一种标签排序方法、装置、设备及存储介质与流程
本公开涉及互联网,尤其涉及一种标签排序方法、装置、设备及存储介质。
背景技术:
1、随着网络技术飞速发展,各种多媒体资源已经成为大数据的主体。标签可以精确提炼多媒体资源的内容,利用标签可以实现为订阅标签的用户精准推送多媒体资源。
2、但是,多媒体资源通常对应多个标签,例如,打篮球的视频,对应的标签可以包括:运动、男生、操场、篮球等。由于不同的标签与多媒体资源的关联程度不同,当关联程度越高时,多媒体资源更容易引起订阅该标签的用户的兴趣。因此,对多媒体资源的多个标签进行排序,是多媒体资源的推广过程中可以改进的地方。
技术实现思路
1、本公开提供一种标签排序方法、装置、设备及存储介质,可以实现对多媒体资源的多个标签进行准确排序。
2、本公开实施例的技术方案如下:
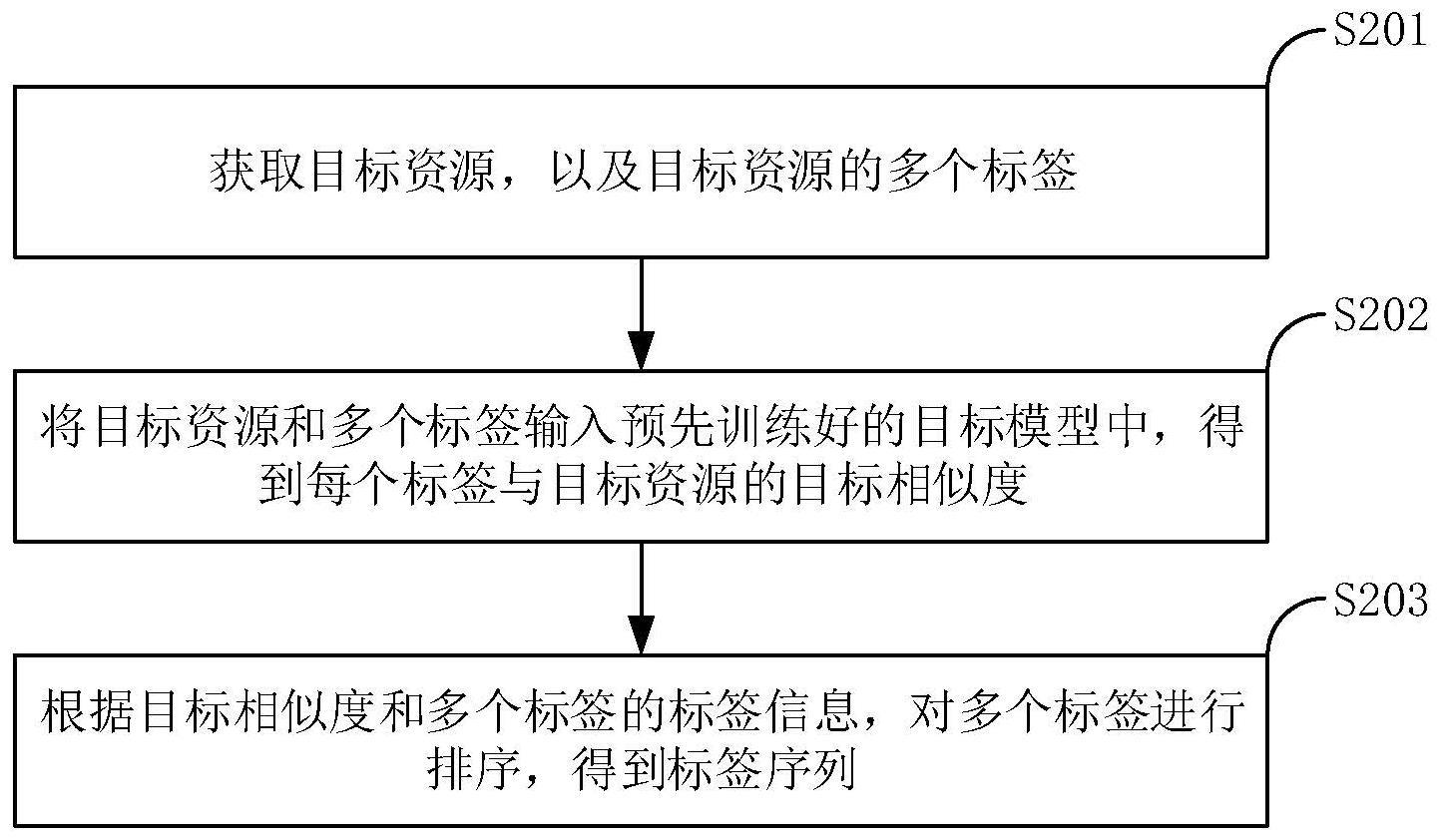
3、根据本公开实施例的第一方面,提供一种标签排序方法,包括:获取目标资源,以及目标资源的多个标签;将目标资源和多个标签输入预先训练好的目标模型中,得到每个标签与目标资源的目标相似度;目标模型是根据样本数据训练初始模型得到的;样本数据包括:样本资源,以及与样本资源对应的多个样本标签;根据目标相似度和多个标签的标签信息,对多个标签进行排序,得到标签序列。
4、可选的,初始模型包括第一特征提取模型、第二特征提取模型;标签排序方法,还包括:获取样本数据;将样本资源输入第一特征提取模型,得到样本资源的样本资源特征;将每个样本标签输入第二特征提取模型,得到每个样本标签的样本标签特征;当第二特征提取模型为多层神经网络模型时,样本标签特征包括多层神经网络模型中的多个隐含层数据。
5、可选的,每个样本标签包括:多个字符;第二特征提取模型包括:bert模型;标签排序方法,还包括:对输入的每个样本标签的至少一个字符进行遮蔽,得到每个样本标签对应的遮蔽训练数据;遮蔽训练数据包括:每个样本标签中,与至少一个字符一一对应的至少一个遮蔽位置;将遮蔽训练数据输入bert模型,得到遮蔽位置的字符的预测值。
6、可选的,标签排序方法,还包括:获取第一损失和第二损失;第一损失用于表征样本资源特征与样本标签特征的差异;第二对比损失用于表征字符的预测值与字符的真实值的差异;根据模型整体损失训练初始模型,直至满足收敛条件,得到目标模型;模型整体损失是根据损失集合得到的;损失集合包括:第一损失和第二损失。
7、可选的,初始模型还包括:判别模型;损失集合,还包括:判别模型的对抗损失;标签排序方法,还包括:将样本数据输入判别模型,得到样本数据的数据类型的预测值;数据类型用于表征样本数据为样本资源或者样本标签;对抗损失用于表征数据类型的预测值与数据类型的真实值的差异。
