基于候选标签集的语义分割域适应标签纠正方法及装置
1.本发明涉及自动驾驶技术领域,尤其涉及一种基于候选标签集的语义分割域适应标签纠正方法及装置。
背景技术:
2.近些年,随着深度学习在自动驾驶领域的应用不断加深,语义分割作为其中的一个重要研究方向,已经得到了快速的发展。然而语义分割的研究通常仅在晴朗天气下进行,而对于自动驾驶的实际应用场景来说,恶劣天气如雾天,是无法避免的。因此目前的语义分割技术虽然在晴朗天气下的准确性已经能够满足自动驾驶任务的需求,但在雾天下直接使用晴朗天气的模型准确度远远达不到自动驾驶任务的要求,因此需要为雾天场景也训练出相应的模型。但由于雾天数据难以标注,因此能够针对这一情况进行训练的基于自训练的雾天语义分割域适应策略成为了自动驾驶的一个重要课题。
3.近年来,出现了许多优秀的通用语义分割域适应方法,如cbst、crst、proda等。尽管目前的通用语义分割域适应方法在该领域的常用数据集gta5与cityscapes上取得了显著的效果,但仍然有许多严重的问题。首先,这些方法没有在雾天数据集上进行过尝试,无法保证其能够有效地应用于雾天场景,其次这些方法没有深入的探究雾天数据的特点,没有运用这些特点辅助语义分割域适应任务,最后,没有针对可以直接影响模型最终性能的伪标签进行任何优化,没有消除或者缓和伪标签稀疏性与准确性之间的矛盾。
4.过去的几年,有一些工作致力于提高深度学习语义分割域适应模型在雾天场景下的表现。如cmada方法,根据雾的浓度特点,提出了一种基于课程学习的逐步训练方法,该方法有两个步骤,可以从合成的雾图和无标注的真实雾图数据中学习,将模型从晴朗场景逐渐迁移到薄雾、浓雾场景,并在随后扩展了这一思想,将雾的浓度进一步划分,以适应多个自适应步骤来将模型从晴朗场景逐渐迁移到浓雾场景。
5.这些工作虽然都在雾天语义分割域适应问题上取得了不错的表现,但是这些工作仍然存在着几个问题。没有探究雾天场景的特点,没有深入的利用雾天场景的相关信息。为了保证伪标签的可信度,挑选出来的伪标签数量十分稀疏,无法满足模型训练。没有利用雾天场景的特点去纠正伪标签的错误,进一步提高模型的表现。
技术实现要素:
6.为解决上述至少一个技术问题,本发明的主要目的在于提供一种基于候选标签集的语义分割域适应标签纠正方法、装置。
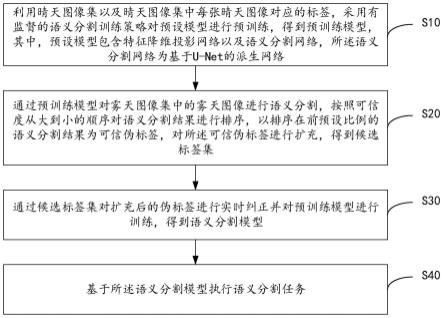
7.第一方面,本发明提供一种基于候选标签集的语义分割域适应标签纠正方法,所述基于候选标签集的语义分割域适应标签纠正方法包括:
8.利用晴天图像集以及晴天图像集中每张晴天图像对应的标签,采用有监督的语义分割训练策略对预设模型进行预训练,得到预训练模型,其中,预设模型包含特征降维投影网络以及语义分割网络,所述语义分割网络为基于u-net的派生网络;
9.通过预训练模型对雾天图像集中的雾天图像进行语义分割,按照可信度从大到小的顺序对语义分割结果进行排序,以排序在前预设比例的语义分割结果为可信伪标签,对所述可信伪标签进行扩充,得到候选标签集;
10.通过候选标签集对扩充后的伪标签进行实时纠正并对预训练模型进行训练,得到语义分割模型;
11.基于所述语义分割模型执行语义分割任务。
12.可选的,雾天图像集为且其中,表示第i张雾天图像,为雾天图像集,ch表示图像颜色通道数,h和w分别表示雾天图像的长度和宽度大小,n
t
表示雾天图像集的大小,r表示实数集,按照可信度从大到小的顺序对语义分割结果进行排序,以排序在前预设比例的语义分割结果为可信伪标签,对所述可信伪标签进行扩充,得到候选标签集的步骤包括:
13.按照语义分割结果的可信度,将雾天图像的语义分割结果划分为三种区域,三类区域的划分方式如下:
[0014][0015]
