基于含噪Retinex模型的煤矿低光照图像增强方法
基于含噪retinex模型的煤矿低光照图像增强方法
技术领域
1.本发明涉及图像增强技术领域,尤其涉及一种基于含噪retinex模型的煤矿低光照图像增强方法。
背景技术:
2.煤矿视频监控系统是及时了解井下人员分布状况、掌握机械设备运行工况、提高安全生产管理水平,促进煤矿智能化发展有效工具。然而在正常煤矿井下生产过程中,会产生大量的粉尘,通常会喷洒大量的水雾达到降尘的目的。受粉尘、水雾以及光照环境等诸多因素的影响,采集的图像多呈低光照特点。在低光照条件下受到背光、非均匀光照和弱光的影响,拍摄的图片容易出现低质量现象,如对比度低、图像噪声大、黑暗区域信息丢失、细节模糊等。低光照图像(lli,low-lightimages)会导致许多计算机视觉任务如目标检测、识别及追踪,语义分割,环境动态感知等达不到预期效果,影响后续图像分析与智能决策。因此,研究适用于煤矿井下低光照图像增强、实用性强且鲁棒性高的低光照图像增强技术具有重要意义。
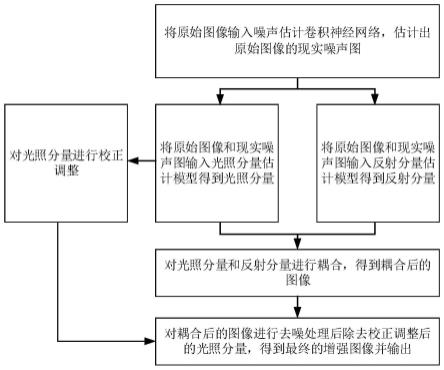
3.retinex模型被广泛用于低光照图像增强,该算法受周围光照条件的影响较小,具有色彩保真度高,图像增强效果更符合人眼感受的优点。在retinex模型基础上研究者们提出了单尺度retinex(single-scale retinex,ssr)、多尺度retinex(multi-scale retinex,msr)、带颜色恢复的msr(multi-scale retinex with color restoration,msrcr)、robustretinex等多种算法模型。但是基于retinex模型方法忽略了噪声,将反射分量结果视为增强后结果的理想假设在受到不同的照明环境影响下并不成立,很难找到一个有效的先验或正则化,且存在增强细节易丢失、色彩失真和对比度不均衡的问题。
技术实现要素:
4.为解决上述技术问题,本发明提供一种基于含噪retinex模型的煤矿低光照图像增强方法。本发明的技术方案如下:
5.一种基于含噪retinex模型的煤矿低光照图像增强方法,其包括如下步骤:
6.s1,将原始图像输入噪声估计卷积神经网络,估计出原始图像的现实噪声图;
7.s2,将原始图像和现实噪声图输入光照分量估计模型得到光照分量,将原始图像和现实噪声图输入反射分量估计模型得到反射分量;
8.s3,对光照分量和反射分量进行耦合,得到耦合后的图像;
9.s4,对光照分量进行校正调整;
10.s5,对耦合后的图像进行去噪处理后除去校正调整后的光照分量,得到最终的增强图像并输出。
11.可选地,所述s1在将原始图像输入噪声估计卷积神经网络,估计出原始图像的现实噪声图时,包括如下步骤:
12.s11,搭建噪声估计卷积神经网络,所述噪声估计卷积神经网络由输入层、三个卷
积核为3
×
3的卷积层且每个卷积层后紧跟一个激活层、紧跟全连接层的全局池化层、紧跟全连接层的激活层、softmax层、卷积核包括3
×
3和7
×
7两个卷积层的多尺度卷积层且每个卷积层后紧跟一个激活层、紧跟一个激活层的卷积核为3
×
3的卷积层、全连接层和输出层构成;
13.s12,将原始图像的rgb三通道图像h
×w×
3转换为尺寸为h/2
×
w/2
×
12的待处理图像;
14.s13,通过三个卷积核为3
×
3的卷积层且每个卷积层后紧跟一个激活层对待处理图像中的特征进行提取,得到转换后的图像特征图,并将转换后的图像特征图转换为与原始图像的rgb三通道图像大小一致的三通道特征图;
15.s14,将原始图像的rgb三通道图像与三通道特征图融合生成h
×w×
6的融合的特征图;
16.s15,将融合的特征图经过紧跟全连接层的全局池化层、紧跟全连接层的激活层和softmax层进行降维处理后,使用卷积核包括3
×
3和7
