通过排序分析检测数值程序中高浮点误差的方法及系统
1.本发明属于计算机科学与技术中的高性能计算领域,具体涉及一种通过排序分析检测数值程序中高浮点误差的方法及系统。
背景技术:
2.根据ieee-754标准,浮点数是离散的,实数是连续的。浮点数使用有限的精度表示实数,二者之间存在的舍入误差称为浮点误差。对于具体的某一涉及大量浮点运算的数值程序而言,在大量浮点运算的过程中,数值程序的浮点误差的累积可能会造成高浮点误差,使数值程序最终结果与预期结果不符。在关键系统中,高浮点误差一旦触发,可能会导致灾难性后果。已知的例子有股市混乱、错误的选举结果、火箭发射失败,温哥华证券交易所和斯利普纳海上平台沉没,更有可能造成生命危险。例如在第一次波斯湾战争中,爱国者导弹因为在连续跟踪和制导过程中累计了浮点误差,未能拦截来袭的导弹,造成28人死亡,约100人受伤。若在系统运行前检测出可能触发高浮点误差的输入可以避免很多不必要的损失。
3.为检测数值程序中可能触发高浮点误差的输入,需要对整个浮点输入域进行搜索。64位双精度浮点数可以表示一个接近(-1.8
×
10
308
,1.8
×
10
308
)的空间,所以在整个浮点输入域上的搜索成本是非常大的。现有的检测高浮点误差的方法包括:(1)bgrt:二进制指导随机测试,每次迭代将输入域划分为相同大小的两部分,并在抽样测试结果中选择浮点误差较大的部分;(2)lsga:局部敏感基因算法,基于实证分析的结果提取启发式规则设计了一种新的遗传算法用于指导浮点误差搜索;(3)eagt:误差分析指导测试,从误差分析和全局搜索中提取通用启发式规则并利用近似计算减少测试时间开销;(4)demc:将搜索空间划分为更小的部分,基于条件数指导,使用差分进化算法和马尔科夫链蒙特卡洛算法两种全局优化算法来找到可能触发高浮点误差的输入;(5)atomu:基于分析和理解浮点操作过程中如何引入、传播、放大误差的情况下,利用其提出的原子条件及数学上严格分析的条件数,有效地指导搜索大的浮点误差。但是,上述方法存在下述技术问题:(1)bgrt:在每次迭代中丢弃一半的搜索空间,由于采样不完全,实际上包含精确的更高误差的部分可能会被丢弃,这导致局部最大值和低稳定性,特别是对于较大的搜索空间;(2)lsga:未考虑到特定的精度操作不是通用的,这可能导致很高的误报率;(3)eagt:使用全局搜索而非穷举搜索,不能保证触发的是最高浮点不准确性;(4)demc:搜索成本较大且未处理整个浮点输入域;(5)atomu:找到的输入点触发的浮点误差在其邻域内并不总是最大误差。因此,对于快速减少搜索空间以加速搜索数值程序中可能触发高浮点误差这一过程,已成为一项亟待解决的关键技术问题。
技术实现要素:
4.本发明要解决的技术问题:针对现有技术的上述问题,提供一种通过排序分析检测数值程序中高浮点误差的方法及系统,本发明基于提出的搜索指导函数对每个被划分的
区间进行全面、有效的筛选从而得到最有可能触发高浮点误差的几个区间,在确保高浮点误差检测正确性的基础上极大的提升了性能,能够快速减少搜索空间以加速搜索过程。
5.为了解决上述技术问题,本发明采用的技术方案为:
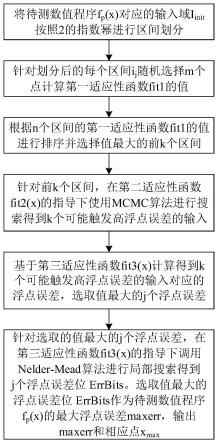
6.一种通过排序分析检测数值程序中高浮点误差的方法,包括:
7.s101,将待测的数值程序f
p
(x)对应的输入域i
init
按照2的指数幂进行区间划分;
8.s102,针对划分后的每个区间ij随机选择m个点计算第一适应性函数fit1的值,根据n个区间的第一适应性函数fit1的值进行排序并选择值最大的前k个区间;
9.s103,针对前k个区间,在第二适应性函数fit2(x)的指导下使用蒙特卡洛采样算法进行搜索得到k个可能触发高浮点误差的输入;然后基于第三适应性函数fit3(x)计算得到k个可能触发高浮点误差的输入对应的浮点误差,选取值最大的j个浮点误差;
10.s104,针对选取的值最大的j个浮点误差,在第三适应性函数fit3(x)的指导下调用nelder-mead算法进行局部搜索得到j个浮点误差位errbits,从j个浮点误差位errbits中选取值最大的一个浮点误差位errbits作为待测数值程序f
p
(x)的最大浮点误差maxerr,输出最大浮点误差maxerr及其相应的点x
max
。
11.可选地,步骤s101包括:
12.s201,创建空的列表;
13.s202,确定区间[0,2-1022
]和[-2-1022
,0];
[0014]
s203,针对确定的区间[0,2-1022
]和[-2-1022
