步长w的数据段,重构异常时间片。
[0029]
进一步地,所述步骤6构建kmbod模型的具体步骤为:
[0030]
步骤61、利用动态时间规整算法计算异常时间片之间的相似度dtw(x,y);
[0031]
步骤62、基于相似度dtw(x,y)进行kmbod聚类:
[0032]
随机选取k个异常时间片作为中心点,计算剩余异常时间片与各中心点的相似度,将异常时间片与最相似的中心点归为一类,形成k个异常时间片簇,计算目前聚类的总损失e;
[0033][0034]
e是各簇的所有非中心异常时间片与该簇的中心时间片的相似度之和的总和,k是中心点个数,ci为异常时间片簇,oi为ci的中心点,p为ci中的非中心点;
[0035]
对每个中心点o和非中心点p,进行如下步骤:
[0036]
交换o和p的角色,将p作为中心点重新聚类,计算聚类后的总损失e;如果总损失增大则不进行角色交换,若减小则进行角色交换;重复上述步骤,直到总损失e不再减小;
[0037]
步骤63、获取最佳kmbod模型:计算不同k值下聚类结果的轮廓系数,最大的轮廓系数对应的k值即为最佳聚类数,其对应的模型即为最佳kmbod模型。
[0038]
进一步地,还包括步骤7、输出异常类别。
[0039]
本发明相比于现有技术具有的有益效果是:通过对数据进行混频处理,利用数据添加算法em对时间颗粒度大的数据进行数据添加,缩小其时间颗粒度,统一各维数据的时间间隔,使数据的时间序列性更完备,进而使得后续的异常定位效果更加理想。
[0040]
通过dbscan聚类,初步定位出包含异常数据的异常数据簇,再对异常片段进行业务重定位,有效筛选出异常时间片,直接用异常时间片来构建kmbod模型并进行异常类别检测,有效规避了正负样本不平衡的难题,直接降低了模型构建成本,提高检测效率和准确性。
[0041]
通过kmbod算法对异常时间片数据进行异常类别检测,该算法在充分考虑时序数据相似性的基础上进行聚类,通过dtw解决了存在时间平移的同一类异常时间片相似性无法有效刻画的问题(空调同一类异常持续时间可能不同,造成同一类异常时间片的形态存在时间平移,它们之间的相似度无法有效度量),提高模型的准确性和有效性。
附图说明
[0042]
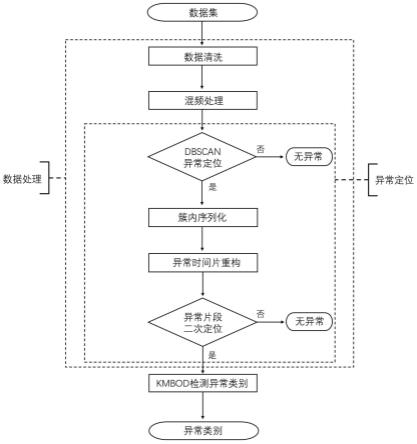
图1为基于机器学习的空调异常识别方法的流程图。
具体实施方式
[0043]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
[0044]
实施例
[0045]
如图1所示,基于机器学习的空调异常识别方法,包括:
[0046]
步骤s1、获取空调运行数据及运行环境数据,包括基站机房内的温湿度数据、空调开关状态、空调电流电压功率等空调运行数据以及室外温湿度数据;为了便于数据处理,本实施例在数据获取时获取的是结构化数据,假设有两种时间颗粒度的数据f1和f2,时间颗粒度分别为f1和f2,数据序列f1时间依次为[t1,t2,t3,
…
,ti]共计i个时间点,每个时间点有p个字段[p1,p2,p3,
…
,p
p
],数据序列f2时间依次为[t'1,t'2,t'3,
…
,t'j]共计j个时间点,每个时间点有q字段[q1,q2,q3,
…
,qq],两种数据的数据结构分别应当如下表:
[0047][0048]
步骤s2、数据预处理并排序以得到时序数据,本实施例中,数据预处理主要包括去重、审查和校验。去重是指检测数据中的同一时间标签t是否出现多次,若出现多次,则只保留其中的一条数据,删除剩余部分;审查是指根据时间连续性,检查数据是否存在缺失;校验是指根据相关数据协议,检查数据是否在规定范围内,是否为无效值,是否为空值。为了提高数据完整性,还可以对缺失值和无效值进行填充,得到清洗后的时序数据。
[0049]
步骤s3、对步骤s2得到的数据进行混频处理:利用em算法对数据f2进行数据扩展,利用已知的[t'1,t'2,t'3,
…
,t'j]时刻对应的数据,估计[t1,t2,t3,
…
,ti]各时刻对应的数据,将其时间颗粒度由f2缩小至f1,并将其与数据f1进行多维数据融合,例如:对f2中的某个字段进行混频处理,利用em算法根据[t'1,t'2,t'3,
…
,t'j]对应的已知数据[q
21
,q
22
,q
23
,
…
,q
2j
],估计出模型参数θ1,根据模型参数估计出q2在时刻[t1,t2,t3,
…
,ti]对应的值再根据已知数据[q
21
,q
22
,q
23
,
…
,q
2j
]和上一步估计出的数据估计并更新模型参数为θ2,根据模型参数θ2估计并更新时刻[t1,t2,
t3,
…
,ti]对应的值为再根据已知数据[q
21
,q
22
,q
23
,
…
,q
2j
]和上一步估计出的数据估计并更新模型参数为θ3,根据模型参数θ3估计并更新数据,如此进行迭代直至模型参数收敛,最后估计出字段q2在时刻[t1,t2,t3,
…
