一种笔记生成方法及其相关设备与流程
本技术涉及图像处理,尤其涉及一种笔记生成方法及其相关设备。
背景技术:
1、光学字符识别(optical character recognition,ocr)技术是图像处理领域的一种重要技术,可以对图像中的文本区域进行识别,从而提取出文字信息。
2、ocr技术不仅可用来对单个图像的文本区域进行识别,也可对视频流中出现的文本区域进行识别。例如,设用户在阅读某个书本,且用户对书本中的某部分内容产生了兴趣,需要在终端设备处记录相应的笔记,则可通过终端设备对该书本进行拍摄,得到视频流。然后,终端设备可对视频流中的某个图像帧进行识别,得到用户笔记。
3、为了准确采集用户所需记录的内容,用户需要手动调整终端设备的摄像头,使得摄像头的视野刚好呈现出这部分内容。那么,采集到的图像帧中文本区域所呈现的内容即为用户所需记录的内容,终端设备对其进行识别后,可提取出这部分内容,作为用户笔记。然而,这种笔记生成的方式,需要用户付出大量的人工操作,导致用户体验较差。
技术实现思路
1、本技术实施例提供了一种笔记生成方法及其相关设备,提供了一种新的笔记生成的方式,用户仅需完成划线操作即可,所付出的操作量极少,不会花费用户太多的时间,有利于提高用户体验。
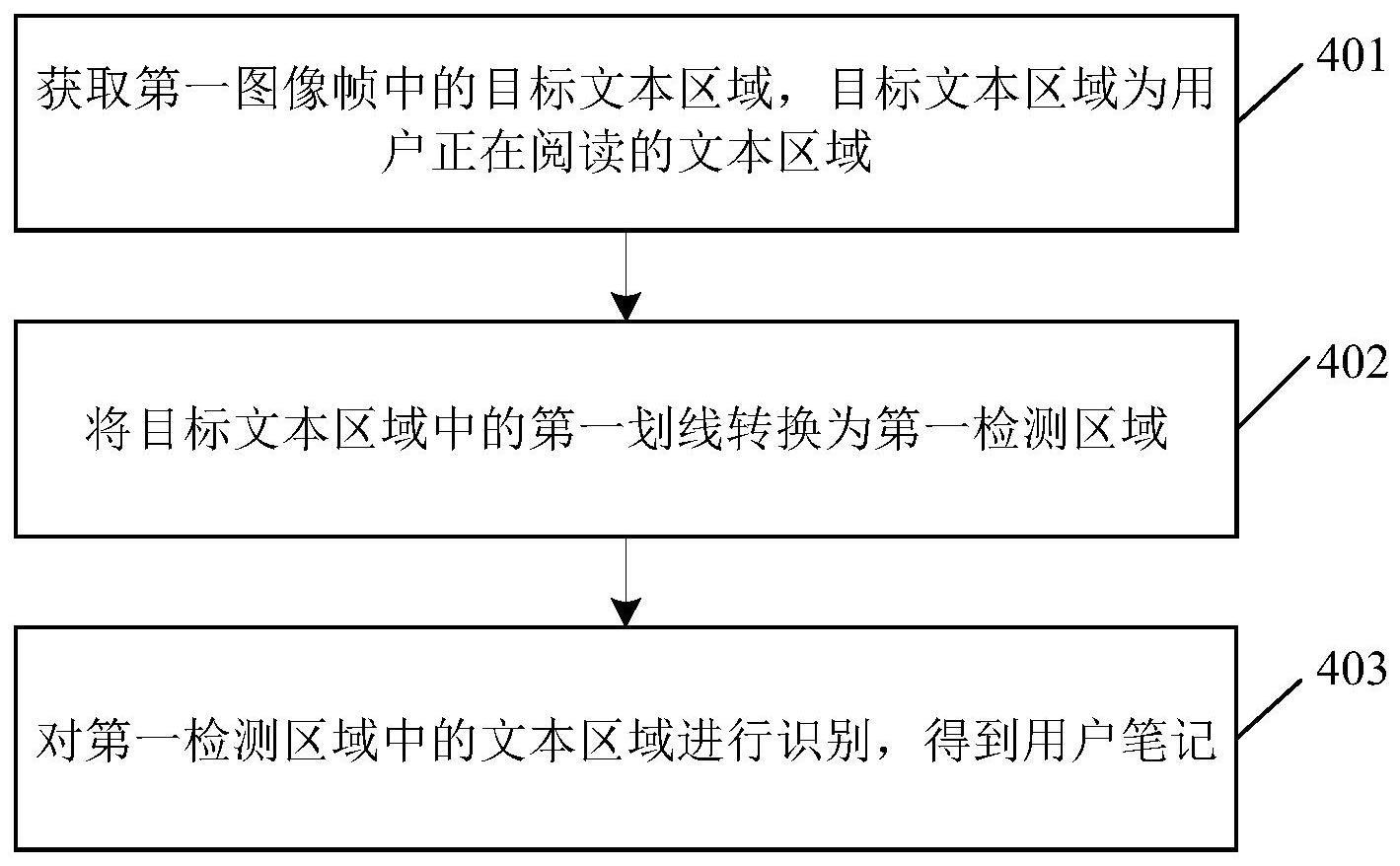
2、本技术实施例的第一方面提供了一种笔记生成方法,该方法包括:
3、终端设备在视频流中所获取的第一图像帧,可能包含多个文本区域。那么,在第一图像帧的多个文本区域中,终端设备可获取目标文本区域,目标文本区域为用户正在阅读的文本区域。需要说明的是,由于目标文本区域为用户正在阅读的文本区域,终端设备可对目标文本区域进行识别操作,以生成用户笔记,故目标文本区域也可以理解为终端设备待识别(待进行识别操作)的文本区域。
4、在确定目标文本区域后,终端设备可识别出目标文本区域中的第一划线(也可以称为用户划线),识别出第一划线后,终端设备可将第一划线转换为第一检测区域,第一检测区域通常为一个矩形区域,且标识了被第一划线所标记的文本区域。
5、在得到第一检测区域后,终端设备可对第一检测区域中的文本区域进行ocr,即将第一检测区域所围住的文本区域所呈现的文字提取出来,作为用户笔记。
6、从上述方法可以看出:在获取第一图像帧中用户正在阅读的文本区域后,即获取第一图像帧中的目标文本区域后,终端设备可识别出目标文本区域中用户输入的第一划线,并将目标文本区域中的第一划线转换为第一检测区域。然后,终端设备可对第一检测区域中的文本区域进行ocr,从而得到用户笔记。前述过程中,终端设备可智能地将用户输入的第一划线,转换为标识第一划线所标记的文本区域的第一检测区域,从而有针对性地对这部分文本区域进行ocr,生成用户所需的笔记。由此可见,这种笔记生成的方式,用户仅需完成划线操作即可,所付出的操作量极少,不会花费用户太多的时间,有利于提高用户体验。