8、可选的,根据样本数据训练初始模型,直至模型整体损失满足收敛条件,得到目标模型的方法,包括:将训练数据输入初始模型,确定软目标标签,以及模型整体损失;训练数据包括样本数据;软目标标签包括:多个样本标签中,对应的样本标签特征与样本资源特征的相关度大于预设阈值的标签;当模型整体损失不满足收敛条件时,更新初始模型的模型参数,并将软目标标签和样本资源作为训练数据,输入更新后的初始模型中,直至更新后的初始模型对应的模型整体损失满足收敛条件。
9、可选的,标签信息包括:标签的维度信息和/或属性信息;维度信息用于表征标签的类型特征;属性信息用于表征标签的数据来源、出现位置、相互关系中的至少一种;根据目标相似度和多个标签的标签信息,对多个标签进行排序,得到标签序列的方法,包括:根据目标相似度,对多个标签进行排序,得到初始序列;根据标签信息和预设优先级策略,更新初始序列,得到标签序列。
10、根据本公开实施例的第二方面,提供一种标签排序装置,包括:获取单元和第一处理单元;获取单元,被配置为执行获取目标资源,以及目标资源的多个标签;第一处理单元,被配置为执行将目标资源和多个标签输入预先训练好的目标模型中,得到每个标签与目标资源的目标相似度;目标模型是根据样本数据训练初始模型得到的;样本数据包括:样本资源,以及与样本资源对应的多个样本标签;第一处理单元,还被配置为执行根据目标相似度和多个标签的标签信息,对多个标签进行排序,得到标签序列。
11、可选的,初始模型包括第一特征提取模型、第二特征提取模型;该标签排序装置,还包括:第二处理单元;第二处理单元,被配置为执行获取样本数据;将样本资源输入第一特征提取模型,得到样本资源的样本资源特征;将每个样本标签输入第二特征提取模型,得到每个样本标签的样本标签特征;当第二特征提取模型为多层神经网络模型时,样本标签特征包括多层神经网络模型中的多个隐含层数据。
12、可选的,每个样本标签包括:多个字符;第二特征提取模型包括:bert模型;第二处理单元,还被配置为执行对输入的每个样本标签的至少一个字符进行遮蔽,得到每个样本标签对应的遮蔽训练数据;遮蔽训练数据包括:每个样本标签中,与至少一个字符一一对应的至少一个遮蔽位置;将遮蔽训练数据输入bert模型,得到遮蔽位置的字符的预测值。
13、可选的,第二处理单元,还被配置为执行获取第一损失和第二损失;第一损失用于表征样本资源特征与样本标签特征的差异;第二对比损失用于表征字符的预测值与字符的真实值的差异;根据样本数据训练初始模型,直至模型整体损失满足收敛条件,得到目标模型;模型整体损失是根据损失集合得到的;损失集合包括:第一损失和第二损失。
