一种基于司法大数据多特征映射的案件量预测方法及系统与流程
1.本发明属于计算机软件技术及人工智能技术领域,具体涉及一种基于司法大数据多特征映射的案件量预测方法及系统。
背景技术:
2.目前,最高人民法院已建成人民法院大数据管理和服务平台,实现了全国四级法院审判执行数据自下而上的实时汇聚并统一管理,形成了世界上最大、最丰富的司法大数据资源,人民法院利用传统的数据统计等手段实现了法院精细化管理。在司法大数据简单应用阶段,人民法院通过协议等技术手段与其他领域数据实现了互联互通、拓展融合,对于数据的挖掘进一步加强,通过通用的数据分析技术不仅能够分析某一区域的宏观情况,而且还可以就某一类特定案件或者某一特定要素,例如:时间、地域、人群等,进行多维度、多角度的详细分析,而且对于解决多因素关联和不确定性分析与预测很有优势。
3.在司法大数据的复杂应用中,传统的分析特定要素和案件之间的关联,并得出要素对于案件结果影响的数据分析方法,已不能满足分析类案特点、揭露纠纷根源和成因、为多元纠纷解决机制资源配置提供参考。在这种情况下,如何建立起案件、案由、罪名到当事人、案情、裁判、法官等要素,再到案件时间、空间、特征等变量的映射关系和量化计算模型,成为了有待解决的问题。
4.现有的司法大数据分析技术与模型主要是面向法院内部的审判管理以及针对案情的某一特征来进行汇总统计及可视化分析,主要是基于收结案数量来进行分析预测,其分析的数据主要是源于已有的司法信息化数据法标库,包括组织结构、人员构成、案件统计、立案信息、承办法官、审限变更情况等案情特征信息数据,能够分析的案件关联属性较为固定,一些和实际案情相关的数据并不能获取,而这些数据主要集中反映在司法卷宗或文书内容中;同时现有的一些对案件量的预测分析也主要是采用简单的神经网络技术,仅仅考虑较少的分析维度,如案件数量、经办法院等指标进行回归预测,预测的准确性还不够高,无法很好的通过分析预测、通过多维数据去反映更深层次的问题。
技术实现要素:
5.针对现有技术中存在的问题,本发明的目的在于提供一种基于司法大数据多特征映射的案件量预测方法及系统。本发明主要利用人工智能神经网络技术来改进原有司法数据的获取及预测方法。本发明通过对更多的案件案情实体属性数据进行多维度的全面分析,更加准确预测相关案件量,在此基础上通过模型预测相关指标案件量,以此对经济社会运行难点和法院审判执行运行重点进行分析,为政府与法院的决策者提供更加科学的、全面的决策参考,从而达到辅助司法裁判、助力司法管理、化解矛盾纠纷、服务社会治理的研究目的。
6.本发明的技术方案为:
7.一种基于司法大数据多特征映射的案件量预测方法,其步骤包括:
8.1)收集所选法院司法案件的司法案件特征数据,包括结构化特征属性数据和非结构化文书特征属性数据;
9.2)收集每一所选法院所对应城市的经济侧数据;
10.3)利用所述司法案件特征数据、经济侧数据训练cnn-lightgbm预测模型;所述cnn-lightgbm预测模型包括对输入数据依次进行处理的输入层、第一卷积层、第一池化层、第二卷积层、第二池化层、flatten层、lightgbm模型及输出层,所述输入层用于对输入数据按照地域和时间维度进行数据融合,并对融合后的数据进行归一化处理;所述卷积层用于对收到的数据进行特征提取和特征映射;所述池化层用于对第二卷积层的输出特征进行压缩;所述flatten层对第二池化层输出的数据转换为一维数据;所述lightgbm模型用于对输入数据进行回归预测,预测结果经所述输出层输出;
11.4)将所选法院中一法院a的司法案件特征数据和该法院a所对应城市的经济侧数据输入训练后的cnn-lightgbm预测模型,预测得到该法院a未来一段时间内的案件量。
12.进一步的,训练所述cnn-lightgbm预测模型的方法为:
13.21)对结构化特征属性数据、非结构化文书特征属性数据和经济侧数据分别进行归一化;