×
7两个卷积层的多尺度卷积层提取降维处理后的图像中的细节特征,得到细节特征图;
17.s16,通过紧跟一个激活层的卷积核为3
×
3的卷积层、全连接层提取细节特征图的特征,得到原始图像的现实噪声图。
18.可选地,所述s2在将原始图像和现实噪声图输入光照分量估计模型得到光照分量时,包括:
19.s21,搭建光照分量估计模型,所述光照分量估计模型模型包括输入层、卷积层、第一池化层、四个大小不同的残差卷积结构、第二池化层、全连接层和输出层,每个残差卷积结构中每两层构成一个残差块,每个残差块使用多尺度非对称卷积模块进行卷积,且每两个残差块之间融合一个注意力机制模块;
20.s22,原始图像和现实噪声图经过输入层输入后,通过第一卷积层、第一池化层提取图像特征并降维,得到初始特征图;
21.s23,初始特征图先经过第一个残差卷积结构的第一个残差块的第一层非对称卷积模块进行特征提取后,再经过第一个残差卷积结构的第一个残差块的第二层非对称卷积模块继续进行特征提取;
22.s24,将第一个残差卷积结构的第一个残差块输出的特征图经过注意力机制模块处理,从所提取的特征中筛选出关键特征,并经过降维和上采样后输出中间特征图;
23.s25,将中间特征图依次输入第一个残差卷积结构的第二个残差块、注意力机制模块、第三个残差块,直至第四个残差卷积结构的最后一个残差块进行特征提取后,得到最终特征图;
24.s26,最终特征图经过第二池化层和全连接层处理后,经输出层输出原始图像对应的光照分量。
25.可选地,所述s4在对光照分量进行校正调整时,对光照分量进行伽马校正调整。
26.上述所有可选地技术方案均可任意组合,本发明不对一一组合后的结构进行详细说明。
27.借由上述方案,本发明的有益效果如下:
28.通过建立噪声估计卷积神经网络,利用卷积神经网络估计原始图像中的现实噪
声,并将其作为光照分量估计模型和反射分量估计模型的输入来估计光照分量与反射分量,对两个分量进行耦合同时对光照分量进行校正调整后,对调整后的光照分量进行除法运算得到最终的增强图像。由于本发明考虑了现实噪声,能够适应不同条件的低光照环境,确保能够对不同巷道环境下的低光照图像有显著增强,在图像自然度、质量、失真程度、对比度等方面均具有良好的性能。
29.上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。
附图说明
30.图1是本发明的流程图。
31.图2的整体网络模型框架图。
32.图3是本发明中噪声估计卷积神经网络的组成结构示意图。
33.图4是本发明中光照分量估计模型的组成结构示意图。
34.图5是本发明中反射分量估计模型的组成结构示意图。
35.图6是几种不同图像增强方法的增强结果对比图。
36.图7是几种不同图像增强方法对巷道图像的增强结果对比图。
具体实施方式
37.下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
38.如图1所示,本发明提供的一种基于含噪retinex模型的煤矿低光照图像增强方法,其包括如下步骤s1至s4。
39.s1,将原始图像输入噪声估计卷积神经网络,估计出原始图像的现实噪声图。
40.由于噪声对原始图像的光照分量和反射分量的估计具有重要的影响,因此,本发明实施例先对原始图像进行了噪声估计。而对于噪声的估计,通常方法是将噪声建模为加性高斯白噪声(additive white gaussian noise,awgn)或awgn与不同噪声水平的混合噪声。而在低光照条件下拍摄的图像会引入现实场景噪声。这种噪声与图像像素相关,同时会受到相机设置影响,其复杂度比awgn复杂得多,因此,传统的awgn去除方法不能直接处理这种噪声。又由于图像中的噪声方差表现出拜耳模式统计特征,因此,本发明实施例在噪声估计卷积神经网络中使用了拜耳模式特征,提出了一种用于估计现实噪声图的噪声估计卷积神经网络。