其中,1、2、3分别表示第一类型候选标签区域、第二类型候选标签区域、第三类型候选标签区域,m(p)表示像素点p属于哪一类型候选标签区域,c表示像素的语义类别为第c类,φ为模型参数,表示像素p预测为第c类的概率,spi表示第i个超像素块,表示像素点p预测结果中置信度最大的分量,λc为预设比例,表示像素点q预测结果中置信度最大的分量,s.t.pandq∈spi表示像素点p和q都属于spi;
[0016]
以第1类型候选标签区域的每个像素的预测置信度中排名前1个类别对应的标签为其候选标签集、以第2类型候选标签区域的每个像素的预测置信度中排名前3个类别对应的标签为其候选标签集、以第3类型候选标签区域的每个像素的预测置信度中排名前5个类别对应的标签为其候选标签集。
[0017]
可选的,通过候选标签集对扩充后的伪标签进行实时纠正并对预训练模型进行训练,得到语义分割模型的步骤包括:
[0018]
步骤3.1,将输入预训练模型中,经过编码器,再分别经过特征降维投影网络得到特征以及分类网络得到语义分割结果其中,表示第i张雾天图像经过编码器以及分类网络得到语义分割结果的过程;
[0019]
步骤3.2,依据第一公式计算每个类别的原型,每个类别原型表示为ψ={ψ1,
…
,ψc,
…
,ψc},其中ψc表示第c类别的原型,类别指语义分割对应的预测的类别,原型指类别的平均特征,第一公式为:
[0020][0021]
其中,表示第i张雾天图像的第p个像素的特征,表示像素p的软标签中第c类的概率,表示指示函数,当括号内结果大于0时为1,否则为0;
[0022]
步骤3.3,根据原型ψ与zi的特征对软标签y
t
进行纠正,如下公式所示:
[0023][0024][0025]
其中,表示像素p的候选标签集,表示类别c对于像素p的权重。
[0026]
||
·
||表示欧式距离;
[0027]
步骤3.4,基于更新后的软标签计算交叉熵损失以及对比学习损失,两种损失分别如下:
[0028][0029][0030]
其中,v表示第i张雾天图像的第p个像素的特征,且p不属于第3类型候选标签区域;v
+
表示特征v的正样本,v-表示v的负样本;表示负样本集合,即所有不属于第3类型候选标签区域的像素q,且像素q的可信度最高的类别不在像素p的候选标签集中的像素的集合;exp(
·
)表示自然对数的底数e的指数运算;
[0031]
步骤3.5,对于晴天图像集,计算对应的标准的交叉熵损失,与步骤5.4的交叉熵损失以及对比学习损失相加后,通过梯度下降的算法进行反向传播,使得预训练模型得到优化;
[0032]
步骤3.6,对于每一张雾天图片都进行上述步骤3.1至3.5的操作,得到语义分割模型。
[0033]
可选的,所述语义分割网络为基于u-net架构的深度学习refinenet语义分割网络。
[0034]
可选的,所述特征降维投影网络包含1个1x1的二维卷积层和relu层。
[0035]
第二方面,本发明还提供一种基于候选标签集的语义分割域适应标签纠正装置,所述基于候选标签集的语义分割域适应标签纠正装置包括:
[0036]
预训练模块,用于利用晴天图像集以及晴天图像集中每张晴天图像对应的标签,采用有监督的语义分割训练策略对预设模型进行预训练,得到预训练模型,其中,预设模型
包含特征降维投影网络以及语义分割网络,所述语义分割网络为基于u-net的派生网络;
[0037]
扩充模块,用于通过预训练模型对雾天图像集中的雾天图像进行语义分割,按照可信度从大到小的顺序对语义分割结果进行排序,以排序在前预设比例的语义分割结果为可信伪标签,对所述可信伪标签进行扩充,得到候选标签集;
[0038]
训练模块,用于通过候选标签集对扩充后的伪标签进行实时纠正并对预训练模型进行训练,得到语义分割模型;
[0039]
执行模块,用于基于所述语义分割模型执行语义分割任务。
[0040]