14.22)将归一化后的结构化特征属性数据、非结构化文书特征属性数据和经济侧数据按照地域及法院划分为n个集合f={f1,f2,...,fn},n为所选法院总数,fn为第n个法院的结构化特征属性数据、非结构化文书特征属性数据和经济侧数据;将集合f按照设定时间周期划分多个案件特征集和案件量数据集et,xt;et为第t个时间周期内所选n个法院对应的关联属性特征集数据集;对数据集{e1,e2,...,et}求均值、标准差,得到归一化的关联属性特征数据集;xt为第t个时间周期内所选n个法院的案件数量集;对数据集{x1,x2,...,xt}求均值、标准差,得到归一化的历史案件数量;
15.23)将步骤22)所得归一化的历史案件数量和关联属性特征数据集输入到cnn模型中进行预训练,得到cnn模型中卷积层、池化层的参数;
16.24)将训练所得cnn模型中卷积层、池化层的参数作为所述第一卷积层、第二卷积层、池化层的参数并冻结,替换全连接层为lightgbm;然后利用步骤22)所得归一化的历史案件数量和关联属性特征数据集对所述cnn-lightgbm预测模型进行训练。
17.进一步的,所述cnn-lightgbm预测模型中的全连接层替换为lightgbm模型。
18.进一步的,通过人工智能命名实体识别技术,在所述司法案件的裁判文书中提取关联属性特征数据作为所述非结构化文书特征属性数据。
19.进一步的,所述非结构化文书特征属性数据包括案件的争议焦点、作案手段、作案动机。
20.进一步的,所述结构化特征属性数据包括案件特征属性数据和当事人属性特征数据;所述案件特征属性数据包括案件的经办法院、立案日期、案号、案件结案方式、审理周期、适用程序、审限信息、陪审信息;所述当事人属性特征数据包括当事人的年龄、性别、案件地位、职业。
21.进一步的,所述经济侧数据包括常驻人口数、城镇化人口数、民用汽车保有量、金融体量、旅游人口、gdp。
22.一种基于司法大数据多特征映射的案件量预测系统,其特征在于,数据获取单元
和cnn-lightgbm预测模型;其中,
23.数据获取单元,用于收集所选法院司法案件的司法案件特征数据,包括结构化特征属性数据和非结构化文书特征属性数据;以及收集每一所选法院所对应城市的经济侧数据;
24.cnn-lightgbm预测模型,包括对输入数据依次进行处理的输入层、第一卷积层、第一池化层、第二卷积层、第二池化层、flatten层、lightgbm模型及输出层;所述输入层用于对输入数据按照地域和时间维度进行数据融合,并对融合后的数据进行归一化处理;所述卷积层用于对收到的数据进行特征提取和特征映射;所述池化层用于对第二卷积层的输出特征进行压缩;所述flatten层对第二池化层输出的数据转换为一维数据;所述lightgbm模型用于对输入数据进行回归预测,预测结果经所述输出层输出。
25.本发明的优点如下:
26.针对司法大数据复杂应用,本发明创造性地提出了一种司法案件量的分析预测模型,综合考虑各个分类案件相关历史数据的多维影响因素以及本地经济侧数据,通过神经网络机器学习的方法构建相关指标模型,并预测分析相关指标在下一个时间周期的可能值,以此对经济社会运行难点和法院审判执行运行重点进行分析,分析类案特点、揭露纠纷根源和成因、为多元纠纷解决机制资源配置提供参考,打破数据仅为法院提供服务的壁垒,设法进入社会综合治理领域,为政府与法院的决策者提供更加科学的、全面的决策参考。
附图说明
27.图1为多特征映射模型结构图。
28.图2为cnn模型结构示意图。
29.图3为cnn-lightgbm模型结构示意图。
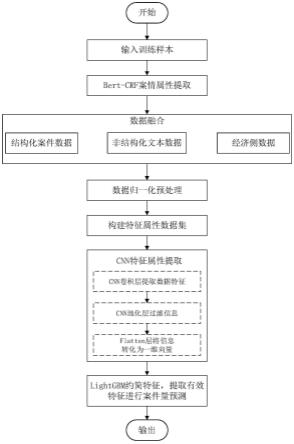
30.图4为本发明预测方法流程图。
具体实施方式