41.具体地,所述s1在将原始图像输入噪声估计卷积神经网络,估计出原始图像的现实噪声图时,包括如下步骤s11至s16:
42.s11,搭建噪声估计卷积神经网络(nem),如图2所示,所述噪声估计卷积神经网络由输入层、三个卷积核为3
×
3的卷积层(conv(3
×
3))且每个卷积层(conv(3
×
3))后紧跟一个激活层(relu或bn+relu)、紧跟全连接层(fc)的全局池化层(global pooling)、紧跟全连接层(fc)的激活层(relu)、softmax层、卷积核包括3
×
3和7
×
7两个卷积层的多尺度卷积层且每个卷积层(conv(3
×
3)和conv(7
×
7))后紧跟一个激活层(relu)、紧跟一个激活层(relu)的卷积核为3
×
3的卷积层(conv(3
×
3))、全连接层(fc)和输出层构成。
43.需要说明的是,conv(3
×
3)和conv(7
×
7)仅为本发明实施例示出的一种多尺度卷积层,在具体实施时,可以根据需要选择其它尺度的多尺度卷积层。
44.s12,将原始图像的rgb三通道图像h
×w×
3转换为尺寸为h/2
×
w/2
×
12的待处理图像。
45.具体地,由于图像的rgb三通道所反映的噪声标准差水平呈现不连续性,而是呈现隔行或隔列的连续性,即同一通道反映的噪声水平为连续的,其反映的噪声水平是像素级的噪声水平。因此,本发明实施例在对现实噪声进行估计时,按照拜耳模式进行下采样操作,以将原始图像转换为方便噪声估计的4d向量,即将原始图像的rgb三通道图像h
×w×
3转换为尺寸为h/2
×
w/2
×
12的张量。
46.s13,通过三个卷积核为3
×
3的卷积层且每个卷积层后紧跟一个激活层对待处理图像中的特征进行提取,得到转换后的图像特征图,并将转换后的图像特征图转换为与原始图像的rgb三通道图像大小一致的三通道特征图。
47.三通道图像的尺寸为h
×w×
3。
48.s14,将原始图像的rgb三通道图像与三通道特征图融合生成h
×w×
6的融合的特征图。
49.该步骤的目的是学习原始图像的真实噪声特征。
50.s15,将融合的特征图经过紧跟全连接层的全局池化层、紧跟全连接层的激活层和softmax层进行降维处理后,使用卷积核包括3
×
3和7
×
7两个卷积层的多尺度卷积层提取降维处理后的图像中的细节特征,得到细节特征图。
51.其中,多尺度卷积层能扩大卷积滤波器的感受野,平衡去噪性能和计算复杂度。
52.s16,通过紧跟一个激活层的卷积核为3
×
3的卷积层、全连接层提取细节特征图的特征,得到原始图像的现实噪声图。
53.s2,将原始图像和现实噪声图输入光照分量估计模型(iem)得到光照分量,将原始图像和现实噪声图输入反射分量估计模型(rem)得到反射分量。
54.根据retinex模型,人眼视觉或摄像设备所感知的信息是由物体本身的反射分量和光照分量决定的,传统通过retinex模型进行图像处理时往往忽略了噪声影响,这往往导致处理效果不好,本发明在基于retinex模型进行图像增强时,考虑了噪声的影响,因此,将原始图像和现实噪声图输入光照分量估计模型计算光照分量,将原始图像和现实噪声图输入反射分量估计模型计算反射分量。
55.其中,所述s2在将原始图像和现实噪声图输入光照分量估计模型得到光照分量时,包括如下步骤s21至s26。
56.s21,搭建光照分量估计模型,如图4所示,所述光照分量估计模型以resnet卷积网络作为图像特征的提取网络,在其基础上融合多尺度非对称卷积模块与注意力机制模块。所述光照分量估计模型模型包括输入层、卷积层、第一池化层、四个大小不同的残差卷积结构、第二池化层、全连接层和输出层,每个残差卷积结构中每两层构成一个残差块,每个残差块使用多尺度非对称卷积模块进行卷积,且每两个残差块之间融合一个注意力机制模块。
