一种基于深度学习的情感分析方法、系统及设备
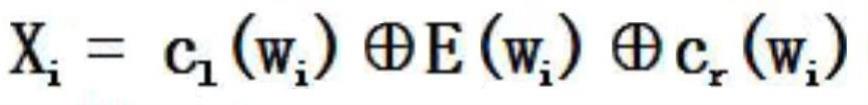
本发明涉及情感分析,具体为一种基于深度学习的情感分析方法、系统及设备。
背景技术:
1、情感分类是对带有感情色彩的主观性文本进行分析、推理的过程,即分析其情感倾向为正面或是反面,在研究中文情感分析的方法中,目前可分为三类:基于情感词典、基于机器学习和深度学习的方法。基于情感词典的方法需要建立情感词典,分类主要取决于情感词典的质量和大小的影响,然而构建一个完备的情感词典是比较难的,并且更新词典需要大量的人力和财力。基于机器学习的方法需要大量的人工来标注,使用机器学习模型进行训练,并使用训练后的分类器分析文本的情感倾向,该方法由于缺乏泛化能力,以至于不能在多种场合中使用,后来,人们提出了基于深度学习的情感分析方法,使用卷积神经网络来实现文本分类,并将神经网络用于情感分类任务。
2、现有中文短文本情感分类算法存在数据海量、用词不规范,传统bert模型对相同句式的词语语义区分不明显、多层transformer训练比较慢,耗时长,需要能耗高,因此提出一种基于深度学习的情感分析方法、系统及设备,以解决上述问题。
技术实现思路
1、本发明提供如下技术方案:一种基于深度学习的情感分析系统及设备,包括bert模型、transformer双向预测、rcnn模型和attention注意力机制,所述bert模型包括词嵌入,词嵌入包括bert预训练模型和bert模型,bert预训练模型由输入层、编码层和输出层组成,bert模型在进行预训练时,基于masked language modeling(带掩码的语言模型)和.next sentence prediction(预测下一条语句)两种类型的任务,输入层由词向量、块向量和位置向量组成。
2、优选的,所述词向量用于通过词向量矩阵将输入文本转换成实值向量表示,假设输入序列x对应的独热向量表示为:et∈rnx m,则对应的词向量表示vt;
3、vt=etwt
4、wt∈r|m|xe:表示可以训练的词向量矩阵,|m|表示词表大小;e表示词向量的维度。
5、优选的,所述块向量为编码当前的词是属于哪一块,当前词所在的块序号(从0开始);输入序列是一个单个块(单句文本分类),所有词的块编码为0;输入是两个块(句对文本分类),第一句每个字对应块编码为0,第二句每个词对应为1,开始和结束对应编码均为0,利用可训练的块向量矩阵;ws∈r|s|xe(|s|表示块数量;e表示块向量维度),将块编码es∈rnx|s|转换为实值向量得到块向量vs。
6、vs=esws
7、优选的,所述位置向量为位置向量编码每个词的绝对位置,将输入序列中每个词按照其下标顺序依次转换成位置独热编码,然后利用位置向量矩阵wp∈rnxe(n表示最大长度,e表示位置向量的维度)将独热码ep∈rnxn转换成实值向量,得到位置向量vp。
8、vp=epwp
9、优选的,所述transformer双向预测包括词向量与位置编码、自注意力机制和残差连接与layer normal iation,词向量与位置编码用于识别出语言中的顺序关系,通过定义inputs的维度大小[batch_size,sequence_length,embedding dimention],sequence_length指的是一句话的长度如果是中文的话我们可以理解为一句话中所有字的数量,embedding dimention指的是每个字向量的维度。
10、x=embeddinglookup(x)+positi onalencoding
11、x∈rbatch_size*seqlen*embed_dim
12、优选的,所述自注意力机制用于得到attention:
13、具体操作为;
14、3、通过们输入的sequencexi,这里的每一个xi可以理解为每个词(字);
15、4、将xi通过embedding的方式乘上w的方式得到经过embedding后的输入ai,对于每一个ai其拥有三个矩阵,分别为query矩阵(查询其他词的矩阵)、key矩阵(用来别其他词查询的矩阵)、value矩阵(用来表示被提取信息值的矩阵);
16、3、通过ai分别与三个矩阵相乘得到q,k,v,最后拿每一个q对每一个key矩阵对k点乘做attention。
17、q=xiwq
18、k=x1wk
19、v=xiwv
20、xattenton=self atention(q,k,l)
21、优选的,所述残差连接与layernormalization用于得到残差连接,
22、具体操作为;
23、1、通过权利要求7中得到的注意力矩阵加权之后的v,也就是attention(q,k,v),将其转置,使其和xembedding的维度一致,也就是[batch_size,sequence_length,embedding dimension];
24、2、把他们加起来做残差连接,直接进行元素相加,因为他们的维度一致:
25、xattention=self atention(q,k,l)+xembedding
26、3、在之后的运算里,每经过一个模块的运算,都要把运算之前的值和运算之后的值相加,从而得到残差连接,训练的时候可以使梯度直接走捷径反传到最初始层:
27、xattention=layer norm(xattention)
28、优选的,所述rcnn模型包括输入层、卷积层、拼接层、池化层、全连接层和输出层,所述卷积级用于采用多个卷积对输入的矩阵进行检测,并进行卷积操作,最后通过对所得到的部分特征进行检测,从而得到卷积核心的特征,池化层用于从卷积得到的特征矢量,池化层从特征矢量中抽取出重要的特征矢量,从而产生一个固定尺寸的矩阵,最终,将数据传送至整个连接层次进行数据的处理和归类本文使用rcnn模型深度提取局部特征,对bert文本最后一层输出的序列特征(f1,e2…en)给予权重作为卷积操作的词嵌入,提取特征序列中每个实体的局部特征;
29、卷积特征的卷积操作计算过程如下:
30、1、卷积层:如果一个句子有n个词,每个词的词向量长度为m,那输入矩阵就是nxm,这就类似于通道为1的“图像”,然后经过个数为k的不同卷积核大小(region_size)的一维卷积,设不同大小卷积核的个数(filters)为t,卷积核宽度与词向量维度一致为m,高度h是超参数。共得到k*t个特征图(feature map),经结合递归结构学习单词的左上文和右下文的信息,将单词的左上文、嵌入向量以及由上文进行连接,并计算单词的隐藏语义特征向量;
31、其计算公式如下,其中是按行拼接,f为非线性激活函数,使用b表示偏至项.