7、在一种可能的实现方式中,将目标文本区域中的第一划线转换为第一检测区域包括:创建与目标文本区域中的第一划线重叠的多个第一矩形,多个第一矩形依次层叠;在重叠程度最大的第一矩形中创建第二划线,第二划线与重叠程度最大的第一矩形的长边平行;基于第二划线创建第二矩形,第二矩形作为第一检测区域,第二划线位于第二矩形中,第二划线与第二矩形的长边平行,第二矩形的短边的长度大于目标文本区域的行高。前述实现方式中,终端设备先创建与目标文本区域中的第一划线重叠的多个第一矩形,这多个第一矩形依次层叠,且对于任意一个第一矩形而言,该第一矩形与第一划线之间具有一个重叠程度,用于指示第一划线位于该第一矩形中的部分有多大。然后,终端设备在多个第一矩形中,挑选出重叠程度最大的第一矩形,并在重叠程度最大的第一矩形中创建第二划线,需要说明的是,第二划线通常为直线,第二划线可位于重叠程度最大的第一矩形的中心点处(或中心点周围),且第二划线与重叠程度最大的第一矩形的长边平行。最后,终端设备基于第二划线创建第二矩形,第二矩形可作为用于实现ocr的第一检测区域,需要说明的是,整个第二划线位于第二矩形中,第二划线位于第二矩形的中心点偏下方处,第二划线与第二矩形的长边平行,且第二矩形的短边的长度大于目标文本区域的行高。可见,基于此种方式可有效确定丢一检测区域的尺寸,以使得创建的第一检测区域可围住第一划线标记的文本区域。
8、在一种可能的实现方式中,基于第二划线创建第二矩形之后,该方法还包括:将第二矩形划分为多个子矩形;在多个子矩形中,将像素占比率小于预置第一阈值的子矩形剔除,剩余的子矩形所构成的第三矩形作为第一检测区域。前述实现方式中,终端设备将第二矩形划分为多个子矩形,每一个子矩形所围住的区域可视为第二矩形所围住的文本区域中的一行像素点,那么,在这多个子矩形中,有一部分子矩形所围住的区域为空白行,有一部分子矩形所围住的区域为有效行。得到多个子矩形后,对于任意一个子矩形,终端设备可基于该子矩形中的所有像素点进行计算,得到该子矩形的像素占比率。如此一来,可得到所有子矩形的像素占比率,终端设备通过预置第一阈值将所有子矩形分为两部分,第一部分子矩形的像素占比率小于预置第一阈值,第二部分子矩形的像素占比率大于或等于预置第一阈值,那么,终端设备可将第一部分子矩形剔除,并将第二部分子矩形组成第三矩形,作为用于最终实现ocr的第一检测区域。可见,终端设备对第二矩形进行优化后,可得到第三矩形,第三矩形相较于第二矩形而言,去除了非必要的部分,精简了尺寸,可有效减少后续ocr所需的计算量。
9、在一种可能的实现方式中,获取第一图像帧中的目标文本区域包括:若第一图像帧中文本区域的状态信息与第二图像帧中文本区域的状态信息存在差异,则基于第一图像帧中文本区域的状态信息,在第一图像帧中确定目标文本区域,第二图像帧为第一图像帧的前一图像帧。前述实现方式中,若第一图像帧中文本区域的状态信息与第二图像帧中文本区域的状态信息之间存在差异,说明相较于第二图像帧而言,第一图像帧的多个文本区域中,至少有一个文本区域发生了变动,故终端设备可基于第一图像帧中文本区域的状态信息做进一步的分析,从而在第一图像帧的多个文本区域中确定目标文本区域。
10、在一种可能的实现方式中,第一图像帧中文本区域的状态信息包括第一图像帧的文本区域的数量、第一图像帧的文本区域的面积、第一图像帧的文本区域的角度以及第一图像帧的文本区域的位置等信息中的至少一项,第二图像帧中文本区域的状态信息包括第二图像帧的文本区域的数量、第二图像帧的文本区域的面积、第二图像帧的文本区域的角度以及第二图像帧的文本区域的位置等信息中的至少一项。