可选的,雾天图像集为且其中,表示第i张雾天图像,为雾天图像集,ch表示图像颜色通道数,h和w分别表示雾天图像的长度和宽度大小,n
t
表示雾天图像集的大小,r表示实数集,扩充模块,用于:
[0041]
按照语义分割结果的可信度,将雾天图像的语义分割结果划分为三种区域,三类区域的划分方式如下:
[0042][0043]
其中,1、2、3分别表示第一类型候选标签区域、第二类型候选标签区域、第三类型候选标签区域,m(p)表示像素点p属于哪一类型候选标签区域,c表示像素的语义类别为第c类,φ为模型参数,表示像素p预测为第c类的概率,spi表示第i个超像素块,表示像素点p预测结果中置信度最大的分量,λc为预设比例,表示像素点q预测结果中置信度最大的分量,s.t.pandq∈spi表示像素点p和q都属于spi;
[0044]
以第1类型候选标签区域的每个像素的预测置信度中排名前1个类别对应的标签为其候选标签集、以第2类型候选标签区域的每个像素的预测置信度中排名前3个类别对应的标签为其候选标签集、以第3类型候选标签区域的每个像素的预测置信度中排名前5个类别对应的标签为其候选标签集。
[0045]
可选的,训练模块,用于:
[0046]
步骤3.1,将输入预训练模型中,经过编码器,再分别经过特征降维投影网络得到特征以及分类网络得到语义分割结果其中,表示第i张雾天图像经过编码器以及分类网络得到语义分割结果的过程;
[0047]
步骤3.2,依据第一公式计算每个类别的原型,每个类别原型表示为ψ={ψ1,
…
,ψc,
…
,ψc},其中ψc表示第c类别的原型,类别指语义分割对应的预测的类别,原型指类别的平均特征,第一公式为:
[0048]
[0049]
其中,表示第i张雾天图像的第p个像素的特征,表示像素p的软标签中第c类的概率,表示指示函数,当括号内结果大于0时为1,否则为0;
[0050]
步骤3.3,根据原型ψ与zi的特征对软标签y
t
进行纠正,如下公式所示:
[0051][0052][0053]
其中,表示像素p的候选标签集,表示类别c对于像素p的权重。
[0054]
||
·
||表示欧式距离;
[0055]
步骤3.4,基于更新后的软标签计算交叉熵损失以及对比学习损失,两种损失分别如下:
[0056][0057][0058]
其中,v表示第i张雾天图像的第p个像素的特征,且p不属于第3类型候选标签区域;v
+
表示特征v的正样本,v-表示v的负样本;表示负样本集合,即所有不属于第3类型候选标签区域的像素q,且像素q的可信度最高的类别不在像素p的候选标签集中的像素的集合;exp(
·
)表示自然对数的底数e的指数运算;
[0059]
步骤3.5,对于晴天图像集,计算对应的标准的交叉熵损失,与步骤5.4的交叉熵损失以及对比学习损失相加后,通过梯度下降的算法进行反向传播,使得预训练模型得到优化;
[0060]
步骤3.6,对于每一张雾天图片都进行上述步骤3.1至3.5的操作,得到语义分割模型。
[0061]
可选的,所述语义分割网络为基于u-net架构的深度学习refinenet语义分割网络。
[0062]
可选的,所述特征降维投影网络包含1个1x1的二维卷积层和relu层。
[0063]
本发明中,利用晴天图像集以及晴天图像集中每张晴天图像对应的标签,采用有监督的语义分割训练策略对预设模型进行预训练,得到预训练模型,其中,预设模型包含特征降维投影网络以及语义分割网络,所述语义分割网络为基于u-net的派生网络;通过预训练模型对雾天图像集中的雾天图像进行语义分割,按照可信度从大到小的顺序对语义分割结果进行排序,以排序在前预设比例的语义分割结果为可信伪标签,对所述可信伪标签进行扩充,得到候选标签集;通过候选标签集对扩充后的伪标签进行实时纠正并对预训练模型进行训练,得到语义分割模型;基于所述语义分割模型执行语义分割任务。通过本发明,解决了雾天场景下的语义分割域适应问题,该方案具有简单、有效、精度高、易于实现的特