,0],从循环变量i=-1022开始,每次将[2i,2
i+1
]和相应的相反区间加入列表,直到循环变量i=1022,最终划分得到4092个区间。
[0015]
可选地,步骤s102中第一适应性函数fit1的函数表达式为:
[0016]
fit1(x)=sexp(max(f
p
(x)))-sexp(min(f
p
(x)))
[0017]
上式中,x表示区间内m个点x1~xm构成的点集合,f
p
(x)={f
p
(x1),f
p
(x2),...,f
p
(xm)}表示点集合通过待测的数值程序f
p
(x)计算得到的结果集合,f
p
(x1),f
p
(x2),...,f
p
(xm)分别为m个点x1~xm通过待测的数值程序f
p
(x)计算得到的结果,sexp返回一个浮点数的有符号指数以用于避免两个浮点数的运算出现浮点异常,max为取最大值,min为取最小值。
[0018]
可选地,步骤s103中第二适应性函数fit2(x)的函数表达式为:
[0019]
′
[0020]
fit2(x)=|x|
·
|f
p
(x)|/|f
p
(x)|
[0021]
上式中,f(x)表示基准数学函数,f
p
(x)表示待测的数值程序,errbits{f(x),f
p
(x)}表示log2[f(x)和f
p
(x)间的浮点数个数],用于反映出f(x)]和f
p
(x)两点之间浮点误差大小。
[0022]
可选地,步骤s103中第三适应性函数fit3(x)的函数表达式为:
[0023]
fit3(x)=errbits{f(x),f
p
(x)}
[0024]
上式中,f(x)表示基准数学函数,f
p
(x)表示待测的数值程序,errbits{f(x),f
p
(x)}表示先计算f(x)和f
p
(x)两个点之间的浮点数数量、再对该浮点数数量取log2对数,用于反映出f(x)和f
p
(x)两点之间浮点误差大小。
[0025]
此外,本发明还提供一种通过排序分析检测数值程序中高浮点误差的系统,包括:
[0026]
划分程序单元,用于将待测的数值程序f
p
(x)对应的输入域i
init
按照2的指数幂进
行区间划分;
[0027]
排序程序单元,用于针对划分后的每个区间ij随机选择m个点计算第一适应性函数fit1的值,根据n个区间的第一适应性函数fit1的值进行排序并选择值最大的前k个区间;
[0028]
搜索程序单元,用于针对前k个区间,在第二适应性函数fit2(x)的指导下使用蒙特卡洛采样算法进行搜索得到k个可能触发高浮点误差的输入;然后基于第三适应性函数fit3(x)计算得到k个可能触发高浮点误差的输入对应的浮点误差,选取值最大的j个浮点误差;针对选取的值最大的j个浮点误差,在第三适应性函数fit3(x)的指导下调用nelder-mead算法进行局部搜索得到j个浮点误差位errbits,从j个浮点误差位errbits中选取值最大的一个浮点误差位errbits作为待测数值程序f
p
(x)的最大浮点误差maxerr,输出最大浮点误差maxerr及其相应的点x
max
。
[0029]
可选地,所述排序程序单元中第一适应性函数fit1的函数表达式为:
[0030]
fit1(x)=sexp(max(f
p
(x)))-sexp(min(f
p
(x)))
[0031]
上式中,x表示区间内m个点x1~xm构成的点集合,f
p
(x)={f
p
(x1),f
p
(x2),...,f
p
(xm)}表示点集合通过待测的数值程序f
p
(x)计算得到的结果集合,f
p
(x1),f
p
(x2),...,f
p
(xm)分别为m个点x1~xm通过待测的数值程序f
p
(x)计算得到的结果,sexp返回一个浮点数的有符号指数以用于避免两个浮点数的运算出现浮点异常,max为取最大值,min为取最小值。
[0032]
可选地,所述搜索程序单元中第二适应性函数fit2(x)的函数表达式为:
[0033]
′
[0034]
fit2(x)=|x|
·
|f
p
(x)|/|f
p
(x)|
[0035]
上式中,|x|
·
|f
′
p
(x)|/|f
p
(x)|为待测的数值程序f
p
(x)的条件数,f
p
(x)为待测数值程序,x为f
p
(x)的输入,f
′
p
(x)为f
p
(x)的导数;
[0036]
所述搜索程序单元中第三适应性函数fit3(x)的函数表达式为:
[0037]
fit3(x)=errbits{f(x),f
p
(x)}
[0038]
上式中,f(x)表示基准数学函数,f
p
(x)表示待测的数值程序,errbits{f(x),f
p
(x)}表示先计算f(x)和f