57.s22,原始图像和现实噪声图经过输入层输入后,通过第一卷积层、第一池化层提取图像特征并降维,得到初始特征图。
58.s23,初始特征图先经过第一个残差卷积结构的第一个残差块的第一层非对称卷积模块进行特征提取后,再经过第一个残差卷积结构的第一个残差块的第二层非对称卷积模块继续进行特征提取。
59.其中,为了能够高效提取低光照图像特征,本发明实施例设计了非对称卷积模块(asymmetricconvolutionmodule,acm),非对称网络能够在降低计算负载的情况下显著增强网络的特征提取能力。本发明实施例中,acm非对称网络采用卷积尺寸为3
×
3与5
×
5两层非对称结构,其中每个非对称结构包括两个并列非对称网络。例如在3
×
3非对称结构中,输入特征首先经过conv(3
×
3)卷积模块;后经过并列非对称网络即conv(1
×
3)与conv(3
×
1)、conv(3
×
1)与conv(1
×
3);最后将两个并列非对称网络结果通过conv(3
×
3)卷积模块融合,输出非对称卷积结果。acm模块能够从不同规模的特征细节中获得信息,恢复低光照图像的局部细节特征。
60.具体地,第一个残差卷积结构的第一个残差块的第一层非对称卷积模块在进行特征提取时,将初始特征首先经过conv(3
×
3)卷积模块,后经过并列非对称网络即conv(1
×
3)与conv(3
×
1)、conv(3
×
1)与conv(1
×
3)两个并列非对称网络;最后将两个并列非对称网络结果通过conv(3
×
3)卷积模块融合,输出这一层的非对称卷积结果。再经过第一个残差卷积结构的第一个残差块的第二层非对称卷积模块继续进行特征提取时,经过第一个残差卷积结构的第一个残差块的第二层中的5
×
5非对称结构,即先经过conv(5
×
5)卷积模块,后经过并列非对称网络即conv(1
×
5)与conv(5
×
1)、conv(5
×
1)与conv(1
×
5)两个并列非对称网络;最后将两个并列非对称网络结果通过conv(5
×
5)卷积模块融合,输出这一层的非对称卷积结果。。
61.残差卷积结构能够从不同规模的特征细节中获得信息,增加了光照分量估计模型的细节过滤能力。
62.需要说明的是,卷积尺寸为3
×
3与5
×
5两层非对称结构仅为本发明实施例示出的一种非对称卷积模块,在具体实施时,可以根据需要选择其它尺度的非对称卷积模块。
63.s24,将第一个残差卷积结构的第一个残差块输出的特征图经过注意力机制模块处理,从所提取的特征中筛选出关键特征,并经过降维和上采样后输出中间特征图。
64.具体地,在低光照图像中,通常每个图像通道对应像素的亮度增强权重是统一的,但这种操作会使得有局部光源的图像曝光过度,或者图像失真。通道注意力机制能够从特征中筛选出关键信息,通过调节权重大小,使网络关注关键信息。因此,本发明实施例引入注意力机制模块对局部光源进行调节抑制,同时对局部极暗区域进行放大,从而达到均衡增强的效果。
65.进一步地,本发明实施例将acm输出的特征加上注意力机制模块进行融合,使得网络能够从特征中筛选出重要特征信息。
66.s25,将中间特征图依次输入第一个残差卷积结构的第二个残差块、注意力机制模块、第三个残差块,直至第四个残差卷积结构的最后一个残差块进行特征提取后,得到最终特征图。
67.本发明实施例四个大小不同的残差卷积结构同时使用,使得提取的特征更加完善。
68.s26,最终特征图经过第二池化层和全连接层处理后,经输出层输出原始图像对应
的光照分量。
69.进一步地,本发明实施例中,反射分量估计模型的基本结构以及估计过程同上述光照分量,由于反射分量包含了较多的高频信息,因此,如图5所示,本发明实施例的反射分量估计模型在注意力机制模块部分增加了convert(3
×
3)、relu和maxpool3层结构。