,ti]对应的值[q'
21
,q'
22
,q'
23
,
…
,q'
2i
]。对f2进行数据扩展后,并与f1进行多维数据融合,融合后数据结构如下:
[0050]
[{t1:[p1,p2,p3,
…
,p
p
,q'1,q'2,q'3,
…
,q'q]},
[0051]
{t2:[p1,p2,p3,
…
,p
p
,q'1,q'2,q'3,
…
,q'q]},
[0052]
{t3:[p1,p2,p3,
…
,p
p
,q'1,q'2,q'3,
…
,q'q]},
[0053]
…
[0054]
{ti:[p1,p2,p3,
…
,p
p
,q'1,q'2,q'3,
…
,q'q]}]
[0055]
步骤s4、利用历史数据训练dbscan聚类模型,利用训练后的dbscan聚类模型对步骤s3所得数据进行聚类,标定异常数据,得到包含空调异常时段的异常数据簇。对历史数据据进行步骤s2-s3处理,得到可用于训练的数据集h(已知哪些数据为异常数据),将数据集h分为训练集train和测试集test;利用训练集train和测试集test进行训练,得到dbscan聚类模型;利用训练得到的模型对步骤s3得到的数据进行分类,得到n个异常数据簇{d1,d2,d3,
…
,dn},异常数据簇内的数据是时间乱序的,例如d1和d2内的数据示例如下:
[0056][0057]
步骤s5、将各个异常数据簇内的数据按时间字段t进行顺序排序。
[0058]
步骤s6、根据时序化的异常数据簇提取异常开始发生时刻附近的数据段,重构异常时间片。异常数据簇中最早的时刻为异常发生时刻ts,以ts为起点,按时间分别向前向后各滑动固定时间步长w,取时刻t
s-w
至t
s+w
之间的数据作为新的异常时间片,如下:
[0059][0060]
步骤s7、对异常片段进行业务重定位:步骤s6所得的异常时间片中包括空调开关状态字段flag;检测其中的空调开关状态字段flag,0表示关闭状态,1表示开启状态,若检测到时间片中的字段flag不存在等于0的情况,则保留该异常时间片。
[0061]
步骤s8、构建kmbod模型对异常时间片进行异常类别识别:利用历史异常时间片数据训练kmbod模型,利用动态时间规整算法计算异常时间片之间的相似度,如计算异常时间片x和y的相似度(有m个字段,n个时间点),x和y如下:
[0062][0063]
x和y的相似度等于其各对应字段相似度之和,即:
[0064][0065]
计算各字段时间序列相似度,对应字段xk和yk,首先构建n
×
n的矩阵d,矩阵元素d
ij
=dist(x
ki
,y
kj
)=|x
ki-y
kj
|,其中dist(x
ki
,y
kj
)为欧氏距离,然后在矩阵d中使用动态规划搜索出d
11
到d
nn
的最短路径(其长度为l
min
),从矩阵d左上角元素d
11
起始向右下角元素d
nn
搜索,在每个元素处可选择右、右下、下三个方向中的一个作为下一步搜索方向,当前路径长度=前一步路径长度+当前元素的大小,设d
11
到任一点d
ij
的最短路径长度为l
min
(i,j),起始条件为l
min
(1,1)=d
11
,可递推:
[0066]
l
min
(i,j)=min{l
min
(i-1,j),l
min
(i,j-1),l
min
(i-1,j-1)}+d
ij
[0067]
该最短路径的长度即为xk与yk的相似度,各对应字段相似度之和即为异常时间片x与y的相似度dtw(x,y),相似度越小说明越相似;将该相似度作为样本之间的“距离”进行kmbod聚类,随机选取k个异常时间片作为中心点(中心异常时间片),计算剩余异常时间片与各中心点的相似度,将异常时间片与最相似的中心点归为一类,形成k个异常时间片簇,计算目前聚类的总损失e,公式如下:
[0068][0069]
e是各簇的所有非中心异常时间片与该簇的中心时间片的相似度之和的总和,k是中心点个数,ci为异常时间片簇,oi为ci的中心点,p为ci中的非中心点。对每个中心点o和非中心点p,进行如下步骤:
[0070]
1)交换o和p的角色,将p作为中心点重新聚类,计算聚类后的总损失e;
[0071]
2)如果总损失增大则不进行角色交换,若减小则进行角色交换;
[0072]
3)重复步骤1和2,直到总损失e不再减小。
[0073]
计算不同k值下聚类结果的轮廓系数,最大的轮廓系数对应的k值即为最佳聚类数,其对应的即为最佳kmbod模型。用构建的模型对步骤s7中的异常时间片进行异常类别识别,得到对应的异常类别,并在步骤s9中输出。
[0074]
kmbod模型是k-mediods模型的改良,传统的k-mediods是根据欧式距离或者曼哈顿距离进行聚类,本技术为了适配时序数据进行聚类,将距离替换为根据动态时间规整(dtw)计算的时序数据间的相似度,这里将其命名为kmbod模型。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1