一种文本数据的处理终端查找方法与流程
1.本发明涉及文本数据处理技术领域,具体涉及一种文本数据的处理终端查找方法。
背景技术:
2.在事务处理系统中,用户大多先在输入界面输入文本数据,然后工作人员基于文本数据进行分类,按照文本数据的类别将文本数据分发到对应的处理终端上进行处理,具体步骤如下:先人工判断文本数据所属的主分类号,然后根据其所属的主分类号进行数据分类;接着人工根据文本数据的主分类号查看文本数据内容,并依据经验确定文本数据的子分类号;然后人工依据子分类号进行任务派发,将文本数据发送到派发部门,派发部门接收到文本数据后依据文本数据的主分类号查看文本内容来确定文本数据的处理部门,处理部门对文本数据进行处理。然而这种处理方式在实际使用时存在以下不足:一方面都是通过人工判断,则需要大量的人工投入,导致效率较低;另外一方面,由于文本数据存在表述不准的可能性,会出现一定的误判可能性。
技术实现要素:
3.在鉴于背景技术的不足,本发明是提供了一种文本数据的处理终端查找方法,所要解决的技术问题是现有文本数据的处理终端的查找都是通过人工完成,效率较低。
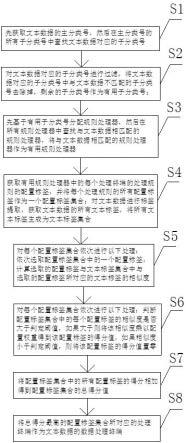
4.为解决以上技术问题,本发明提供了如下技术方案:一种文本数据的处理终端查找方法,先依据文本数据的主分类号中的子分类号生成对应的规则处理器,每个规则处理器中包括至少一个处理终端,一个处理终端中设有对应的处理规则;包括以下步骤:s1:先获取所述文本数据的主分类号,然后在所述主分类号的所有子分类号中查找所述文本数据对应的子分类号;s2:对所述文本数据对应的子分类号进行过滤,将所述文本数据对应的子分类号中与所述文本数据不匹配的子分类号去除掉,剩余的子分类号作为有用子分类号;s3:先基于所述有用子分类号分配规则处理器,然后在所有规则处理器中查找与所述文本数据相匹配的规则处理器,将与所述文本数据相匹配的规则处理器作为有用规则处理器;s4:获取所述有用规则处理器中的每个处理终端的处理规则的配置标签,并将每个处理规则的所有配置标签作为一个配置标签集合;对所述文本数据进行标签提取,获取文本数据的所有文本标签,将所有文本标签生成为文本标签集合;s5:对每个配置标签集合依次进行以下处理:依次选取配置标签集合中的一个配置标签,计算选取的配置标签与文本标签集合中与选取的配置标签所对应的文本标签的相似度;s6:对每个配置标签集合依次进行以下处理:判断配置标签集合中的每个配置标
签的相似度是否大于判定阈值,如果大于则将该相似度乘以配置权重得到该配置标签的得分值,如果相似度小于判定阈值,则将该配置标签的得分值置零;s7:将配置标签集合中的所有配置标签的得分相加得到配置标签集合的总得分值;s8:将总得分最高的配置标签集合所对应的处理终端作为所述文本数据的数据处理终端。
5.在某种实施方式中,步骤s2具体如下:s20:对每个所述文本数据对应的子分类号依次进行步骤s21;s21:将文本数据和子分类号带入到配置的表达式中,通过表达式计算子分类号是否满足要求,如果满足则进行步骤s22,否则将该子分类号过滤掉,结束步骤s21;s22:判断当前子分类号是否有特征值,如果有特征值则进行步骤s23,反之则结束步骤s22;s23:通过人工智能算法提取所述文本数据的文本特征值,并判断所述文本特征值是否与所述特征值相匹配,如果匹配则结束步骤s23,反之则将该子分类号过滤掉。
6.在某种实施方式中,步骤s3具体如下:s30:获取所有分配的规则处理器的匹配条件;s31:判断所述文本数据是否满足所述分配的规则处理器的匹配条件,如果满足则将满足的规则处理器作为有用规则处理器。
7.在某种实施方式中,在步骤s7中,当得到配置标签集合的总得分值时,将配置标签集合对应的处理规则打上所述总得分值,生成判断数据包,并将判断数据包存入总分集合中;步骤s8中,遍历所述总分集合中的判断数据包,在所述总分集合中查找总得分值最大的判断数据包,并将总得分值最大的判断数据包中的处理规则所对应的处理终端作为数据处理终端。
8.在某种实施方式中,所述规则处理器通过样本数据训练得到。
9.在某种实施方式中,还包括步骤s9,步骤s9如下:s9:获取所述数据处理终端中的处理规则,通过所述数据处理终端中的处理规则对所述文本数据进行处理,并将处理后的数据保存到数据库中。
10.本发明与现有技术相比所具有的有益效果是:本发明提前依据文本数据的类别生成对应的规则处理器,每个规则处理器中包括处理终端,当有文本数据输入时,先提前判断出与文本数据对应的子分类号,然后对子分类号进行过滤得到有用子分类号,接着依据有用子分类号分配对应的规则处理器,然后在所有规则处理器中确定有用规则处理器,然后分别计算有用规则处理器中的处理终端的处理规则的配置标签集合与文本数据的文本数标签集合的相似度,并基于相似度为每个处理终端生成一个总得分值,通过将总得分值最大的处理终端作为数据处理终端,从而可以替代人工进行文本数据的处理对象查找,提高了查找效率。
附图说明
11.图1为实施例中的本发明的流程图;图2为实施例中的本发明的步骤s2的流程图;
图3为实施例中的本发明的步骤s3的流程图。
具体实施方式
12.现在结合附图对本发明作进一步详细的说明。这些附图均为简化的示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