11、在一种可能的实现方式中,基于第一图像帧中文本区域的状态信息,在第一图像帧中确定目标文本区域包括:若第一图像帧中存在用户的人体区域,说明用户的人体部位在书桌上,那么,可进一步分析用户的人体部位在当前时刻和之前时刻之间,是否打开了一本新的书本,故终端设备可比较第一图像帧中文本区域的数量与第二图像帧中文本区域的数量是否相同,以检测第一图像帧中是否存在新的文本区域;若第一图像帧中文本区域的数量与第二图像帧中文本区域的数量不同,即相较于第二图像帧而言,第一图像帧中存在新的文本区域,说明书桌上有新的书本被用户打开了,用户极有可能在阅读该新的书本,该新的书本的页面在第一图像帧中所占据的区域即为新的文本区域,故终端设备可直接将新的文本区域确定为目标文本区域;若第一图像帧中文本区域的数量与第二图像帧中文本区域的数量相同,即相较于第二图像帧而言,第一图像帧中不存在新的文本区域,说明书桌上并没有新的书本被用户打开了,则可在书桌上的多个书本中,将与用户的人体部位相关联的书本作为用户正在阅读的书本,故终端设备将与人体区域关联的文本区域确定为目标文本区域;若第一图像帧中不存在用户的人体区域,说明用户的人体部位未在书桌上,故可对书桌上的多个书本直接进行静态分析,从而确定哪一个书本时用户正在阅读的书本,即终端设备可在第一图像帧的多个文本区域中,将语义面积最大的文本区域确定为目标文本区域。对于任意一个文本区域,该文本区域的语义面积为该文本区域的面积与该文本区域的语义距离之间的比值,该文本区域的语义距离为该文本区域与第一图像帧的中心点之间的距离。前述实现方式中,终端设备可实时判断用户意图,即在第一图像帧中实时追踪哪一文本区域为用户正在区域的文本区域,如此一来,终端设备不需要处理第一图像帧中所有的文本区域,从而提升信息提取的精度和速度。
12、在一种可能的实现方式中,目标文本区域中还存在第二检测区域,第二检测区域基于第三图像帧中的第三划线转换得到,第三图像帧位于第一图像帧之前,第三图像帧与第一图像帧之间相隔多个图像帧,对第一检测区域中的文本区域进行识别,得到用户笔记包括:若第一检测区域中的文本区域和第二检测区域中的文本区域之间的距离大于或等于预置第二阈值,对第一检测区域中的文本区域和第二检测区域中的文本区域分别进行识别,得到两个用户笔记;若第一检测区域中的文本区域和第二检测区域中的文本区域之间的距离小于预置第二阈值,将第一检测区域和第二检测区域合并为第三检测区域,并对第三检测区域中的文本区域进行识别,得到用户笔记。前述方式中,终端设备可对多个划线标记的文本区域进行意图识别,根据这多个文本区域之间的空间信息(距离)来判断,这多个文本区域中的文字是否为同一个笔记。若多个文本区域中的文字为同一个笔记,则生成一个用户笔记即可,若多个文本区域中的文字不为同一个笔记,则生成多个不同的用户笔记,有利于整合笔记信息,方便用户阅读,进一步提高用户体验。
13、在一种可能的实现方式中,对两个第一检测区域中的文本区域分别进行识别,得到两个用户笔记之后,该方法还包括:对两个用户笔记进行合并,得到新的用户笔记,两个用户笔记位于同一段落中,新的用户笔记包含段落中除两个用户笔记之外的其余文字以及高亮显示的两个用户笔记。前述实现方式中,在确定这多个文本区域中的文字为不同的多个笔记后,可对生成的多个笔记进行合并,如此一来,可支持用户实现多种划线方式,例如,支持连续划线、同段落分散划线的方式等等,使得方案的功能更加全面,进一步地提高用户体验。
