一种织物缺陷检测方法
本发明属于缺陷检测领域,具体涉及一种织物缺陷检测方法。
背景技术:
1、缺陷检测在纺织工业中起着重要作用。传统的织物缺陷检测方法主要依靠人眼来区分不良品,耗时长,误检率高。因此,人工检测不能满足实际生产需要。迫切需要开发自动化的织物缺陷检测方法来应对纺织工业的生产。开发一种通用、高效、可靠、准确的织物缺陷自动检测算法具有重要意义。在过去的几十年中,许多研究人员提出了大量的织物缺陷检测方法。这些方法大致可以分为传统方法和基于学习的方法:
2、1)传统方法:传统的织物缺陷检测方法
3、2)基于深度学习的方法:基于深度学习的织物缺陷检测方法。
4、传统的织物缺陷检测算法主要使用手动特征提取,无法自适应地选择特征来检测复杂场景中的缺陷。近年来,深度卷积神经网络(dcnn)在图像识别、图像分割、目标检测等领域取得了优异的性能。因此,近年来,许多研究人员将cnn应用于织物缺陷检测,并取得了令人满意的结果。多个实验表明在大型工业数据集的训练下,该算法优于其他传统算法。与传统的织物缺陷检测方法相比,深度学习可以提取更丰富的图像特征,具有较强的适应性和检测精度。
5、现今计算机视觉和模式识别技术已广泛应用于工业表面缺陷检测领域。用织物缺陷自动检测算法代替人工视觉,不仅可以提高检测速度,降低人工成本,而且可以通过织物缺陷自动检测系统采集可靠数据,进行报表分析及拓展应用。
6、ross b.girshick(rbg)等人在cnn的基础上设计了r-cnn模型,r-cnn(region-based convolution neural networks)优化了通过多尺度滑动窗口确定所有可能的目标区域的方法和人工选取特征的方法如hog和sift,将候选区域算法selective search和卷积神经网络相结合,在图像中提取2000个候选区域,相较于之前的滑窗法(windowssliding)有很大的提升,使得检测速度和精度明显提升。
7、rcnn的结构实际是卷积层、全连接层。经过多个卷积层的运算,最后得到图像在不同尺度的抽象表示。卷积层的参数规模固定。在卷积层之间周期性插入池化层,其作用是逐渐降低数据体的空间尺寸,能够减少网络中参数的数量,减少计算资源耗费,同时也能够有效地控制过拟合。这个部分就是最后一步了,经过卷积层和池化层处理过的数据输入到全连接层,得到最终想要的结果。激活函数(activation function),就是在人工神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端。
8、基于神经网络的织物缺陷检测取得了良好的检测效果,但在工业实际应用的过程中,这些方法仍存在一定问题。由于织物缺陷的大量特征,类间相似性和类内多样性,在工业生产线中,可能产生数百种类型的缺陷。数据采集通常受到缺陷样品可用性不足和图像标记过程限制的限制,从而对精度产生很大的负面影响。
技术实现思路
1、针对现有技术中存在的不足,本发明提供一种织物缺陷检测方法。
2、一种织物缺陷检测方法,包括如下步骤:
3、步骤一:构建数据集;
4、步骤二:数据集预处理;
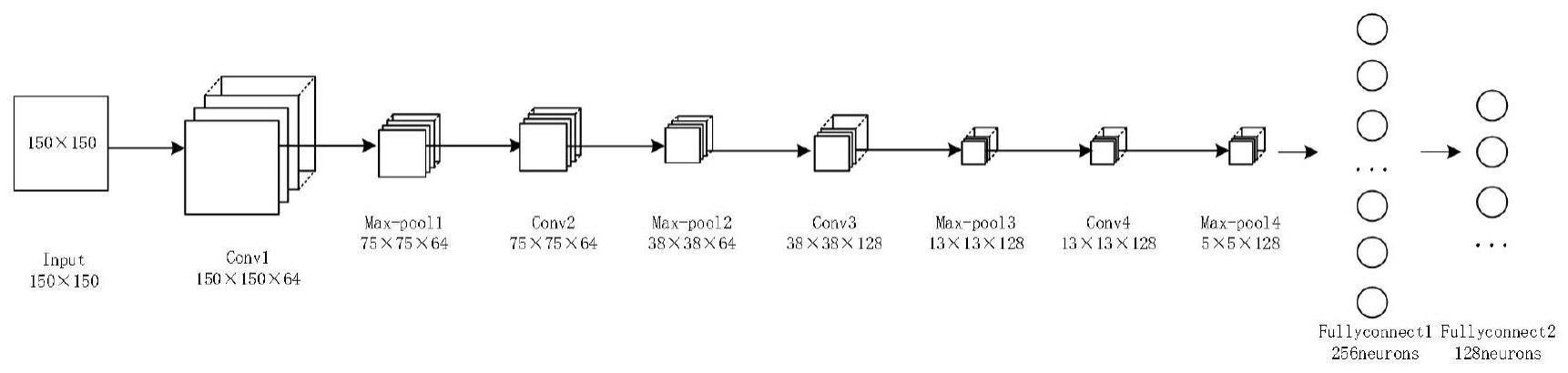
5、步骤三:构建织物缺陷检测r-cnn网络模型;
6、织物缺陷检测r-cnn网络模型由4个卷积层和4个最大池化层,及2个全连接层组成。
7、步骤四:训练织物缺陷检测r-cnn网络模型;
8、步骤五:使用分类阈值降低方法降低fn样本数量;
9、进一步的,步骤一具体方法如下:
10、使用四个不同的数据集。除了现有的tilda,mvtec和stains数据集之外,创建了一个新的自建数据集。所述的自建数据集分为两个部分,分别用于训练和测试阶段。其他三个数据集仅在测试阶段使用。
11、所述自建数据集是用来自两个不同来源的图像构成的,包括来自cottonincorporated的织物缺陷图像的样本和从网络中提取的织物图像。来自cottonincorporated的数据集包含具有6种缺陷类型的194个512×512织物图像,从而可以更广泛地表示织物缺陷类别。为了补充和增加此数据集中的样本数量,从网络中提取织物图像,包括了6个缺陷类型的纹理图像,每个类别包含了200个无缺陷图像样本和10个有缺陷图像样本,每个图像中有且仅有一个缺陷,合计1454张图片作为样本,采用开源工具labelme进行图像标注。
