传感器数据中三维对象的感知的制作方法
本公开涉及在例如图像、激光雷达/雷达点云等传感器数据中捕获的三维(3d)对象的感知。
背景技术:
1、在传感器数据中感知3d对象的技术有许多不同的应用。计算机视觉泛指计算机对图像的解释。本文中的术语“感知”包括更广泛范围的传感器模态,并包括用于从单个模态或多个模态(诸如图像、立体深度、单声道深度、激光雷达和/或雷达)的传感器数据中提取对象信息的技术。可以从2d或3d传感器数据中提取3d对象信息。例如,运动结构(structurefrom motion,sfm)是一种允许从多个2d图像重建3d对象的成像技术。
2、感知系统是自动驾驶车辆(autonomous vehicle,av)的重要部件。自动驾驶车辆(av)是一种配备有传感器和控制系统的车辆,传感器和控制系统使其能够在无人控制其行为的情况下运行。自动驾驶车辆配备有使其能够感知其物理环境的传感器,这样的传感器包括例如摄像头、雷达和激光雷达。自动驾驶车辆配备有适当编程的计算机,该适当编程的计算机能够处理从传感器接收的数据,并基于传感器感知的背景做出安全和可预测的决策。自动驾驶车辆可以是全自动驾驶的(至少在某些情况下,它被设计为在无人监督或干预的情况下运行)或半自动驾驶的。半自动驾驶系统需要不同程度的人工监管和干预,此类系统包括高级驾驶员辅助系统和三级自动驾驶系统。
3、此类车辆不仅必须在人员和其他车辆之间执行复杂的操纵,而且通常它们必须这样做的同时保证严格限制例如与环境中的其他代理碰撞的不良事件发生的概率。为了使自动驾驶车辆能够安全地进行规划,它能够准确可靠地观察其环境是至关重要的。这包括需要对车辆附近的道路结构进行准确可靠的检测。
4、支持实时规划的要求限制了自动驾驶车辆上可能使用的感知技术类别。给定的感知技术可能由于它是非因果的(需要对未来的了解)或非实时的(鉴于自动驾驶车辆的车载计算机系统的限制,无法在自动驾驶车辆车载实时实现)而不适用于此目的。
技术实现思路
1、“离线”感知技术与“在线”感知相比可以提供更好的结果。后者是指有利于实时应用的感知技术的子集,例如自动驾驶车辆车载的实时运动规划。某些感知技术可能不适用于此目的,但仍有许多其他有用的应用。例如,用于测试和开发复杂机器人系统(如自动驾驶车辆)的某些工具需要某种形式的“地面实况(ground truth)”。给定真实世界的“运行”,即配备传感器的车辆(或机器)遇到某些驾驶(或其他)场景,最严格意义上的地面实况意味着场景的“完美”表示,没有感知错误。然而,这种地面实况在现实中不可能存在,离线感知技术可以用于为给定的应用提供质量足够的“伪地面实况”。从运行的传感器数据中提取的伪地面实况可以用作模拟的基础,例如在模拟器中重建场景或场景的某些变体以在模拟中测试自动驾驶车辆规划器;评估真实世界中的驾驶性能,例如使用离线处理来提取代理轨迹(空间和运动状态),并根据预定义的驾驶规则来评估代理轨迹;或者作为评估在线感知结果的基准,例如通过将车载检测与伪地面实况进行比较作为估计感知误差的手段。另一个应用是训练,例如,其中,将经由离线处理提取的伪地面实况用作训练数据,以训练/重新训练在线感知部件。在任何上述应用中,离线感知可以用作繁重的手动注释的替代方案,或者以减少人工注释工作量的方式补充手动注释。值得注意的是,除非另有说明,否则本文中使用的术语“地面实况”不是最严格的意义上的,而是包括通过离线感知、手动注释或其组合获得的伪地面实况。
2、本文提供了各种感知技术。虽然通常设想本技术将更适合离线应用,但不排除在线应用的可能性。在线应用的可行性可能会随着未来技术的进步而提高。
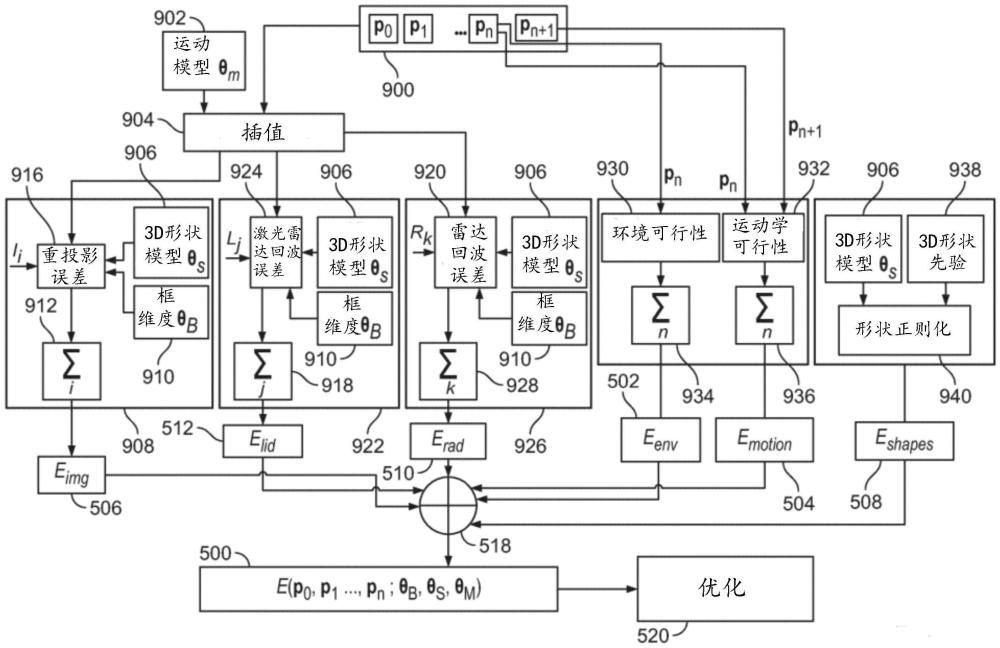