31.下面结合附图对本发明进行进一步详细描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
32.本发明依据多特征映射模型对相应模型指标下案件量进行分析预测,以此对经济社会运行难点和法院审判执行运行重点进行分析,具体多特征映射模型结构如图1所示;具体指标的创建及预测方法,包括以下步骤:
33.1)收集案件结构化特征属性数据。依据《人民法院信息系统建设技术规范2009版》(以下简称“09法标”)和《人民法院信息系统建设技术规范2015版》(以下简称“15法标”),汇聚融合09法标和15法标下不同案件类型的案件数据,案件类型包括:刑事、民事、行政、执行、赔偿;依据案号和收案日期去除重复的案件数据,提取研究需要的案件特征属性数据,包括案件的经办法院、立案日期、案号、案件结案方式、审理周期、适用程序、审限信息、陪审信息等特征,同时提取案件相关的当事人年龄、性别、案件地位、职业等案件当事人属性特征数据;
34.2)收集案件非结构化文书特征属性数据。通过人工智能命名实体识别技术,在裁判文书中提取争议焦点、作案手段、作案动机等关联属性特征数据信息,挖掘非结构化案情
信息,从而有效扩展数据分析维度,并深入结合案情实际特征。
35.bert(bidirectional encoder representation from transformers)模型是google于2018年下半年提出的一种语言表示模型。bert模型在11种不同nlp测试中获得了最佳成绩。bert方法使得模型的训练成为一个端到端的过程,不依赖于特征工程,是一种数据驱动的方法,但这种方法的一个缺点是对每个特征打标签的过程是独立的进行,不能直接利用上文已经预测的标签(只能靠隐含状态传递上文信息),进而导致预测出的标签序列可能是无效的,但在bert输出层接入条件随机场(conditional random field,crf)进行结构化标签预测,可使得标注过程不再是对各个特征的独立分类。
36.输入的句子si=[w1,w2,w3,
…
wn],经过字符分割后经过字符编码e
iw
=[e
[cls]
,e
w1
,e
w2
,
…
,e
[sep]
],增加位置编码ep和句编码信息es后输入深度学习预训练模型bert,输出最后一层得到的高维特征向量h
l
,解码层首先通过一层全连接网络,对每个字符的高维特征向量进行预测,计算该字符属于各个标签的得分之后通过crf模型对预测标签序列进行结构化预测,解码综合得分函数为:
[0037][0038]
其中,a是输出标签之间的转移得分矩阵,对应标签i到标签j的得分。对输入h的所有可能的输出标签序列,得到预测标签序列y的概率:
[0039][0040]
为了使得综合得分最大化,一般取预测输出标签序列概率的对数:
[0041][0042]
其中,y
x
代表输入隐含状态对应所有可能的输出标签序列空间。
[0043]
在已知模型时,给输入序列求预测输出序列即求使目标函数最大化的最优序列,是一个动态规划问题,可以使用viterbi算法解码来得到最优标签序列。根据上述公式,最大得分对应的输出标签序列即为最优的预测标签序列。
[0044][0045]
考虑任意两个标签之间的转移关系,上述最优解采用动态规划进行求得,具体采用维特比算法进行解码。经过解码后得到句子的字符序列标注结果y,y=(y[cls],y1,y2,y3,
…yn
,y
[sep]
)。
[0046]
具体地,非结构化文书主要包括案件当事各方的陈述、法院认定事实、法院说理及裁判结果这三种段落类型,案件当事各方的陈述虽描述了一定的客观事实,但由于都带有一定的主观性,可能会存在陈述矛盾的事实;法院说理及裁判结果集中在依据法律规范进行裁判主文的论证;法院认定事实,基于案件审理中举证质证情况,描述了影响案件裁判结果的事实。因此,以案件基本信息为基础,围绕法院认定事实文本进行案情分析是非常有必要与合理的。我们以刑事案由“盗窃”一审判决书为研究对象,经过和法律专家研究和讨论,