14、在一种可能的实现方式中,对第一检测区域中的文本区域进行识别,得到用户笔记之前,该方法还包括:对第一检测区域中的文本区域进行校正,得到校正后的文本区域;对第一检测区域中的文本区域进行识别,得到用户笔记包括:对校正后的文本区域进行识别,得到用户笔记。前述实现方式中,若第一检测区域中的文本区域的角度为非零度,说明第一检测区域中的文本区域是歪的,而非正对着相机,那么,终端设备可对第一检测区域中的文本区域的角度进行调整,直至角度为零度,得到校正后的文本区域。然后,终端设备再对校正后的文本区域进行ocr,可提高ocr的速度。
15、在一种可能的实现方式中,目标文本区域中存在目标符号,对第一检测区域中的文本区域进行识别,得到用户笔记之后,该方法还包括:若目标符号位于预置的符号集合中,将用户笔记添加至目标符号对应的用户笔记集合中;若目标符号未位于符号集合中,将目标符号添加至符号集合中,并创建与目标符号对应的用户笔记集合,再将用户笔记添加至目标符号对应的用户笔记集合中。前述实现方式中,若在第一图像帧中,目标文本区域中不仅存在用户输入的第一划线,还存在用户输入的目标符号,目标符号通常位于第一划线所标记的文本区域附近,且目标符号对应于某一类用户笔记,即某一个用户笔记集合。那么,在对第一检测区域中的文本区域进行识别,得到用户笔记后,终端设备可先在检测目标符号是否位于预置的符号集合中,若目标符号位于该符号集合中,说明目标符号是已定义的符号,终端设备则将用户笔记添加至目标符号对应的用户笔记集合中,若目标符号未位于该符号集合中,说明目标符号是未定义的符号,终端设备则将目标符号添加至该符号集合中,并创建与目标符号对应的用户笔记集合,再将用户笔记添加至目标符号对应的用户笔记集合中,如此一来,相当于完成用户笔记的分类,后续用户在统筹和使用笔记时,可通过寻找符号,来调出同一类的用户笔记,有利于进一步提高用户体验。
16、在一种可能的实现方式中,第一检测区域可以呈现为第一色块,第一色块覆盖了第一划线标记的文本区域。当然,第一检测区域还可以为其它呈现方式,例如,第一检测区域还可以呈现为第一检测框,第一检测框包围了第一划线标记的文本区域,又如,第一检测区域还可以呈现为第一括号,第一括号中的文本区域即为第一划线标记的文本区域等等。相应的,第二检测区域也可以呈现为第二色块、第二检测框或第二括号等等。
17、在一种可能的实现方式中,若终端设备未接收到任何用户输入的指定用户笔记的格式的指令,终端设备可在生成用户笔记的时候,默认令用户笔记的格式与检测区域中的文本区域的文字的格式相同。例如,文字的大小、颜色以及锁紧信息等,二者均是保持一致的,从而满足用户的不同需求。
18、在一种可能的实现方式中,若终端设备接收到用户输入的指定用户笔记的格式的指令,终端设备可在生成用户笔记的时候,令用户笔记的格式与该指令所指示的格式相同。用户笔记的格式包括以下至少一项:用户笔记的字体、用户笔记的颜色、用户笔记的粗细、用户笔记的位置和用户笔记的段落标识。例如,设终端设备显示的用户交互界面所呈现的内容中的文字字体为楷体,文本颜色为黑色,但是用户想将用户笔记的字体设置为宋体,用户笔记的颜色设置为蓝色,用户可在对用户交互界面上进行划线之前,向用户交互界面上输入指令,那么终端设备获取该指令后,在将用户划线的文字生成用户笔记的时候,可将最终生成的用户笔记的字体设置为宋体,并把用户笔记的颜色设置为蓝色等等。
19、进一步地,指定用户笔记的格式的指令的输入方式可以为:用户在用户交互界面上绘制某种自定义图案,该图案可以被终端设备所识别,从而使得终端设备确定用户指定了用户笔记的格式。
