一种自监督伪标签优化的跨语言命名实体识别方法及系统
本发明涉及自然语言处理,特别涉及一种自监督伪标签优化的跨语言命名实体识别方法与系统。
背景技术:
1、命名实体识别(ner)是网络环境中的一项基本任务大多数自然语言处理(nlp)。用户使用ner技术检测命名实体,并将它们分类为预定义的实体类型(如作为人,组织,地点等),这已经广泛包含在各种下游任务中,如提问回答,信息提取。深度神经网络方法以为用户提供了一定的方法,且此方法需要大量的标记数据来训练神经模型。然而,大多数语言几乎只有很少已标注的标签甚至没有标记数据来提供给用户,进行训练完全监督模型。而无标签的目标语言数据的获得是很廉价的,但并非所有的无标签样本都适用于目标语言模型的训练。因此,用户需求可以通过选择可迁移的目标语言伪标签数据训练目标语言模型满足。
2、目前已有的基于跨语言命名实体识别的数据选择技术有3种方法:第一种假设全部伪标签目标语言数据都可用。但已有的技术工作表明并不是所有的伪标签数据都可用于目标语言的模型训练,有的样本不适合跨语言迁移的即低质量的,如果强行加入训练会损坏模型性能。第二种选择语言无关性强的伪标签样本。而语言无关性强的的伪标签样本是存在一部分噪声的,这部分噪声仍然会对模型造成一定损坏,且选择语言独立性强的样本是基于样本级别的,是一种粗粒度的方法并没有考虑到词粒度,而命名实体识别这项任务是一项基于词级别的技术,选择伪标注样本应该从句子和词级别应该两个级别都要考虑。第三种用迭代蒸馏动态选择伪标签数据。迭代蒸馏选择伪标签数据会造成错误标签的传播,如果一个错的标签经过很多次的迭代训练,那么新获得的伪标签错误的概率是很大的,而这些错误的伪标签加入到目标语言的模型训练中会严重损害模型的性能。在实际应用场景中,用户拥有大量的源语言的标记数据,且往往都能获得廉价的无标注的目标语言数据而这部分数据的利用价值有待开发。现存的跨语言命名实体识别的数据选择方法仍然存在各自的不足,仍然不能满足用户的需求。
技术实现思路
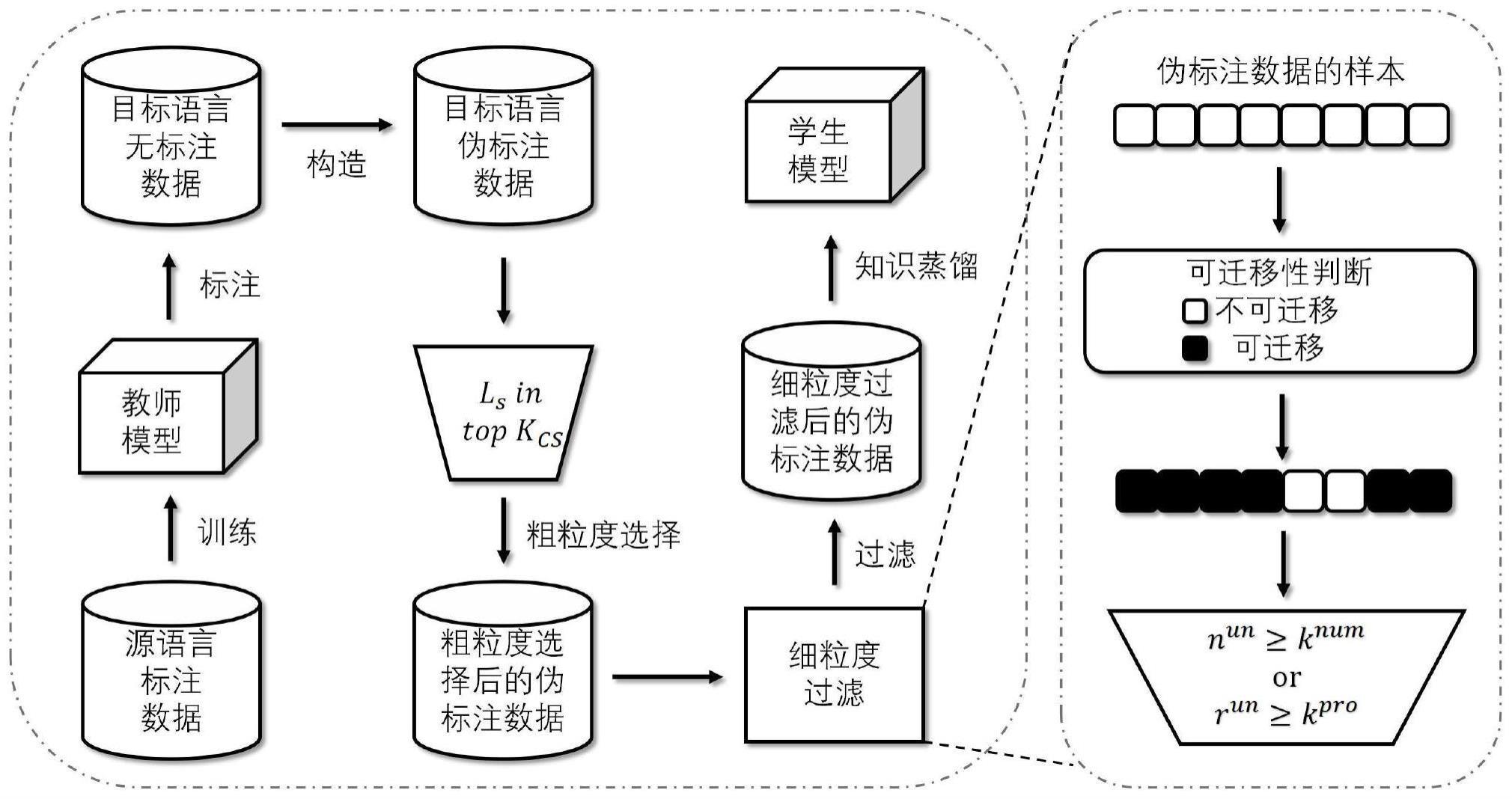
1、本发明的目的在于克服现有技术的缺点和不足,提出一种自监督伪标签优化的跨语言命名实体识别方法及系统,基于粗粒度选择与细粒度过滤选择了有效的伪标记数据样本且改善了跨语言命名实体的效果。
2、为此,本发明的公开了一种自监督伪标签优化的跨语言命名实体识别方法,所述方法包括:根据用户获得目标语言伪标签数据集的功能需求,利用源语言数据集训练源语言模型来并利用源语言模型为用户进行目标语言的标注工作,提供给用户目标语言的伪标签数据集;
3、将目标语言的伪标签数据集进行粗粒度选择;
4、将粗粒度选择后的伪标签数据集进行细粒度过滤;
5、将细粒度过滤后的伪标签数据集进行知识蒸馏训练用于目标语言的命名实体识别模型。
6、优选地,所述根据用户获得目标语言伪标签数据集的功能需求,利用源语言数据集训练源语言模型来并利用源语言模型为用户进行目标语言的标注工作,提供给用户目标语言的伪标签数据集;包括:
7、利用源语言标注数据训练源语言模型,而源语言模型使用多语言训练模型multilingualbert作为源语言模型的特征编码器e,把要输入的源语言句子和目标语言句子编码成特征向量;给定一个句子x,有n个词,x={t1,t2,....,tn},句子被特征编码器编码:
8、h=e(x)