并结合实际文书和现行的法律规范,确定该案由下司法判决书中普遍存在并有重要意义的实体,最终,我们在该案由下预定义了27类实体类型,如表1所示。
[0047]
表1实体预定义
[0048][0049][0050]
考虑到司法能力水平和文书写作规范也会存在一些区别,针对不同省份随机选取100份公开的判决书作为研究的原始文书数据。数据集经过脱敏处理后,我们采用开源的标注工具brat进行部署与配置,以实现多人在线进行实体和关系的标注,将裁判文书进行分句处理并导入标注系统,进行人工标注。对人工标注数据集,进行训练集、测试集划分,结果如下表所示。
[0051]
表2结果集
[0052]
数据集实体任务数据量关系任务数据量训练集56819756测试集13132314
[0053]
在该数据集上对bert-crf进行了验证,通过实验发现该模型平衡f分数值可以达到81.9。通过对模型的不断学习优化,再结合结构化案件数据进行最终数据质量提升,我们可以较为准确的获取到相关案件的关联属性实体数据。
[0054]
3)收集各地经济侧数据,以各级法院为维度,收集该法院所对应城市的常驻人口数、城镇化人口数、民用汽车保有量、金融体量、旅游人口、gdp等,与法院对应的所有案件特
征数据组成一组数据集,统一用于分析预测。
[0055]
4)采用cnn-lightgbm预测模型来预测下一周期案件量,模型整体结构如图3所示。
[0056]
卷积神经网络(cnn)是常用的深度学习算法,可以学习大量输入与输出之间的映射关系,有着较高预测精度。cnn的核心是卷积层,包含许多不同的卷积核用以提取各种特征,池化层与卷积层协作以减少参数数量,加快计算速度。最后,卷积内核提取的大量特征都被传递到全连接层,用于组合先前提取的特征以实现最终预测。通过这种方式,可以获取数据的隐含信息,以实现更快、更稳定的预测。
[0057]
但是,较深的cnn模型计算时间长、容易出现过拟合现象,难以取得好的效果;而使用太浅的模型往往不能有效提取因素之间的相互作用特征,导致计算精度不够,而模型的计算深度由卷积结构的多少决定,通过实验发现,选2个卷积层时准确率最高,误差也最小,因此确定模型结构主要包括了2个卷积层、2个池化层、1个flatten层、1个全连接层及1个输出层。其中输入层用于数据的输入,将1)、2)、3)得到的数据按照地域和时间维度进行数据融合,同时对融合后的数据进行归一化处理;卷积层对输入数据进行特征提取和特征映射,进行特征提取后,需要处理的信息就急剧减少,可以极大的加快运行速度;池化层将卷积层的输出特征进行压缩,降低计算量,增强鲁棒性,并且减少了参数的数量,防止过拟合现象的发生;将池化层的数据输出到flatten层时,数据仍然是多维的,而全连接层要求输入的数据必须是一维的,因此,在flatten层我们必须把输入数据“压扁”成一维后才能进入全连接层;flatten数据输出到全连接层,每一个结点都与flatten层的所有结点相连,用来把前边提取到的特征综合起来,用于回归预测,最终将结果输出到输出层,cnn模型结构如图2所示。
[0058]
同时cnn中的全连接层有一定局限性,如果系统中的参数量太多,不仅会拖慢训练速度,还会导致过拟合问题,在数据量较大时,会导致耗时过长,因此需要用更强的分类器来代替全连接层来解决。lightgbm是一种基于梯度提升树(gbdt)的数据模型,可在不降低预测精度的同时,大幅提高预测速度,降低内存使用率。同时,该提升树是一个弱分类器,可有效防止过拟合问题的出现。在减少训练数据方面,lightgbm算法采用leaf-wise生长策略。leaf-wise是每次只选择增益最大的节点进行分裂,增大了分裂效率。此外,还需使用额外的参数限制决策树的深度,避免过拟合。