12、进一步的,步骤二具体方法如下:
13、(1)图像大小调整:
14、通过resize函数进行对自建数据集中的图片进行缩放。
15、原始图像宽高比参数为512×512在此基础上缩小并进行测试,并找到适合模型的图像大小,确定输入大小固定为150×150。
16、(2)灰度变换:
17、图像中每个像素灰度值由r,g,b三个单色取加权平均:
18、d=0.299r+0.587g+0.114b
19、将自建数据集中的图像转换为灰度直方图后,像素灰度信息集中于100~200之间,无法突出细节信息。使用灰度直方图均衡化来修正图像中像素灰度。
20、直方图均衡化公式如下:
21、
22、其中,l=256为灰度级数,cdf为累积分布函数,min和max分别为灰度直方图中灰度最小值与最大值。round函数返回点数四舍五入运算后的整数结果。
23、进一步的,步骤三具体方法如下:
24、织物缺陷检测r-cnn网络模型由4个卷积层和4个最大池化层,及2个全连接层组成。
25、每个卷积层后连接一个最大池化层,最后一层最大池化层后依次连接2个全连接层。最大池化层max-pooling卷积核的大小是2×2。下表为所有层及超参数,输入图像为150×150×1。
26、 层 输出特征图 超参数 conv1 150×150×64 f=64,k=5,s=1,p=2 max-pool1 75×75×64 s=2 conv2 75×75×64 f=64,k=5,s=1,p=2 max-pool2 38×38×64 s=2 conv3 38×38×128 f=128,k=3,s=1,p=2 max-pool3 13×13×128 s=3 conv4 13×13×128 f=128,k=3,s=1,p=2 max-pool4 5×5×128 s=3 全连接层1 256 神经元256 全连接层2 128 神经元128
27、其中f是特征图的数量,k对应于卷积核大小kernel_size,s是卷积步长stride,p是填充padding。神经元激活函数为relu。
28、损失函数采用二元交叉熵损失,公式如下:
29、
30、其中yi是标签,值为1;p(yi)是n个样本预测结果,即样本为缺陷图像的概率。
31、进一步的,步骤四具体方法如下:
32、首先进行可视化中间激活,将网络中各个卷积层和池化层输出的特征图进行可视化展示,以验证网络训练情况。使用可视化中间激活的方法有利于显示假阳性和假阴性样本的特征,便于更好地调试模型。
33、设置batch_size让模型在训练过程中每次选择批量的数据来进行处理,提高训练速度,模型batch_size设置为8。
34、使用步骤二预处理后的自建数据集对织物缺陷检测r-cnn网络模型进行训练,直至损失函数达到最佳的收敛程度。然后在上述4个不同的测试数据集上对它们进行测试。
35、进一步的,步骤五具体方法如下:
36、织物缺陷检测r-cnn网络的全连接层2将通过sigmoid输出预测图像为缺陷函数的概率,并将结果映射到二元分类,这个过程中定义缺陷样本为正样本p。此过程中将产生假阴性fn和假阳性fp两类样本。由于实际工业环境下,大批量产品中存在缺陷的织物远小于无缺陷的织物,即阳性样本p的数量将远小于阴性样本n。若操作员对于n和p样本进行复核,数量越大,人工复核纠正的成本越大。
37、在此工作中,测试结果显示织物缺陷检测r-cnn网络分类器给出的fn样本大部分接近分类阈值,高于该阈值则分类为缺陷样本。使用分类阈值降低方法(ctr)后,将被检测系统分类为无缺陷的fn样本重新分类为缺陷样本,减少fn样本出现的频率。此工作用于更好地划分织物样本的正类别与负类别,减少人工复核成本。
38、本发明有益效果如下:
39、本发明创建了包含大多数织物缺陷类型的可靠数据集。提出了一种新的织物缺陷检测r-cnn网络模型。该模型不仅提供了良好的特征检测准确性,且运行成本低,易于实施,可以更好地适用于工业环境下的实际操作情况。本发明提出了一种基于ctr的模型优化方法,用于更好地划分织物样本的正类别与负类别,减少出现的fn结果,提高分类的准确性,降低人工识别产生的成本。
- 还没有人留言评论。精彩留言会获得点赞!