点。和现有技术相比,本发明具有如下优势:
[0064]
(1)设计的基于候选标签集的雾天语义分割域适应标签纠正框架可以很好地利用雾天图像的特点,解决语义分割域适应问题;
[0065]
(2)针对自训练伪标签生成的问题,提出了候选标签集的概念,更好的利用了网络的预测信息,改善伪标签的质量的同时保留了更多的伪标签的信息;
[0066]
(3)具有很强的实用性和通用性,可以将框架的主干部分替换为任意的基于u-net的语义分割网络,以提高网络的效果。
附图说明
[0067]
图1为本发明基于候选标签集的语义分割域适应标签纠正方法一实施例的流程示意图;
[0068]
图2为本发明基于候选标签集的语义分割域适应标签纠正方法一实施例中预设模型的架构示意图;
[0069]
图3为图2中rnx模块的架构示意图;
[0070]
图4为本发明基于候选标签集的语义分割域适应标签纠正方法一实施例中训练架构示意图;
[0071]
图5为本发明基于候选标签集的语义分割域适应标签纠正装置一实施例的功能模块示意图。
[0072]
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
[0073]
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0074]
本发明针对当前雾天场景语义分割域适应问题,提供了一种基于候选标签集的雾天语义分割域适应标签纠正方法及装置。在对雾天图像数据集进行了详细的实验分析后,发现尽管具有最高预测置信度的单热(one-hot)伪标签并不总是与真正的类别一致,但真正的类别出现在预测可信度排名前几类中的概率很高。基于这一发现,可以认为数据集的差异只会将像素的真正的类别与其他少数几个类混淆,而不是全部混淆。因此,如果能够从几个混淆性较高的类别中消除真实类别的歧义,网络模型就能够更准确地对雾天图像进行语义分割。
[0075]
第一方面,本发明实施例提供了一种基于候选标签集的语义分割域适应标签纠正方法。
[0076]
一实施例中,参照图1,图1为本发明基于候选标签集的语义分割域适应标签纠正方法一实施例的流程示意图。如图1所示,基于候选标签集的语义分割域适应标签纠正方法包括:
[0077]
步骤s10,利用晴天图像集以及晴天图像集中每张晴天图像对应的标签,采用有监督的语义分割训练策略对预设模型进行预训练,得到预训练模型,其中,预设模型包含特征降维投影网络以及语义分割网络,所述语义分割网络为基于u-net的派生网络;
[0078]
本实施例中,采用了cityscapes与foggyzurich数据集,并在训练时对数据集裁剪为786
×
768的大小,每张图像都进行了随机的数据增强操作。前者采集自德国及附近国家
的50个城市,包括了春夏秋三个季节的街区自动驾驶场景,并且带有语义分割所需的标注,分辨率为2048
×
1024。而后者采集自瑞士zurich城市的雾天街区自动驾驶场景,但没有自动驾驶所需的标注,分辨率为1920
×
1080。
[0079]
本实施例中从cityscapes中选取部分图像数据作为晴天图像集,结合其标签作为训练集,采用有监督的语义分割训练策略对预设模型进行预训练,得到预训练模型。例如,采用有监督的语义分割训练策略,对晴天图像集训练100轮,得到预训练模型。
[0080]
其中,将特征降维投影网络添加到语义分割网络中得到预设模型。其中,语义分割网络使用基于u-net的派生网络,如refinenet,deeplab等网络,一实施例中,语义分割网络为基于u-net架构的深度学习refinenet语义分割网络。
[0081]