9、其中ti(i∈n)表示句子x中第i个词,句子x经特征编码器e编码后,得到句子x的隐层特征向量h,h={h1,h2,....,hn}其中hi(i∈n)是第i个词的隐层特征向量;
10、使用线性层作为源语言模型的分类器,把句子x经过编码后的隐藏特征向量输入到分类器,获得句子
11、利用源语言模型对目标语言的无标注样本进行预测获得所有样本的伪标注后,就能为用户构造出目标语言的伪标签数据集。
12、优选地,x每个词的实体分布概率,计算方式如下:
13、pθ(yner)=softmax(wnerh+bner)
14、其中,pθ(yner)是x中每个词的实体标签分布概率也作为x的伪标签,而目标语言在训练完成后被源语言模型预测时,pθ(yner)是作为目标语言句子x的伪标签;wner和bner是分类器的待学习参数;
15、优选地,使用交叉熵损失函数进行计算损失并更新编码器和分类器的参数,损失lner计算如下:
16、
17、其中是第i条样本的真实标签,yiner是第i条样本的预测标签,是第i条样本预测正确的概率。
18、优选地,所述将目标语言的伪标签数据集进行粗粒度选择;包括:
19、用源语言模型对目标语言句子计算目标语言的句子logit,句子logit由词logit计算得出,词logit计算方法如下:
20、lt=max(wnere(x)+bner)
21、其中,lt为句子中每个词的词logit,句子x中每个词的词logit也可以表示为如下:
22、lt={l1,l2,...,ln}
23、句子logit的计算方法如下:
24、
25、对整个目标语言伪标注样本按句logit进行降序排序,使用句logit排前kcs%的样本和他们的伪标签通过知识蒸馏训练ner模型,通过不断调整超参数kcs%,以确保模型在验证集中具有最好的性能;当kcs%被用户确定下来后,句子logit排前kcs%的样本被划分为可迁移样本,用户便可获得粗粒度选择后的伪标记数据。
26、优选地,所述将粗粒度选择后的伪标签数据集进行细粒度过滤;包括:
27、找出每个类的词logit的临界点,在每个类下只要词logit大于该类的词logit的临界点,该词便被判定为可迁移的词;计算词logit的临界点首先需要计算每个类下的准确率;而每个类的准确率可以通过目标语言的验证集计算,用于计算源语言模型预测每个实体标签类的准确率;用源语言模型对目标语言验证集进行标注获得伪标签;对于目标语言验证集中第i个类,统计该类中所有词的伪标签与真实标签相同的个数,记作并统计该类的词的个数则第i个类的准确率ai计算方法如下:
28、
29、对目标语言伪标记数据中第i个类的词按词logit进行降序排序,得到词集合其中代表该类下的全部的词,词loigt沿下标增大而变小。则判断第i个类中词qj的可迁移性只需满足以下条件:
30、
31、即判断为可迁移的词,如果不满足,则判断为不可迁移的词;在细粒度过滤中,目标语言伪标注数据中每条句子的词都被划分为可迁移词和不可迁移的词,统计对于每一条句子来说,统计不可迁移的词和可迁移的词的数量,分别记作nun,ntran。用于控制句子是否被过滤掉,当过滤下列两个条件:
32、nun≥knum
33、rtran≤kpro
34、其中,一个目标语言伪标签数据集的全部句子满足其中一个条件之一即可,用户可根据目标语言的不同进行调试,选择确定一个过滤条件即可。
35、优选地,所述将粗粒度选择后的伪标签数据集进行细粒度过滤;包括:
36、利用词距离判断词的可迁移性;词的距离是指第i个类下的词与类中心的距离;词中心由用户给出超参数c∈[0,1],用于决定选取第i个类的按词logit最大的前c的那部分词的词隐层向量的均值,得出第i个类的类中心向量;取词在编码器mbert的最后一层的隐层向量作为该词的隐层向量;词的距离通过对该词的隐层向量和类中心向量求欧氏距离得出;在第i个类求得所有词与类中心的距离后,对第i个类的所有词按词的距离进行升序排序,得到词集合其中代表该类下的全部的词,词的距离沿下标增大而增大;判断第i个类中词dj的可迁移性只需满足以下条件:
37、
38、即判断为可迁移的词,如果不满足,则判断为不可迁移的词;
39、在细粒度过滤中,目标语言伪标注数据中每条句子的词都被划分为可迁移词和不可迁移的词,统计对于每一条句子来说,统计不可迁移的词和可迁移的词的数量,分别记作nun,ntran。用于控制句子是否被过滤掉,当过滤下列两个条件:
40、nun≥knum
41、rtran≤kpro
42、其中,rtran是ntran与x的句子长度n的比值。knum是由用户指定的句子x中不可迁移的词的数量,kpro是由用户指定的句子x中不可迁移的词的数量与样本长度的比例,两者都是可调的超参数。一个目标语言伪标签数据集的全部句子满足其中一个条件之一即可,用户可根据目标语言的不同进行调试,选择确定一个过滤条件即可。
43、优选地,所述将细粒度过滤后的伪标签数据集进行知识蒸馏训练用于目标语言的命名实体识别模型;包括:
44、获得的细粒度过滤后的数据集通过知识蒸馏训练命名实体识别模型,命名实体识别模型初始化模型的编码器使用的是mbert,分类器是线性层;知识蒸馏训练过程使用的损失函数是均方误差mse,损失计算方法如下:
45、
46、其中,是目标语言句子x的伪标签,pθ(yt-ner)是的目标语言句子x的预测标签;通过最小模拟均方误差的损失,对学生模型的数据伪标签进行监督和训练;通过目标语言的测试集,对命名实体识别模型的作最后的评估;为了确保实体标签遵ner标记方案,最终预测标签由维特比算法解码;在知识蒸馏中,调试超参数knum和kpro。
47、本发明的第二个目的可以通过采取如下技术方案达到:
48、一种自监督伪标签优化的跨语言命名实体识别系统,所述系统包括:
49、伪标签数据集获取模型,用于根据用户获得目标语言伪标签数据集的功能需求,利用源语言数据集训练源语言模型来并利用源语言模型为用户进行目标语言的标注工作,提供给用户目标语言的伪标签数据集;
50、粗粒度选择模型,用于将目标语言的伪标签数据集进行粗粒度选择;
51、细粒度选择模型,用于将粗粒度选择后的伪标签数据集进行细粒度过滤;
52、数量处理模型,用于将细粒度过滤后的伪标签数据集进行知识蒸馏训练用于目标语言的命名实体识别模型。
53、本发明通过根据用户获得目标语言伪标签数据集的功能需求,利用源语言数据集训练源语言模型来并利用源语言模型为用户进行目标语言的标注工作,提供给用户目标语言的伪标签数据集;将目标语言的伪标签数据集进行粗粒度选择;将粗粒度选择后的伪标签数据集进行细粒度过滤;将细粒度过滤后的伪标签数据集进行知识蒸馏训练用于目标语言的命名实体识别模型。可以充分利用预训练语言模型蕴含的知识,也充分利用带标签的源语言数据和廉价易获得的无标注目标语言数据;通过基于粗粒度选择与细粒度过滤的跨语言命名实体识别方法可以选择高质量的伪标签数据。包含的粗粒度选择和细粒度过滤两个模块有效结合,从粗粒度与细粒度,使带标签源语言数据集的知识充分迁移到目标语言上。
- 还没有人留言评论。精彩留言会获得点赞!