70.s3,对光照分量和反射分量进行耦合,得到耦合后的图像。
71.根据retinex理论,人眼视觉或摄像设备所感知的信息是由物体本身的反射分量和光照分量决定的,因此,本发明实施例可以基于retinex理论对光照分量和反射分量进行耦合,得到耦合后的图像。
72.s4,对光照分量进行校正调整。
73.可选地,所述s4在对光照分量进行校正调整时,包括但不限于对光照分量进行伽马校正调整。
74.s5,对耦合后的图像进行去噪处理后除去校正调整后的光照分量,得到最终的增强图像并输出。
75.具体地,最终的增强图像m=(s-n)/,其中,s表示耦合后的图像,n表示现实噪声,i表示光照分量,表示校正调整后的光照分量。如图3所示,其为本发明的整体网络模型框架图。
76.为了验证本发明实施例提供的方法的有效性,下面还提供如下实验结果。
77.本文实验模型使用pytorch框架实现,在ubuntu18,32g内存,3.9ghzcpu,nvidiagtx2080ti计算机进行训练。训练网络模型的batchsize设为20,迭代epoch为60epoch,训练过程使用学习率为10-3
的adam优化器对参数优化。为了训练本文提出的网络模型,制作了煤矿场景数据集,包括矿井图像100张,矿井中设备图像150张,巷道图像100张,多光源场景图像150张,共计500幅图像用于本实验的定性和定量评估。
78.(1)定性评估。
79.为了验证本发明提出的方法的有效性,设计横向对比实验与其他方法进行直观比较,几种不同方法的增强结果如图6所示。在具有一定挑战性的巷道图像中,其光源均为非自然光,有一个或者多光源,且有些图像中物体周围背景为黑色。针对这种黑暗场景图像进行对比分析,retinex-net往往会在黑暗区域产生噪音、伪影,颜色的对比度明显失真。虽然zero-dce的增强质量明显提高,但增强图像的明亮区域也趋于饱和。drbn在黑暗部分和光照强度较高部分对比度调节效果较差。dslr可以将低质量图像还原为高质量图像,但无法去除噪声。tbefn通过一种有高度适应性的双分支模糊策略来增强低光照图像,其在对比度较高的图像中增强效果显著,但在色彩恢复方面效果并不理想。ruas不仅可以保持自然度,而且可以提高对比度,但在光照较强的地方易出现曝光过度的情况。与其它六种方法对比可以看出,本发明实施例提出的方法(图6中的our)能够在保证黑暗增强的效果的基础上,平衡光源与黑暗之间的关系,明显降低现实噪声对图像增强效果的影响。而且能平衡对比度和饱和度,在色彩方面相比其他方法更加真实。
80.最后选择具有代表性的巷道图像进行测试,如图7所示,在该场景下,retinex-net、zero-dce和ruas方法估计结果均受到噪声影响严重失真,ruas对图中方框内光源进行错误估计,导致图像中其他信息被淹没;虽然dslr方法能够较好的对逆光光源进行抑制同时对巷道周围图像进行恢复,但是黑暗部分颜色失真,不能够还原原始场景的样貌。本发明
实施例提出的方法能够在具有挑战的环境下很好的对图像中光源和黑暗部分进行估计,抑制噪声,恢复真实图像。
81.(2)定量评估。
82.为了验证本发明提出的方法的优异性,采用自然图像质量评估指标(niqe)、对比度失真的无参考图像质量指标(niqmc)、峰值信噪比(psnr)和结构相似性(ssim)4种指标对各类算法的增强效果进行定量评估,结果见表1所示的不同方法客观评价结果表。
83.其中,niqe利用图像的自然统计特征来评价图像质量好坏,其值越低表示图像自然度越好,niqe算法与人眼主观质量评价有着更好的一致性,更接近人类视觉系统;niqmc用于对比度失真图像质量评估,它通过适当地结合局部和全局信息,评估对比度失真图像的整体质量估计效果,niqmc值越高表示图像质量越好;psnr是衡量图像失真程度或是噪声水平的客观指标,其值越大,图像失真度越小;ssim从亮度、对比度和结构三方面衡量图像的相似性,其值越大,图像失真越小,越相似。