p
(x)两个点之间的浮点数数量、再对该浮点数数量取log2对数,用于反映出f(x)和f
p
(x)两点之间浮点误差大小。
[0039]
此外,本发明还提供一种通过排序分析检测数值程序中高浮点误差的系统,包括相互连接的微处理器和存储器,所述微处理器被编程或配置以执行所述通过排序分析检测数值程序中高浮点误差的方法。
[0040]
此外,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序用于被微处理器编程或配置以执行所述通过排序分析检测数值程序中高浮点误差的方法。
[0041]
和现有技术相比,本发明主要具有下述优点:本发明方法包括对整个浮点输入域按2的指数次幂进行划分,并基于提出的搜索指导函数对每个被划分的区间进行全面、有效的筛选从而得到最有可能触发高浮点误差的几个区间,在确保高浮点误差检测正确性的基础上极大的提升了性能,能够快速减少搜索空间以加速搜索过程。
附图说明
[0042]
图1为本发明实施例方法的基本流程示意图。
[0043]
图2为本发明实施例方法的原理示意图。
具体实施方式
[0044]
如图1和图2所示,本实施例通过排序分析检测数值程序中高浮点误差的方法包括:
[0045]
s101,将待测的数值程序f
p
(x)对应的输入域i
init
按照2的指数幂进行区间划分;
[0046]
s102,针对划分后的每个区间ij随机选择m个点计算第一适应性函数fit1的值,根据n个区间的第一适应性函数fit1的值进行排序并选择值最大的前k个区间;
[0047]
s103,针对前k个区间,在第二适应性函数fit2(x)的指导下使用蒙特卡洛采样算法进行搜索得到k个可能触发高浮点误差的输入;然后基于第三适应性函数fit3(x)计算得到k个可能触发高浮点误差的输入对应的浮点误差,选取值最大的j个浮点误差;
[0048]
s104,针对选取的值最大的j个浮点误差,在第三适应性函数fit3(x)的指导下调用nelder-mead算法进行局部搜索得到j个浮点误差位errbits,从j个浮点误差位errbits中选取值最大的一个浮点误差位errbits作为待测数值程序f
p
(x)的最大浮点误差maxerr,输出最大浮点误差maxerr及其相应的点x
max
。
[0049]
为了简便,下文中将本实施例通过排序分析检测数值程序中高浮点误差的方法简称为排序分析检测误差方法(rade方法),rade方法的关键思想是快速减少搜索空间以加速搜索。如图2所示,本实施例输入为待测的数值程序f
p
(x)对应的输入域i
init
,待测的数值程序f
p
(x)对应的输入域i
init
即整个浮点输入域,本实施例中步骤s101用于针对整个浮点输入域进行区间划分,具体地,步骤s101包括:
[0050]
s201,创建空的列表;
[0051]
s202,确定区间[0,2-1022
]和[-2-1022
,0];
[0052]
s203,针对确定的区间[0,2-1022
]和[-2-1022
,0],从循环变量i=-1022开始,每次将[2i,2
i+1
]和相应的相反区间加入列表,直到循环变量i=1022,最终划分得到4092个区间以供筛选。本实施例中将步骤s101采用函数partition进行封装,其调用方式为partition(i
init
),调用partition(i
init
)即可针对输入域i
init
按照2的指数幂将其划分为小的区间。如图2所示,步骤s101得到的n个区间分别记为区间i1,区间i2,
…
,区间i
n-1
以及区间in。
[0053]
毫无疑问,搜索所有划分后的4092个区间代价是很昂贵的,这显然是不现实的。步骤s102用于实现对区间的随机采样,本实施例步骤s102中引入了第一适应性函数fit1来实现对区间的随机采样。本实施例步骤s102中第一适应性函数fit1的函数表达式为:
[0054]
fit1(x)=sexp(max(f
p
(x)))-sexp(min(f
p
(x)))
[0055]
上式中,x表示区间内m个点x1~xm构成的点集合,f
p
(x)={f
p
(x1),f
p
(x2),...,f
p
(xm)}表示点集合通过待测的数值程序f
p
(x)计算得到的结果集合,f
p
(x1),f
p
(x2),...,f
p
(xm)分别为m个点x1~xm通过待测的数值程序f
p
(x)计算得到的结果,sexp返回一个浮点数的有符号指数以用于避免两个浮点数的运算出现浮点异常(例如,1.7e
308
–
(-1.7e
308