[0059]
通过实验,最终得到较好的参数如下:
[0060]
num_leaves:叶子的数目,该参数是控制生成树大小的重要因素,设置为118。
[0061]
min_data_in_leaf:这是处理leaf-wise树的过拟合问题中一个非常重要的参数,默认值是20。它的值取决于训练数据的样本个数和num_leaves。将其设置的较大可以避免生成一个过深的树,但有可能导致欠拟合,实验测试使用28。
[0062]
max_depth:生成树的深度,树的深度与学习特征的能力成正比,与模型的泛化能力成反比。可以利用max_depth来限制树的深度,实验中设置为10。
[0063]
learning_rate:学习率,学习率的取值在[0,1)之间,一般学习率和迭代次数成反比。学习率越小,模型的泛化能力越高,但训练时间越长,实验中设定为0.01。
[0064]
其它参数取默认值。
[0065]
结合cnn挖掘数据空间特性与lightgbm快速高效的预测特性,构造出cnn-lightgbm案件量预测模型,模型整体结构如图3所示。
[0066]
算法的具体步骤如下,整体预测算法流程如图4所示。
[0067]
4.1)数据融合、归一化。案件特征数据、非结构化文本数据、经济侧数据等具有不同的量纲和数量级,如果在模型中直接输入原始数据,在综合分析中数值相对较高因素被增强,而数值相对较低的因素则被削弱。因此,为了保证实验结果的真实性和准确性,需要对原始数据进行标准化处理,即对数据同趋势化处理和无量纲化处理。
[0068][0069]
式中:x(p,i)——表示特征p中第i个因素经过归一化之后的值;
[0070]
x0(p,i)——表示特征p中第i个因素的值;
[0071]
x
max
(i)——表示第i个因素中的最大值;
[0072]
x
min
(i)——表示第i个因素中的最小值。
[0073]
4.2)构建特征属性数据集。根据多特征映射模型结构,选择相关指标的特征属性数据,如道路交通安全管控风险指标,我们选择案由为危险驾驶罪、交通肇事罪、机动车交通事故责任纠纷等的案件结构化特征属性数据及非结构化文书中得到的相关特征属性数据,并结合经济侧数据,如本地民用汽车保有量、常住人口等数据构建关联特征数据矩阵。具体地,将1)、2)和3)得到的相关数据按照地域及法院结构划分为n个集合f={f1,f2,...,fn}(n表示要研究的n个法院);同时将数据集合f以月为单位划分成一系列时间序列集合,时间序列集合定义为t={t1,t2,
…
,tm}(m表示特定的月份),案件数据集合以月为颗粒度进行划分更能集中反映出数据的规律,而且可以将数据规模有效降低;构建前t时间范围的包括所述案件数量及其关联属性特征数据的历史记录值{x1,x2,...,xt}和{e1,e2,...,et},其中xi是i时刻所有法院案件数量的向量矩阵,ei是i时刻所有法院的关联属性特征数据矩阵,根据数据集{x1,x2,...,xt}和{e1,e2,...,et}分别求均值和标准差,从而得到归一化的历史案件数量和关联属性特征数据集。
[0074]
4.3)将(4.2)预处理后的数据输入到构建好的cnn模型中进行预训练,得到卷积层和全连接层的参数。
[0075]
4.4)冻结cnn模型卷积层的参数,将flatten层的数据输入到lightgbm模型中,对模型进行再训练,由lightgbm模型进行对案件量的预测。
[0076]
尽管为说明目的公开了本发明的具体实施例,其目的在于帮助理解本发明的内容并据以实施,本领域的技术人员可以理解:在不脱离本发明及所附的权利要求的精神和范围内,各种替换、变化和修改都是可能的。因此,本发明不应局限于最佳实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1