84.表1
85.[0086][0087]
选择矿井图像、矿井设备图像、巷道图像和多光源场景图像4组(共计500张)煤矿场景数据集。其中80%为实验训练集,20%为测试集,每类测试图像的实验结果指标见表1。从表1可看出:在niqe,niqmc,psnr,ssim参数上,综合4组图像,本发明提出的方法相较于其他算法均取得了更好的结果。本发明提出的方法在niqe,niqmc,psnr,ssim上,相较于retinex-net算法平均提升了-4.06%,27.61%,35.63,37.86%;相较于zero-dce算法平均提升了-9.9%,21.94%,32.06%,36.56%;相较于drbn算法平均提升了-7.11%,13.92%,20.67%,16.56%;相较于dslr算法平均提升了-7.65%,8.74%,30.39%,37.96%;相较于tbefn算法平均提升了-6.22%,10.49%,6.33%,29.24%;相较于ruas算法平均提升了-6.77%,9.76%,0.98%,8.09%。
[0088]
niqe获得了最低分数,表明本发明提出的方法处理后的图像自然度保持最好;niqmc获得了最高分数,表明本发明提出的方法处理的图像质量保持最好,图像受损程度低;psnr也取得了相对较高的分数,说明本发明提出的方法得到的增强图像失真度更小、细节信息更多,同时ssim获得了相对较高的分数,说明本发明提出的方法处理后的图像更加明亮、对比更加鲜明、图像结构保持得相对较好。总之,本发明提出的方法在图像自然度、质量、失真程度、对比度,结构等方面均具有良好的性能,整体相对较优。
[0089]
为进一步验证nem与macam的有效性,设计了消融实验:即没有融合nem与macam的基础网络、融合nem的基础网络、融合macam的基础网络、融合nem与macam的改进网络。选择某一种煤矿场景数据集进行实验,对比以上四种网络,niqe、niqmc、psnr和ssim四种指标的评价结果见表2所示的nem与macam模块性能分析表,融合nem与macam模块的改进网络相较于resnet平均提升了-3.88%,26.86%,34.24%,37.25%;相较于resnet+nem平均提升了-2.4%,13.31%,12.63%,22.81%;相较于resnet+macam平均提升了-1.23%,6.64%,4.54%,12.90%。可以看出改进网络能够明显提高增强图像的这四种指标,所以本发明提出的方法提出的方法对低光照图像增强的整体效果均优于其他方法。
[0090]
表2
[0091][0092]
综上,本发明实施例提供的方法通过建立噪声估计卷积神经网络,利用卷积神经网络估计原始图像中的现实噪声,并将其作为光照分量估计模型和反射分量估计模型的输入。通过在光照分量和反射估计网络中引入了多尺度非对称卷积模块,增加了网络的细节过滤能力,并在多尺度融合过程中引入了注意力机制模块,来估计光照分量与反射分量。对两个分量进行耦合,同时对光照分量进行伽马校正等调整,然后对调整后的光照分量进行除法运算,得到最终的增强图像。由于本发明考虑了现实噪声,能够适应不同条件的低光照环境。针对煤矿巷道低光照环境下的图像进行增强处理,与其他主要方法进行了对比,结果表明,本发明提供的方法能够对不同巷道环境下的低光照图像有显著地增强,在图像自然度、质量、失真程度、对比度,结构等方面均具有良好的性能。
[0093]
以上所述仅是本发明的优选实施方式,并不用于限制本发明,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变型,这些改进和变型也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1