数字人内容生成系统及方法与流程
本申请涉及数字人内容生成,特别涉及一种数字人内容生成系统及方法。
背景技术:
1、借助于计算机硬件和深度学习的发展,数字人生成在近两年来取得了突出的进展,并逐步在各个领域落地。
2、相关技术中为了保证人脸的真实性,通过模型师手工雕刻贴图,需要积累大量的人工经验值并需要人工后处理微调,并且在渲染时,通常将三维模型和贴图集加载到渲染软件中,借助于渲染软件的物理渲染引擎对人体和人脸进行渲染。
3、然而,数字人生成过程中需要繁杂的人工操作流程,致使数字人内容生成效率低下;并且因物理渲染方式的局限,物理渲染中数字模型的线性化和材质表情与光照的合成等,致使生成的数字人与真实人差异大,甚至会产生“恐怖谷”问题,使数字人无法达到写实级应用。
技术实现思路
1、本申请提供一种数字人内容生成系统及方法,以解决相关技术需要大量人工操作流程致使数字人生产效率低下,受物理渲染方式的制约致使数字人与真实人差异大的问题,极大解放了人工操作流程,实现了系统自动化处理,提高了数字人制作效率,使渲染结果的光影信息、表情信息和材质信息都能与真人接近,达到了照片级的写实效果。
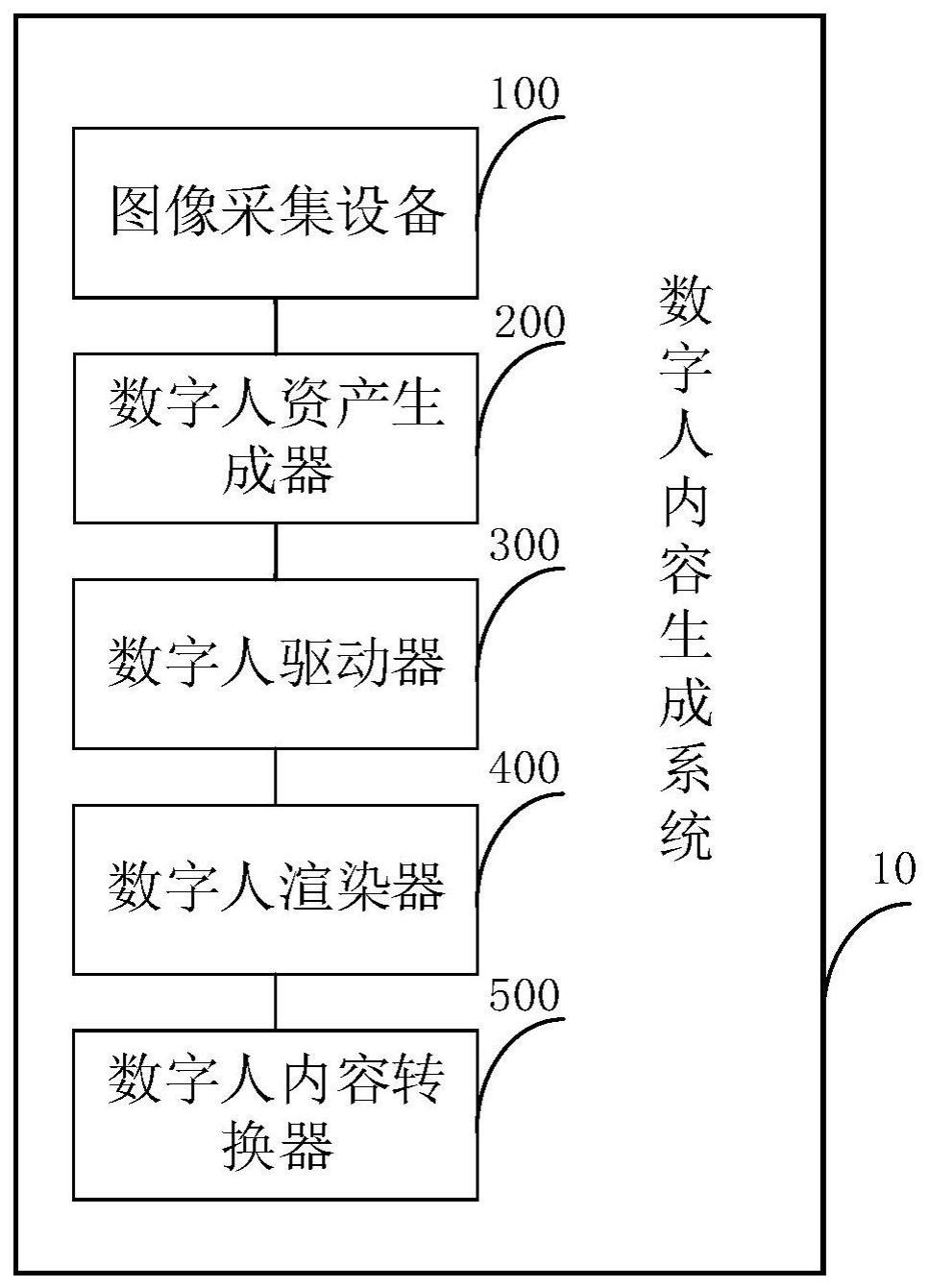
2、本申请第一方面实施例提供一种数字人内容生成系统,包括:图像采集设备、数字人资产生成器、数字人驱动器、数字人渲染器和数字人内容转换器,其中,所述图像采集设备用于获取目标图像序列;所述数字人资产生成器用于将所述目标图像序列转换为3d(three-dimensional,三维)数字人模型;所述数字人驱动器用于驱动所述3d数字人模型得到3d数字人模型动画序列;所述数字人渲染器用于将所述3d数字人模型和/或所述3d数字人模型动画序列转换为图像或图像序列;以及所述数字人内容转换器用于将所述渲染图像或图像序列转换为目标格式,得到数字人内容。
3、可选地,在一些实施例中,所述图像采集设备,包括:至少一个光源,用于对目标进行补光和/或标识。
4、可选地,在一些实施例中,所述数字人资产生成器包括模型建模器、模型重拓扑器、模型自动绑定器和模型贴图生成器中的至少一种。
5、可选地,在一些实施例中,所述模型建模器用于将所述目标图像序列进行建模,得到第一目标三维模型;所述模型重拓扑器用于将所述第一目标三维模型重拓扑得到第二目标三维模型;所述模型自动绑定器用于将所述第一目标三维模型和/或所述第二目标三维模型的网格顶点进行骨骼绑定和表情绑定,得到第三目标三维模型;所述模型贴图生成器用于根据所述目标图像序列和所述第一目标三维模型或所述第二目标三维模型或第三目标三维模型得到所述目标三维模型的贴图集。
6、可选地,在一些实施例中,所述模型建模器包括深度学习建模器、单视点建模器和多视点建模器中的至少一种。