20、在一种可能的实现方式中,第一图像帧来源于媒体信息,例如,该媒体信息可以是用户录制的视频流,第一图像帧可以为视频流里面的某一个图像帧。又如,该媒体信息还可以是用户录制的音频流,那么,对音频流进行文本识别后,可得到相应的文本并呈现在用户交互界面上,呈现在用户交互界面上的文本可作为第一图像帧。再如,该媒体信息还可以是用户对某个网页上(或者文档、用户手绘的文本等等)进行截取的图片,终端设备获取到该图片后,可将该图片作为第一图像帧等等。
21、本技术实施例的第二方面提供了一种笔记生成装置,该装置包括:获取模块,用于获取第一图像帧中的目标文本区域,目标文本区域为用户正在阅读的文本区域(待识别的文本区域);转换模块,用于将目标文本区域中的第一划线转换为第一检测区域,第一检测区域用于标识第一划线标记的文本区域;识别模块,用于对第一检测区域中的文本区域进行识别,得到用户笔记。
22、从上述装置可以看出:在获取第一图像帧中用户正在阅读的文本区域后,即获取第一图像帧中的目标文本区域后,终端设备可识别出目标文本区域中用户输入的第一划线,并将目标文本区域中的第一划线转换为第一检测区域。然后,终端设备可对第一检测区域中的文本区域进行ocr,从而得到用户笔记。前述过程中,终端设备可智能地将用户输入的第一划线,转换为标识第一划线所标记的文本区域的第一检测区域,从而有针对性地对这部分文本区域进行ocr,生成用户所需的笔记。由此可见,这种笔记生成的方式,用户仅需完成划线操作即可,所付出的操作量极少,不会花费用户太多的时间,有利于提高用户体验。
23、在一种可能的实现方式中,转换模块,用于:创建与目标文本区域中的第一划线重叠的多个第一矩形,多个第一矩形依次层叠;在重叠程度最大的第一矩形中创建第二划线,第二划线与重叠程度最大的第一矩形的长边平行;基于第二划线创建第二矩形,第二矩形作为第一检测区域,第二划线位于第二矩形中,第二划线与第二矩形的长边平行,第二矩形的短边的长度大于目标文本区域的行高。
24、在一种可能的实现方式中,该装置还包括:优化模块,用于:将第二矩形划分为多个子矩形;在多个子矩形中,将像素占比率小于预置第一阈值的子矩形剔除,剩余的子矩形所构成的第三矩形作为第一检测区域。
25、在一种可能的实现方式中,获取模块,用于若第一图像帧中文本区域的状态信息与第二图像帧中文本区域的状态信息存在差异,则基于第一图像帧中文本区域的状态信息,在第一图像帧中确定目标文本区域,第二图像帧为第一图像帧的前一图像帧。
26、在一种可能的实现方式中,文本区域的状态信息包含以下至少一项:文本区域的数量、文本区域的面积、文本区域的角度以及文本区域的位置。
27、在一种可能的实现方式中,获取模块,用于:若第一图像帧中存在用户的人体区域,将第一图像帧中文本区域的数量与第二图像帧中文本区域的数量进行比较,以检测第一图像帧中是否存在新的文本区域;若第一图像帧中存在新的文本区域,将新的文本区域确定为目标文本区域;若第一图像帧中不存在新的文本区域,将与人体区域关联的文本区域确定为目标文本区域;若第一图像帧中不存在用户的人体区域,将语义面积最大的文本区域确定为目标文本区域,文本区域的语义面积为文本区域的面积与文本区域的语义距离之间的比值,文本区域的语义距离为文本区域与第一图像帧的中心点之间的距离。