14、可选的,初始模型还包括:判别模型;损失集合,还包括:判别模型的对抗损失;第二处理单元,还被配置为执行将样本数据输入判别模型,得到样本数据的数据类型的预测值;数据类型用于表征样本数据为样本资源或者样本标签;对抗损失用于表征数据类型的预测值与数据类型的真实值的差异。
15、可选的,第二处理单元,具体被配置为执行将训练数据输入初始模型,确定软目标标签,以及模型整体损失;训练数据包括样本数据;软目标标签包括:多个样本标签中,对应的样本标签特征与样本资源特征的相关度大于预设阈值的标签;当模型整体损失不满足收敛条件时,更新初始模型的模型参数,并将软目标标签和样本资源作为训练数据,输入更新后的初始模型中,直至更新后的初始模型对应的模型整体损失满足收敛条件。
16、可选的,标签信息包括:标签的维度信息和/或属性信息;维度信息用于表征标签的类型特征;属性信息用于表征标签的数据来源、出现位置、相互关系中的至少一种;第一处理单元,具体被配置为执行根据目标相似度,对多个标签进行排序,得到初始序列;根据标签信息和预设优先级策略,更新初始序列,得到标签序列。
17、根据本公开实施例的第三方面,提供一种电子设备,可以包括:处理器和用于存储处理器可执行指令的存储器;其中,处理器被配置为执行指令,以实现上述第一方面中任一种可选的标签排序方法。
18、根据本公开实施例的第四方面,提供一种计算机可读存储介质,计算机可读存储介质上存储有指令,当计算机可读存储介质中的指令由电子设备的处理器执行时,使得电子设备能够执行上述第一方面中任一种可选的标签排序方法。
19、根据本公开实施例的第五方面,提供一种计算机程序产品,包含指令,当其在电子设备的处理器上运行时,使得电子设备执行上述第一方面中任一种可选的标签排序方法。
20、本公开提供的技术方案至少带来以下有益效果:
21、基于上述任一方面,本公开中,在获取到目标资源,以及目标资源的多个标签之后,可以将目标资源和多个标签,输入预先训练好的目标模型中,得到每个标签与目标资源的目标相似度。其中,目标模型是根据样本数据训练初始模型得到的。样本数据包括:样本资源,以及与样本资源的多个样本标签。然后,可以根据目标相似度和多个标签的标签信息,对多个标签进行排序,得到标签序列。由于本公开融合了考虑标签与资源的相似度,以及标签自身的标签信息,因此,可以实现对目标资源的多个标签的合理排序,进而使得目标资源的推广可以更精准地契合用户的兴趣标签,提高推广效率。
- 还没有人留言评论。精彩留言会获得点赞!