7、可选地,在一些实施例中,所述数字人渲染器,包括:第一渲染器,用于将所述模型贴图生成器生成的所述目标三维模型的贴图集渲染到3d数字人模型得到第一渲染结果;第二渲染器,用于对所述第一渲染结果进行ai(artificial intelligence,人工智能)渲染得到第二渲染结果。
8、可选地,在一些实施例中,所述数字人渲染器,还包括:第三渲染器,用于将所述模型贴图生成器生成的所述目标三维模型的贴图集进行ai渲染得到第三贴图结果,并将所述第三贴图结果进行渲染得到第三渲染结果。
9、可选地,在一些实施例中,所述数字人渲染器,还包括:ai渲染器,用于将所述模型贴图生成器生成的贴图渲染的结果进行ai渲染,得到照片级写实渲染结果。
10、可选地,在一些实施例中,所述数字人渲染器,还用于:基于预先训练的4d模型,对所述第一渲染结果或所述第三贴图结果进行ai渲染,得到第一ai渲染结果
11、可选地,在一些实施例中,所述数字人渲染器,还用于:将所述第一渲染结果或所述第三贴图结果进行贴图ai渲染,得到第二ai渲染结果。
12、可选地,在一些实施例中,所述数字人驱动器包括人体动作驱动器、人脸表情驱动器、人体衣服驱动器和人体模型变形器中的至少一种。
13、可选地,在一些实施例中,所述数字人内容转换器,生成一种预设视点或预设视点轨迹的视频内容。
14、可选地,在一些实施例中,所述数字人内容转换器,生成可交互视点、任意视点或自由视点的视频内容中的至少一种。
15、本申请第二方面实施例提供一种数字人内容生成方法,采用上述的数字人内容生成系统,其中,所述方法包括以下步骤:通过所述图像采集设备获取目标图像序列;通过所述数字人资产生成器将所述目标图像序列转换为3d数字人模型;通过所述数字人驱动器驱动所述3d数字人模型得到3d模型数字人动画序列;通过所述数字人渲染器将所述3d数字人模型和/或所述3d模型数字人动画序列转换为图像或图像序列;以及通过所述数字人内容转换器将渲染图像或图像转换为目标格式,得到数字人内容。
16、由此,通过图像采集设备获取目标图像序列,并通过数字人资产生成器对获取到的目标图像序列进行三维模型解算、重拓扑、自动绑定和贴图计算,得到3d数字人模型并通过数字人驱动器对得到的3d数字人模型进行人体和表情驱动,得到3d数字人动画序列,并对3d数字人模型或3d数字人动画序列或3d数字人模型和3d数字人动画序列进行物理渲染和ai渲染得到照片级写实数字人模型或动画序列,并通过数字人内容转换器对照片级写实数字人模型进行转换后保存,并对照片级写实数字人动画序列进行序列转换或流媒体转换后保存或输出,得到数字人内容。由此,解决相关技术需要大量人工操作流程致使数字人生产效率低下,受物理渲染方式的制约致使数字人与真实人差异大的问题,极大解放了人工操作流程,实现了系统自动化处理,提高了数字人制作效率,使渲染结果的光影信息、表情信息和材质信息都能与真人接近,达到了照片级的写实效果。