13.一种文本数据的处理终端查找方法,先依据文本数据的主分类号中的子分类号生成对应的规则处理器,每个规则处理器中包括至少一个处理终端,一个处理终端中设有对应的处理规则,处理规则用于对文本数据进行处理,在实际使用时,为了便于文本数据匹配到对应的处理终端,每个处理规则都设有配置标签。另外,本实施例中,规则处理器通过样本数据训练得到,通过不断的增加样本数量和样本类型可以得到更多不同的规则处理器,从而能对更多文本数据进行处理。另外为了能依据文本数据查找到对应的规则处理器,每个规则处理器都设置有对应的匹配条件。
14.如图1所示,本发明包括以下步骤:s1:先获取文本数据的主分类号,然后在主分类号的所有子分类号中查找文本数据对应的子分类号。
15.在实际使用时,主分类号是文本数据的大类,例如可以是教育、行政、环境和公共卫生等类别;子分类号是文本数据的小类,以环境这个主分类号为例,其下面可以有空气污染、河流污染、森林砍伐等多个子分类号。
16.在实际使用时,可以通过人工智能算法对文本数据进行关键词提取来得到文本数据的主分类号和子分类号。
17.在实际使用时,步骤s1得到的文本数据的主分类号为一个,但是得到的文本数据的子分类号可能有两个以上。
18.s2:对文本数据对应的子分类号进行过滤,将文本数据对应的子分类号中与文本数据不匹配的子分类号去除掉,剩余的子分类号作为有用子分类号。
19.在实际使用时,步骤s1中获得的文本数据的所有子分类号中有的是跟文本数据关联不大,因此需要对子分类号进行过滤,如图2所示,步骤s2具体如下:s20:对每个文本数据对应的子分类号依次进行步骤s21;s21:将文本数据和子分类号带入到配置的表达式中,通过表达式计算子分类号是否满足要求,如果满足则进行步骤s22,否则将该子分类号过滤掉,结束步骤s21;s22:判断当前子分类号是否有特征值,如果有特征值则进行步骤s23,反之则结束步骤s22;s23:通过人工智能算法提取文本数据的文本特征值,并判断文本特征值是否与特征值相匹配,如果匹配则结束步骤s23,反之则将该子分类号过滤掉。
20.s3:先基于有用子分类号分配规则处理器,然后在所有规则处理器中查找与文本数据相匹配的规则处理器,将与文本数据相匹配的规则处理器作为有用规则处理器。
21.具体地,步骤s3如下:s30:获取所有分配的规则处理器的匹配条件;s31:判断文本数据是否满足分配的规则处理器的匹配条件,如果满足则将满足的规则处理器作为有用规则处理器。
22.在实际使用时,当步骤s30中获取多个规则处理器时,在步骤s31中依次判断文本数据是否满足分配的规则处理器的匹配条件,如果在所有规则处理器都没判断完前就找到了与文本数据相匹配的规则处理器,则不对剩余的规则处理器进行判断,直接将该规则处理器作为有用规则处理器。
23.s4:获取有用规则处理器中的每个处理终端的处理规则的配置标签,并将每个处理规则的所有配置标签作为一个配置标签集合;对文本数据进行标签提取,获取文本数据的所有文本标签,将所有文本标签生成为文本标签集合。
24.示例性地,提取的文本标签和配置标签可以为小区和街道,具体的小区名称则是文本标签和配置标签的内容,例如小区:长泰御园,又或者街道:云林街道。
25.s5:对每个配置标签集合依次进行以下处理:依次选取配置标签集合中的一个配置标签,计算选取的配置标签与文本标签集合中与选取的配置标签所对应的文本标签的相似度。
26.s6:对每个配置标签集合依次进行以下处理:判断配置标签集合中的每个配置标签的相似度是否大于判定阈值,如果大于则将该相似度乘以配置权重得到该配置标签的得分值。
27.如果相似度小于判定阈值,则将该配置标签的得分值置零。
28.s7:将配置标签集合中的所有配置标签的得分相加得到配置标签集合的总得分值。
29.s8:将总得分最高的配置标签集合所对应的处理终端作为文本数据的数据处理终端。
30.本实施例中,对于步骤s7和步骤s8,在步骤s7中,当得到配置标签集合的总得分值时,将配置标签集合对应的处理规则打上总得分值,生成判断数据包,并将判断数据包存入总分集合中;步骤s8中,遍历总分集合中的判断数据包,在总分集合中查找总得分值最大的判断数据包,并将总得分值最大的判断数据包中的处理规则所对应的处理终端作为数据处理终端。
31.综上,本发明提前依据文本数据的类别生成对应的规则处理器,每个规则处理器中包括处理终端,当有文本数据输入时,先提前判断出与文本数据对应的子分类号,然后对子分类号进行过滤得到有用子分类号,接着依据有用子分类号分配对应的规则处理器,然后在所有规则处理器中确定有用规则处理器,然后分别计算有用规则处理器中的处理终端的处理规则的配置标签集合与文本数据的文本数标签集合的相似度,并基于相似度为每个处理终端生成一个总得分值,通过将总得分值最大的处理终端作为数据处理终端,从而可以替代人工进行文本数据的处理对象查找,提高了查找效率。另外通过不断训练生成不同的规则处理器可以提高不同文本数据的查找准确率。
32.上述依据本发明为启示,通过上述的说明内容,相关工作人员完全可以在不偏离本项发明技术思想的范围内,进行多样的变更以及修改。本项发明的技术性范围并不局限于说明书上的内容,必须要根据权利要求范围来确定其技术性范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1