refinenet分为编码器与解码器两部分,编码器基于u-net框架的下采样模块以及上采样模块组合而成,下采样模块由多个二维的卷积层、bn层以及relu激活层组合而成;上采样模块则由rcu模块、mrf模块以及crp模块组成,本质上都是二维卷积层。解码器,即分类器,由一个简单的3
×
3的二维卷积层构成。
[0082]
特征降维投影网络则由1个1x1的二维卷积层和relu层构成。
[0083]
参照图2,图2为本发明基于候选标签集的语义分割域适应标签纠正方法一实施例中预设模型的架构示意图。如图2所示,编码器与分类器同refinenet完全一致,特征提取网络(即特征降维投影网络)则由编码器末端的1个1x1的二维卷积层与relu层组成。其中conv表示二维卷积层,max pooling表示最大池化层,relu和softmax表示两种不同的激活层。
[0084]
参照图3,图3为图2中rnx模块的架构示意图。如图3所示,rnx模块的构成与refinenet中对应模块一致,其作用是对特征进行上采样,同时尽可能的利用编码器中的输出的特征的信息,使上采样的效果更好。
[0085]
步骤s20,通过预训练模型对雾天图像集中的雾天图像进行语义分割,按照可信度从大到小的顺序对语义分割结果进行排序,以排序在前预设比例的语义分割结果为可信伪标签,对所述可信伪标签进行扩充,得到候选标签集;
[0086]
本实施例中,从foggyzurich中选取部分图像作为雾天图像集。利用预训练模型为雾天图像集产生可信的伪标签,即挑选每个类别可信度最高的前预设比例像素作为可信伪标签。具体来说,将雾天图像集的图片数据输入预训练模型中,然后得到预测的结果,对于每一个类,统计其预测的概率值,按照从大到小进行排序,挑选出前预设比例的像素,此部分像素即为可信的伪标签。
[0087]
然后,利用可信伪标签进行扩充,并得到候选标签集,每个像素的真实类别可以从候选标签集中挑选。真实类别即该像素点对应的真正的类别,即标签的类别,由人工标注完成。
[0088]
具体来说,先使用slic超像素划分方法对雾天图像进行超像素划分,然后将可信伪标签按照相关公式对每个像素进行候选标签集的构造。之后,对于每个像素,将不在候选标签集的类别所在位置置0,并作为软标签保存下来。扩充的方法基于雾对于超像素划分的影响较小,可以使用超像素划分的方式对雾天图像划分出多个语义空间的发现。由于每个语义空间的语义相同,所以可以利用同一个语义空间内的可信标签对伪标签进行一定的扩充,得到可信度稍低的伪标签,这部分标签作为第2类型候选标签区域(c.ii)。剩下的作为第三类型候选标签区域(c.iii)。
[0089]
进一步地,一实施例中,雾天图像集为且其中,表示第i张雾天图像,为雾天图像集,ch表示图像颜色通道数,h和w分别表示雾天图像的长度和宽度大小,n
t
表示雾天图像集的大小,r表示实数集,按照可信度从大到小的顺序对语义分割结果进行排序,以排序在前预设比例的语义分割结果为可信伪标签,对所述可信伪标签进行扩充,得到候选标签集的步骤包括:
[0090]
按照语义分割结果的可信度,将雾天图像的语义分割结果划分为三种区域,三类区域的划分方式如下:
[0091][0092]
其中,1、2、3分别表示第一类型候选标签区域、第二类型候选标签区域、第三类型候选标签区域,m(p)表示像素点p属于哪一类型候选标签区域,c表示像素的语义类别为第c类,φ为模型参数,表示像素p预测为第c类的概率,spi表示第i个超像素块,表示像素点p预测结果中置信度最大的分量,λc为预设比例,表示像素点q预测结果中置信度最大的分量,s.t.p and q∈spi表示像素点p和q都属于spi;
[0093]
以第1类型候选标签区域的每个像素的预测置信度中排名前1个类别对应的标签为其候选标签集、以第2类型候选标签区域的每个像素的预测置信度中排名前3个类别对应的标签为其候选标签集、以第3类型候选标签区域的每个像素的预测置信度中排名前5个类别对应的标签为其候选标签集。