32、c1=f(w(1)c1(wi-1)+w(s1)e(wi-1))
33、cr=f(w(1)cx(wi-1)+w(sr)e(wi+1))
34、其中;c1(wi)表示字词wi的左上文,cr(wi)表示字词wi的右上文,e(wi)表示嵌入向量,w(1)为权重矩阵,从上一个字词的左上文)c1(wi)传递到下一字词的左上文)c1(wi+1),w(s1)表示结合当前词语语义e(wi)传递到下一个词的左上文中;
35、
36、yi(2)二f(w(2)·xi+b(2))
37、矩阵中的每一行表示t个卷积核在句子矩阵相同位置上的提取结果,行向量vi表示了针对句子某个位置的提取出的所有卷积特征。
38、2、池化层:不同尺寸的卷积核得到的特征大小不同,对每个feature map使用池化函数,使它们的维度相同,之后进行拼接,得到最终的k*m维列向量,通过利用最大池化层将卷积得到的列向量的最大值提取出来,从而使pooling操作之后获得一个num_filters维的行向量,即将每个卷积核的最大值连接起来,以此来消除句子之间长度不同的差异。
39、y(3)=max(yi(2))(i=1,2,3…)
40、3、输出层:从上述max-pooling layer中取得文本中最具有代表性的关键特征,再用全连接层输出,最后通过softmax函数来获得分类的结果。
41、y(4)=w(4)y(3)+b(4)
42、
43、优选的,所述attention注意力机制用于帮助模型对输入的每个部分xi赋予不同的权重,抽取出更加关键及重要的信息,做出更加准确的情感分类的机极性判断,同时不会对模型的计算和存储带来更大的开销;
44、在nlp中,nlp包括三个关键术语:1.query可被认为是问题,2.key类似搜索引擎的关键字,用于检索,3.value则对应的结果,训练神经网络的训练集由q、k、v组成,source中的构成元素可认为是由一系列的<key,value>数据对构成,此时给定target中的某个元素query,通过计算query和各个key的相似性或者相关性,得到每个key对应value的权重系数,然后对value进行加权求和,即得到了最终的attention数值,因此本质上attention机制是对source中元素的value值进行加权求和,而query和key用来计算对应value的权重系数,即可以将其本质思想改写为如下公式:
45、
46、本文首先将rcnn深度提取文本上下文信息后的输出ht作为attention层的输入,假设词向量x1,x2,…,xn学习将注意力集中在特定的重要单词上时导出上下文向量gi,当预测句子类别时,该机制应重点关注句子中重要的词,将不同权重的词进行加权和组合:
47、
48、其中αi,j被称为attention权重,要求α≥0且αi,jxj=1,并通过softmax规范化来实现。描述attention机制的公式如下:
49、
50、
51、其中score值根据rcnn来计算,用来模拟字词的相关性,具有较大score值的x在上下文中占有更多的权重。
52、优选的,一种基于深度学习的情感分析方法,包括以下主要步骤;
53、s1:使用bert模型进行中文情感分类,并通过transformer进行信息提取,对语句进行多层双向预测,更好地理解句子的深层含义;
54、s2:利用结合注意力机制的rcnn模型进行深度提取,根据用户评论和舆论的倾向性分析出用户的正面情感与负面情感;
55、s3:通过人工智能、计算机科学的融合,对情感进行深度全面的分析。
56、有益效果
57、与现有技术相比,本发明提供了一种基于深度学习的情感分析方法、系统及设备,具备以下有益效果:
58、本发明通过使用bert模型进行中文情感分类,并通过transformer进行信息提取,对语句进行多层双向预测,更好地理解句子的深层含义,同时利用结合注意力机制的rcnn模型进行深度提取,能有效的根据用户评论和舆论的倾向性分析出用户的正面情感与负面情感,有助于企业以及政府通过相关的分析及时采取措施,挖掘出更大的社会价值,此外,本发明的中文情感分析还涉及到人工智能、计算机科学的融合,推动了人工智能的发展。
- 还没有人留言评论。精彩留言会获得点赞!