)将被改为2046+2046以避免溢出),max为取最大值,min为取最小值,从而可以用具有随机抽样的第一适应性函数fit1来快速地对输入的区间进行排序。如图2所示,对于划分后的n个区间,
随机选择m个点计算fit1的值,处理完所有区间后我们将得到fit1(i1)至fit1(in),我们使用排序算法选择值最大的前k个区间进行下一步搜索,即可筛选出fit1(i1)~fit1(ik)。
[0056]
在数值分析领域中,对函数f(x),其条件数c=|x
·f′
(x)/f(x)|。较大的条件数更容易触发高浮点误差,所以我们需要快速计算条件数的值。但实际上,我们不需要知道条件数的确切值,我们只需要条件数的值作为指导,并不使用这个值来计算最终的结果,这意味着一个近似值是可以接受的。因此,我们不需要直接计算数学函数f(x)的相关值,而是选择了数值程序f
p
(x),其计算成本相对较小。为了对最有可能触发高浮点误差的前k个区间进行搜索,我们引入了第二适应性函数fit2(x)。本实施例步骤s103中第二适应性函数fit2(x)的函数表达式为:
[0057]
′
[0058]
fit2(x)=|x|
·
|f
p
(x)|/|f
p
(x)|
[0059]
上式中,|x|
·
|f
′
p
(x)|/|f
p
(x)|为待测的数值程序f
p
(x)的条件数,f
p
(x)为待测数值程序,x为f
p
(x)的输入,f
′
p
(x)为f
p
(x)的导数。如图2所示,第一适应性函数fit1值最大的前k个区间,步骤s103中针对前k个区间,基于fit2(x)的指导我们使用mcmc算法(蒙特卡洛采样算法)进行搜索可以得到k个可能触发高浮点误差的输入,为计算某一点处的浮点误差我们引入了第三适应性函数fit3(x)。具体地,本实施例步骤s103中第三适应性函数fit3(x)的函数表达式为:
[0060]
fit3(x)=errbits{f(x),f
p
(x)}
[0061]
上式中,f(x)表示基准数学函数,errbits{f(x),f
p
(x)}表示先计算f(x)和f
p
(x)两个点之间的浮点数数量、再对该浮点数数量取log2对数,用于反映出f(x)和f
p
(x)两点之间浮点误差大小,也可表示为:errbits{f(x),f
p
(x)}=log2m,其中m为f(x)和f
p
(x)两个点之间的浮点数个数。为检测数值程序f
p
(x)中可能触发的高浮点误差,本实施例中选择mpmath库中的基准数学函数f(x)作为基准。因此本实施例的输入包括基准数学函数f(x)、待测的数值程序f
p
(x)及整个浮点输入域i
init
。在得到k个可能触发高浮点误差的输入后,基于第三适应性函数fit3(x)计算得到k个可能触发高浮点误差的输入对应的浮点误差,我们使用fit3计算得到k个点处的浮点误差,从中选取值最大的j个并保存入数组,即可筛选出fit2(x1)~fit2(xj)。
[0062]
步骤s104是对s103得到的搜索结果的进一步细化,通过将前j个区间中的j个点作为输入,在第三适应性函数fit3(x)指导下调用nelder-mead算法进行局部搜索,最终得到j个浮点误差位errbits,从中选取最大的一个,便找到了可能的最大浮点误差maxerr和相应的点x
max
。如图2所示,最大浮点误差maxerr和相应的点x
max
构成结果(maxerr,xm),点x
max
为触发maxerr时对应的待测数值程序f
p
(x)的输入。
[0063]
本实施例方法处理了所有的浮点输入域。本实施例方法对整个浮点输入域进行划分,并基于搜索指导函数对每个被划分的区间进行全面、有效的筛选。当搜索空间非常大时,本实施例方法仍然可以减少时间开销。首先,本实施例方法在减少搜索空间之前避免了对数学函数f(x)的计算,从而节省了大量的计算时间;其次,rade基于快速计算的引导函数,本实施例方法只使用单一的全局搜索算法(mcmc算法)和局部搜索(nelder-mead方法),这减少了搜索时间。本实施例方法得到了有效的适应性函数。适应性函数fit1和fit2有助于快速减少搜索空间,这使得局部搜索算法可以利用fit3在短时间内找到可能的最大误