[0094]
例如,像素点p属于第2类型候选标签区域,同时其各个类别的预测置信度排名为3,6,1,7,10,18,0,4
…
则p的候选标签集3,6,1。综上所述,每一个像素点都会有一个候选标签集,这个集合是该像素的真实类别的一个猜测的范围,即真实类别大概率会在候选标签集内。
[0095]
步骤s30,通过候选标签集对扩充后的伪标签进行实时纠正并对预训练模型进行训练,得到语义分割模型;
[0096]
本实施例中,通过候选标签集对扩充后的伪标签进行实时纠正,在此基础上结合晴天图像集以及雾天图像集对预训练模型进行训练,得到语义分割模型。具体的,将晴天图像集与标注以及雾天图像集与软标签依次输入预训练模型中进行训练,并进行原型更新与损失计算,并且反向传播,后使用sgd优化器进行优化。
[0097]
进一步地,一实施例中,步骤s30包括:
[0098]
步骤3.1,将输入预训练模型中,经过编码器,再分别经过特征降维投影网络得到特征以及分类网络得到语义分割结果其中,表示第i张雾天图像经过编码器以及分类网络得到语义分割结果的过程;
[0099]
步骤3.2,依据第一公式计算每个类别的原型,每个类别原型表示为ψ={ψ1,
…
,ψc,
…
,ψc},其中ψc表示第c类别的原型,类别指语义分割对应的预测的类别,原型指类别的
平均特征,第一公式为:
[0100][0101]
其中,表示第i张雾天图像的第p个像素的特征,表示像素p的软标签中第c类的概率,表示指示函数,当括号内结果大于0时为1,否则为0;
[0102]
步骤3.3,根据原型ψ与zi的特征对软标签y
t
进行纠正,如下公式所示:
[0103][0104][0105]
其中,表示像素p的候选标签集,表示类别c对于像素p的权重。
[0106]
||
·
||表示欧式距离;
[0107]
步骤3.4,基于更新后的软标签计算交叉熵损失以及对比学习损失,两种损失分别如下:
[0108][0109][0110]
其中,v表示第i张雾天图像的第p个像素的特征,且p不属于第3类型候选标签区域;v
+
表示特征v的正样本,v-表示v的负样本;表示负样本集合,即所有不属于第3类型候选标签区域的像素q,且像素q的可信度最高的类别不在像素p的候选标签集中的像素的集合;exp(
·
)表示自然对数的底数e的指数运算;
[0111]
步骤3.5,对于晴天图像集,计算对应的标准的交叉熵损失,与步骤5.4的交叉熵损失以及对比学习损失相加后,通过梯度下降的算法进行反向传播,使得预训练模型得到优化;
[0112]
步骤3.6,对于每一张雾天图片都进行上述步骤3.1至3.5的操作,得到语义分割模型。
[0113]
参照图4,图4为本发明基于候选标签集的语义分割域适应标签纠正方法一实施例中训练架构示意图。如图4所示,包括图2的网络结构,即编码器,分类器与特征降维投影网络(即图4中的降维投影网络)。雾天图像通过编码器、分类器后可以根据步骤s20产生可信伪标签同时用于后续步骤s30中的交叉熵损失的计算,以及产生候选标签集。而特征降维投影网络则产生雾天图像数据的特征z,用于步骤s30中的标签纠正算法,同时运用于对比损失的计算。
[0114]
步骤s40,基于所述语义分割模型执行语义分割任务。
[0115]
本实施例中,得到的语义分割模型后用于执行语义分割任务,即对待分割雾天图像进行语义分割,并得到语义分割。
[0116]
对于最终得到的语义分割模型评估采用经典的语义分割领域的miou指标进行评估。具体计算方法如下:假设类别数为n,c是一个n
×
n的混淆矩阵,c
ij
表示矩阵confusin中第i行第j列的元素值,同时也表示真实类别为i的点被分为第j类的点个数,其中i,j∈{1,