17、本申请附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本申请的实践了解到。
技术特征:
1.一种数字人内容生成系统,其特征在于,包括:
2.根据权利要求1所述的系统,其特征在于,所述图像采集设备,包括:至少一个光源,用于对目标进行补光和/或标识。
3.根据权利要求1所述的系统,其特征在于,所述数字人资产生成器包括模型建模器、模型重拓扑器、模型自动绑定器和模型贴图生成器中的至少一种。
4.根据权利要求3所述的系统,其特征在于,其中,
5.根据权利要求3或4所述的系统,其特征在于,所述模型建模器包括深度学习建模器、单视点建模器和多视点建模器中的至少一种。
6.根据权利要求1所述的系统,其特征在于,所述数字人渲染器,包括:
7.根据权利要求6所述的系统,其特征在于,所述数字人渲染器,还包括:
8.根据权利要求7所述的系统,其特征在于,所述数字人渲染器,还包括:
9.根据权利要求7所述的系统,其特征在于,所述数字人渲染器,还用于:
10.根据权利要求7所述的系统,其特征在于,所述数字人渲染器,还用于:
11.根据权利要求1所述的系统,其特征在于,所述数字人驱动器包括人体动作驱动器、人脸表情驱动器、人体衣服驱动器和人体模型变形器中的至少一种。
12.根据权利要求1所述的系统,其特征在于,所述数字人内容转换器,还用于:
13.根据权利要求1所述的系统,其特征在于,所述数字人内容转换器,还用于:
14.一种数字人内容生成方法,其特征在于,采用如权利要求1-13任一项所述的数字人内容生成系统,其中,所述方法包括以下步骤:
技术总结
本申请涉及一种数字人内容生成系统及方法,其中,系统包括:图像采集设备、数字人资产生成器、数字人驱动器、数字人渲染器和数字人内容转换器,其中,图像采集设备用于获取目标图像序列;数字人资产生成器用于将目标图像序列转换为3D数字人模型;数字人驱动器用于驱动3D数字人模型得到3D数字人动画序列;数字人渲染器用于将3D数字人模型和/或3D数字人动画序列转换为图像或图像序列;数字人内容转换器用于将渲染图像或图像序列转换为目标格式,得到数字人内容。由此,解决相关技术需要大量人工操作流程致使数字人生产效率低下以及传统渲染方法存在局限的问题,提高了数字人制作效率,达到了照片级的写实效果。
技术研发人员:李子旭,杜华
受保护的技术使用者:北京元客视界科技有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!