28、在一种可能的实现方式中,目标文本区域中还存在第二检测区域,第二检测区域基于第三图像帧中的第三划线转换得到,第三图像帧位于第一图像帧之前,第三图像帧与第一图像帧之间相隔多个图像帧,识别模块,用于:若第一检测区域中的文本区域和第二检测区域中的文本区域之间的距离大于或等于预置第二阈值,对第一检测区域中的文本区域和第二检测区域中的文本区域分别进行识别,得到两个用户笔记;若第一检测区域中的文本区域和第二检测区域中的文本区域之间的距离小于预置第二阈值,将第一检测区域和第二检测区域合并为第三检测区域,并对第三检测区域中的文本区域进行识别,得到用户笔记。
29、在一种可能的实现方式中,该装置还包括:合并模块,用于对两个用户笔记进行合并,得到新的用户笔记,两个用户笔记位于同一段落中,新的用户笔记包含段落中除两个用户笔记之外的其余文字以及高亮显示的两个用户笔记。
30、在一种可能的实现方式中,该装置还包括:校正模块,用于对第一检测区域中的文本区域进行校正,得到校正后的文本区域;识别模块,用于对校正后的文本区域进行识别,得到用户笔记。
31、在一种可能的实现方式中,目标文本区域中存在目标符号,该装置还包括:分类模块,用于:若目标符号位于预置的符号集合中,将用户笔记添加至目标符号对应的用户笔记集合中;若目标符号未位于符号集合中,将目标符号添加至符号集合中,并创建与目标符号对应的用户笔记集合,再将用户笔记添加至目标符号对应的用户笔记集合中。
32、在一种可能的实现方式中,第一检测区域可以呈现为第一色块,第一色块覆盖了第一划线标记的文本区域。当然,第一检测区域还可以为其它呈现方式,例如,第一检测区域还可以呈现为第一检测框,第一检测框包围了第一划线标记的文本区域,又如,第一检测区域还可以呈现为第一括号,第一括号中的文本区域即为第一划线标记的文本区域等等。相应的,第二检测区域也可以呈现为第二色块、第二检测框或第二括号等等。
33、在一种可能的实现方式中,用户笔记的格式与检测区域中的文本区域的文字的格式相同。
34、在一种可能的实现方式中,用户笔记的格式基于用户输入的指令确定,用户笔记的格式包括以下至少一项:用户笔记的字体、用户笔记的颜色、用户笔记的粗细、用户笔记的位置和用户笔记的段落标识。
35、在一种可能的实现方式中,第一图像帧来源于媒体信息。
36、本技术实施例的第三方面提供了一种笔记生成装置,该装置包括存储器和处理器;存储器存储有代码,处理器被配置为执行所述代码,当代码被执行时,笔记生成装置执行如第一方面或第一方面中任意一种可能的实现方式所述的方法。
37、本技术实施例的第四方面提供了一种计算机存储介质,该计算机存储介质存储有一个或多个指令,指令在由一个或多个计算机执行时使得一个或多个计算机实施如第一方面或第一方面中任意一种可能的实现方式所述的方法。
38、本技术实施例的第五方面提供了一种计算机程序产品,计算机程序产品存储有指令,指令在由计算机执行时,使得计算机实施如第一方面或第一方面中任意一种可能的实现方式所述的方法。
39、本技术实施例中,在获取第一图像帧中用户正在阅读的文本区域后,即获取第一图像帧中的目标文本区域后,终端设备可识别出目标文本区域中用户输入的第一划线,并将目标文本区域中的第一划线转换为第一检测区域。然后,终端设备可对第一检测区域中的文本区域进行ocr,从而得到用户笔记。前述过程中,终端设备可智能地将用户输入的第一划线,转换为标识第一划线所标记的文本区域的第一检测区域,从而有针对性地对这部分文本区域进行ocr,生成用户所需的笔记。由此可见,这种笔记生成的方式,用户仅需完成划线操作即可,所付出的操作量极少,不会花费用户太多的时间,有利于提高用户体验。
- 还没有人留言评论。精彩留言会获得点赞!