…
,c}。那么对于第i类,令:
[0117]
tp=c
ij
[0118]
fp=∑
k≠jckj
[0119]
fn=∑
k≠icik
[0120]
tn=c*c-fn-fp-tp
[0121]
则有:
[0122][0123]
具体实施时,可采用python中的numpy库快速实现以上公式的计算。
[0124]
为便于理解本实施例的有益效果,提供本发明和同领域最先进的方法的对比如下:
[0125][0126]
上述表格记录了本实施例使用的方案和仅使用骨干网络在吉林一号卫星视频测试集上的结果。为了保证公平的对比,除adsegnet外,所有的模型都基于refinenet,采用了相同的训练策略,以及相同的超参数设置,而我们的方法在crst的训练策略上进行修改。可以看到,我们提出的基于候选标签集的雾天语义分割域适应标签方法对于目前最先进的方法有着较大的提升。
[0127]
本实施例中,利用晴天图像集以及晴天图像集中每张晴天图像对应的标签,采用有监督的语义分割训练策略对预设模型进行预训练,得到预训练模型,其中,预设模型包含特征降维投影网络以及语义分割网络,所述语义分割网络为基于u-net的派生网络;通过预训练模型对雾天图像集中的雾天图像进行语义分割,按照可信度从大到小的顺序对语义分割结果进行排序,以排序在前预设比例的语义分割结果为可信伪标签,对所述可信伪标签进行扩充,得到候选标签集;通过候选标签集对扩充后的伪标签进行实时纠正并对预训练模型进行训练,得到语义分割模型;基于所述语义分割模型执行语义分割任务。通过本实施例,解决了雾天场景下的语义分割域适应问题,该方案具有简单、有效、精度高、易于实现的特点。和现有技术相比,本实施例具有如下优势:
[0128]
(1)设计的基于候选标签集的雾天语义分割域适应标签纠正框架可以很好地利用雾天图像的特点,解决语义分割域适应问题;
[0129]
(2)针对自训练伪标签生成的问题,提出了候选标签集的概念,更好的利用了网络的预测信息,改善伪标签的质量的同时保留了更多的伪标签的信息;
[0130]
(3)具有很强的实用性和通用性,可以将框架的主干部分替换为任意的基于u-net的语义分割网络,以提高网络的效果。
[0131]
第二方面,本发明实施例还提供一种基于候选标签集的语义分割域适应标签纠正装置。
[0132]
一实施例中,参照图5,图5为本发明基于候选标签集的语义分割域适应标签纠正装置一实施例的功能模块示意图。如图5所示,基于候选标签集的语义分割域适应标签纠正装置包括:
[0133]
预训练模块10,用于利用晴天图像集以及晴天图像集中每张晴天图像对应的标签,采用有监督的语义分割训练策略对预设模型进行预训练,得到预训练模型,其中,预设模型包含特征降维投影网络以及语义分割网络,所述语义分割网络为基于u-net的派生网络;
[0134]
扩充模块20,用于通过预训练模型对雾天图像集中的雾天图像进行语义分割,按照可信度从大到小的顺序对语义分割结果进行排序,以排序在前预设比例的语义分割结果为可信伪标签,对所述可信伪标签进行扩充,得到候选标签集;
[0135]
训练模块30,用于通过候选标签集对扩充后的伪标签进行实时纠正并对预训练模型进行训练,得到语义分割模型;
[0136]
执行模块40,用于基于所述语义分割模型执行语义分割任务。
[0137]
进一步地,一实施例中,雾天图像集为且其中,表示第i张雾天图像,为雾天图像集,ch表示图像颜色通道数,h和w分别表示雾天图像的长度和宽度大小,n
t
表示雾天图像集的大小,r表示实数集,扩充模块20,用于:
[0138]
按照语义分割结果的可信度,将雾天图像的语义分割结果划分为三种区域,三类区域的划分方式如下:
[0139][0140]