差。本实施例采用的rade方法(50/88、32/49)比现有的atomu方法(41/88)和demc方法(22/49)能发现更多高浮点误差。此外,与现有的atomu方法相比,本实施例采用的rade方法发现了14x(42/3)个更大的相对误差。与现有的demc方法相比,26个数值程序中较大的errbits的数量为4x(16/4)。结果表明,本实施例采用的rade方法与现有的atomu方法的稳定性相当,对于大多数存在明显误差的研究对象,本实施例采用的rade方法的稳定性比现有的demc方法好。本实施例采用的rade方法可以在5秒内检测到显著的浮点误差。作为一种黑盒方法,本实施例采用的rade方法比最先进的黑盒方法demc实现了5.25倍的加速。与最先进的白盒方法atomu相比,本实施例采用的rade方法的速度慢了6.85倍,同时在检测更高的浮点误差方面实现了14倍的改进。总而言之,本实施例方法首次在整个浮点输入域引进排序分析从而快速减少搜索空间,提升了单位时间能够搜索的范围,大幅度提高了搜索效率。通过对现有atomu方法深入分析发现其缺点,即找到的输入点触发的浮点误差在其邻域内并不总是最大误差,并对此进行了针对性改进,本实施例中对atomu报告的输入进行改进,从而可以触发更高的浮点误差。
[0064]
此外,本发明还提供一种通过排序分析检测数值程序中高浮点误差的系统,包括:
[0065]
划分程序单元,用于将待测的数值程序f
p
(x)对应的输入域i
init
按照2的指数幂进行区间划分;
[0066]
排序程序单元,用于针对划分后的每个区间ij随机选择m个点计算第一适应性函数fit1的值,根据n个区间的第一适应性函数fit1的值进行排序并选择值最大的前k个区间;
[0067]
搜索程序单元,用于针对前k个区间,在第二适应性函数fit2(x)的指导下使用蒙特卡洛采样算法进行搜索得到k个可能触发高浮点误差的输入;然后基于第三适应性函数fit3(x)计算得到k个可能触发高浮点误差的输入对应的浮点误差,选取值最大的j个浮点误差;针对选取的值最大的j个浮点误差,在第三适应性函数fit3(x)的指导下调用nelder-mead算法进行局部搜索得到j个浮点误差位errbits,从j个浮点误差位errbits中选取值最大的一个浮点误差位errbits作为待测数值程序f
p
(x)的最大浮点误差maxerr,输出最大浮点误差maxerr及其相应的点x
max
。
[0068]
本实施例中,所述排序程序单元中第一适应性函数fit1的函数表达式为:
[0069]
fit1(x)=sexp(max(f
p
(x)))-sexp(min(f
p
(x)))
[0070]
上式中,x表示区间内m个点x1~xm构成的点集合,f
p
(x)={f
p
(x1),f
p
(x2),...,f
p
(xm)}表示点集合通过待测的数值程序f
p
(x)计算得到的结果集合,f
p
(x1),f
p
(x2),...,f
p
(xm)分别为m个点x1~xm通过待测的数值程序f
p
(x)计算得到的结果,sexp返回一个浮点数的有符号指数以用于避免两个浮点数的运算出现浮点异常,max为取最大值,min为取最小值。
[0071]
本实施例中,所述搜索程序单元中第二适应性函数fit2(x)的函数表达式为:
[0072]
′
[0073]
fit2(x)=|x|
·
|f
p
(x)|/|f
p
(x)|
[0074]
上式中,|x|
·
|f
′
p
(x)|/|f
p
(x)|为待测的数值程序f
p
(x)的条件数,f
p
(x)为待测数值程序,x为f
p
(x)的输入,f
′
p
(x)为f
p
(x)的导数;
[0075]
所述搜索程序单元中第三适应性函数fit3(x)的函数表达式为:
[0076]
fit3(x)=errbits{f(x),f
p
(x)}
[0077]
上式中,f(x)表示基准数学函数,f
p
(x)表示待测的数值程序,errbits{f(x),f
p
(x)}表示先计算f(x)和f
p
(x)两个点之间的浮点数数量、再对该浮点数数量取log2对数,用于反映出f(x)和f
p
(x)两点之间浮点误差大小。
[0078]
此外,本实施例还提供一种通过排序分析检测数值程序中高浮点误差的系统,包括相互连接的微处理器和存储器,所述微处理器被编程或配置以执行前述通过排序分析检测数值程序中高浮点误差的方法。此外,本实施例还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序用于被微处理器编程或配置以执行前述通过排序分析检测数值程序中高浮点误差的方法。
[0079]
本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可读存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0080]
以上所述仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1