3、本文的第一方面提供了一种对在多个传感器模态的传感器数据的多个时间序列中捕获的3d对象进行定位和建模的计算机实现方法。该方法包括优化应用于传感器数据的多个时间序列的代价函数。代价函数随时间和多个传感器模态聚合,并根据一组变量定义。该组变量包括:3d对象模型的一个或更多个形状参数,以及3d对象模型的姿态的时间序列。每个姿态包括3d对象位置和3d对象定向。代价函数惩罚传感器数据的多个时间序列与该组变量之间的不一致。对象属于已知对象类,并且3d对象模型或代价函数对与已知对象类相关联的预期3d形状信息进行编码,从而以优化代价函数为目的,通过调整每个姿态和形状参数来对3d对象进行在多个时刻的定位和对3d对象进行建模。
4、在实施例中,代价函数的变量可以包括针对于3d对象的运动模型的一个或更多个运动参数,并且代价函数还可以惩罚姿态的时间序列和运动模型之间的不一致,从而以优化代价函数为目的,通过调整每个姿态、形状参数和运动参数来对该对象进行定位和建模,以及对该对象的运动进行建模。
5、传感器数据的多个时间序列中的至少一个包括在时间上不与姿态的时间序列中的任何姿态对准的传感器数据段。运动模型可用于根据姿态的时间序列计算在时间上与传感器数据段相符的插值姿态,其中,代价函数惩罚传感器数据段与插值姿态之间的不一致。
6、传感器数据的至少一个时间序列可以包括图像的时间序列,并且传感器数据段可以是图像。
7、传感器数据的至少一个时间序列可以包括激光雷达数据的时间序列或雷达数据的时间序列,传感器数据段是单独的激光雷达回波或雷达回波,并且插值姿态与激光雷达回波或者雷达回波的回波时间相符。
8、变量还可以包括用于缩放3d对象模型的一个或更多个对象维度,形状参数独立于对象维度。替代地,3d对象模型的形状参数可以对3d对象形状和对象维度二者进行编码。
9、代价函数可以在姿态违反环境限制时附加地惩罚每个姿态。
10、环境限制可以相对于已知3d道路表面来定义。
11、每个姿态可以用于相对于道路表面定位3d对象模型,并且环境限制可以在3d对象模型不位于已知3d道路表面上时惩罚每个姿态。
12、多个传感器模态可以包括图像模态、激光雷达模态和雷达模态中的两个或更多个。
13、传感器模态中的至少一个传感器模态可以使得姿态和形状参数不能单独从该传感器模态中唯一地导出。
14、传感器数据的多个时间序列中的一个可以是对测量的多普勒速度进行编码的雷达数据的时间序列,其中,姿态的时间序列和3d对象模型用于计算预期多普勒速度,并且代价函数惩罚所测量的多普勒速度和预期多普勒速度之间的差异。
15、传感器数据的多个时间序列中的一个可以是图像的时间序列,并且代价函数可以惩罚(i)图像与(ii)姿态的时间序列和3d对象模型之间的聚合重投影误差。
16、可以将语义关键点检测器应用于每个图像,并且可以在对象的语义关键点上定义重投影误差。
17、传感器数据的多个时间序列中的一个可以是激光雷达数据的时间序列,其中,代价函数基于激光雷达点和由3d对象模型的参数定义的3d表面之间的点到表面的距离,其中,点到表面的距离遍及激光雷达数据的所有点聚合。
18、3d对象模型可以被编码为距离场。
19、在3d对象模型中,可以对预期3d形状信息进行编码,该3d对象模型是从包括已知对象类的示例对象的训练数据集中学习的。
20、在代价函数的正则化项中,可以对预期3d形状信息进行编码,代价函数的正则化项惩罚3d对象模型与已知对象类的3d形状先验之间的差异。
21、该方法可以包括使用对象分类器从多个可用对象类中确定对象的已知类,多个对象类与相应的预期3d形状信息相关联。
22、可以将相同的形状参数应用于用于建模刚性对象的姿态的时间序列中的每个姿态。
23、3d对象模型可以是可变形模型,其中,形状参数中的至少一个遍及帧而变化。
24、此处,3d感知被公式化为一个代价函数优化问题,其目的是以最小化代价函数中定义的某些误差的总体测量的方式来调整3d对象模型的形状和姿态的时间序列。以结合对象类的附加知识和通常与已知对象类相关联的形状特征的方式,通过聚合遍及时间和多个传感器模态二者的总体误差来实现高水平的感知精度。
25、本文的其他方面提供了一种计算机系统,包括被配置为实现上述方面或实施例中任一方面的方法的一个或更多个计算机,以及被配置为对计算机系统进行编程以实现上述方法的计算机程序代码。
- 还没有人留言评论。精彩留言会获得点赞!