其中,1、2、3分别表示第一类型候选标签区域、第二类型候选标签区域、第三类型候选标签区域,m(p)表示像素点p属于哪一类型候选标签区域,c表示像素的语义类别为第c类,φ为模型参数,表示像素p预测为第c类的概率,spi表示第i个超像素块,表示像素点p预测结果中置信度最大的分量,λc为预设比例,表示像素点q预测结果中置信度最大的分量,s.t.pandq∈spi表示像素点p和q都属于spi;
[0141]
以第1类型候选标签区域的每个像素的预测置信度中排名前1个类别对应的标签为其候选标签集、以第2类型候选标签区域的每个像素的预测置信度中排名前3个类别对应的标签为其候选标签集、以第3类型候选标签区域的每个像素的预测置信度中排名前5个类别对应的标签为其候选标签集。
[0142]
进一步地,一实施例中,训练模块30,用于:
[0143]
步骤3.1,将输入预训练模型中,经过编码器,再分别经过特征降维投影网络得到特征以及分类网络得到语义分割结果其中,表示第i张雾天图像经过编码器以及分类网络得到语义分割结果的过程;
[0144]
步骤3.2,依据第一公式计算每个类别的原型,每个类别原型表示为ψ={ψ1,
…
,ψc,
…
,ψc},其中ψc表示第c类别的原型,类别指语义分割对应的预测的类别,原型指类别的平均特征,第一公式为:
[0145][0146]
其中,表示第i张雾天图像的第p个像素的特征,表示像素p的软标签中第c类的概率,表示指示函数,当括号内结果大于0时为1,否则为0;
[0147]
步骤3.3,根据原型ψ与zi的特征对软标签y
t
进行纠正,如下公式所示:
[0148][0149][0150]
其中,表示像素p的候选标签集,表示类别c对于像素p的权重。
[0151]
||
·
||表示欧式距离;
[0152]
步骤3.4,基于更新后的软标签计算交叉熵损失以及对比学习损失,两种损失分别如下:
[0153][0154][0155]
其中,v表示第i张雾天图像的第p个像素的特征,且p不属于第3类型候选标签区域;v
+
表示特征v的正样本,v-表示v的负样本;表示负样本集合,即所有不属于第3类型候选标签区域的像素q,且像素q的可信度最高的类别不在像素p的候选标签集中的像素的集合;exp(
·
)表示自然对数的底数e的指数运算;
[0156]
步骤3.5,对于晴天图像集,计算对应的标准的交叉熵损失,与步骤5.4的交叉熵损失以及对比学习损失相加后,通过梯度下降的算法进行反向传播,使得预训练模型得到优化;
[0157]
步骤3.6,对于每一张雾天图片都进行上述步骤3.1至3.5的操作,得到语义分割模
型。
[0158]
进一步地,一实施例中,所述语义分割网络为基于u-net架构的深度学习refinenet语义分割网络。
[0159]
进一步地,一实施例中,所述特征降维投影网络包含1个1x1的二维卷积层和relu层。
[0160]
其中,上述基于候选标签集的语义分割域适应标签纠正装置中各个模块的功能实现与上述基于候选标签集的语义分割域适应标签纠正方法实施例中各步骤相对应,其功能和实现过程在此处不再一一赘述。
[0161]
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
[0162]
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
[0163]
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在如上所述的一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备执行本发明各个实施例所述的方法。
[0164]
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1