视频对象分割模型训练方法、装置、电子设备及存储介质与流程
本公开涉及互联网,尤其涉及一种视频对象分割模型训练方法、装置、电子设备及存储介质。
背景技术:
1、视频目标分割(video object segmentation,vos)是视频场景理解和视频编辑的基础能力。该技术在短视频智能编辑、特效制作和短视频创作等领域具有广阔应用前景。vos技术是指给定某视频序列初始帧中的目标物体掩膜mask,在后续帧的预测出该目标物体的像素级别的分割掩膜mask结果。随着深度学习错的发展,深度神经网络被应用于vos中,从深度网络提取的高层语义特征能够从复杂场景中更准确辨别目标物体和背景,从而极大的提升了目标分割的效果。
2、然而,考虑的是在基于具有完善的视频物体分割标注训练数据集的情况下,视频物体分割数据集需要分别标注出一段视频中每个不同物体的像素级掩膜mask结果。然而,这种标注方式比单纯的图片标注更费时和费力,因为其不仅要标注出每张图片中不同物体的分割掩膜mask,还要对齐标识的标注,并在同一段视频中的后续帧中按照相同的标识对目标物体进行标注。因此视频物体分割的标注数据集所需的人力成本和时间成本很大。
技术实现思路
1、本公开提供一种视频对象分割模型训练方法、视频对象分割方法、装置、电子设备及存储介质,本公开的技术方案如下:
2、根据本公开实施例的第一方面,提供一种视频对象分割模型训练方法,包括:
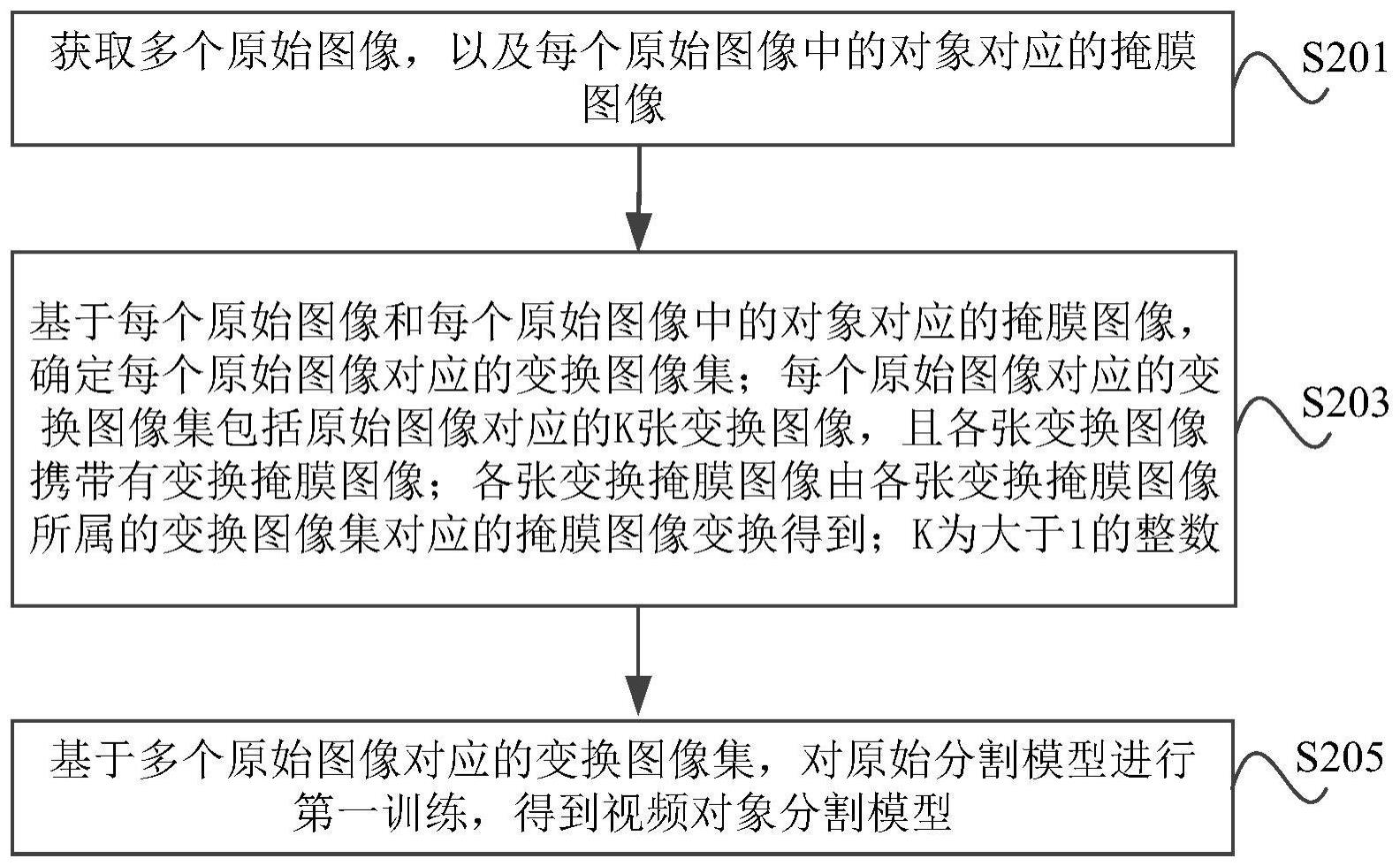
3、获取多个原始图像,以及每个原始图像中的对象对应的掩膜图像;
4、基于每个原始图像和每个原始图像中的对象对应的掩膜图像,确定每个原始图像对应的变换图像集;每个原始图像对应的变换图像集包括原始图像对应的k张变换图像,且各张变换图像携带有变换掩膜图像;各张变换掩膜图像由各张变换掩膜图像所属的变换图像集对应的掩膜图像变换得到;k为大于1的整数;
5、基于多个原始图像对应的变换图像集,对原始分割模型进行第一训练,得到视频对象分割模型。
6、在一些可能的实施例中,基于每个原始图像和每个原始图像中的对象对应的掩膜图像,确定每个原始图像对应的变换图像集,包括:
7、从每个原始图像中的对象对应的掩膜图像中确定目标对象对应的目标掩膜图像;每个原始图像中的对象包括目标对象;
8、对每个原始图像进行预设变换,得到每个原始图像对应的k张变换图像;
9、对目标对象对应的目标掩膜图像进行预设变换,得到目标掩膜图像对应的k张变换掩膜图像;
10、基于每个原始图像对应的,k张变换图像和k张变换掩膜图像确定每个原始图像对应的变换图像集。
11、在一些可能的实施例中,预设变换包括:
12、通过模拟帧间运行信息进行的预设变换;
13、或者通过模拟扭曲变形信息进行的预设变换;
14、或者通过数据增强进行的预设变换。
15、在一些可能的实施例中,获取每个原始图像中的对象对应的掩膜图像,包括:
16、对每个原始图像中的预设对象进行识别,确定预设对象对应的掩膜图像。
17、在一些可能的实施例中,获取每个原始图像中的对象对应的掩膜图像,包括:
18、对每个原始图像中的每个对象进行识别,确定每个原始图像中的每个对象的像素;
19、基于每个对象的像素对原始图像进行二值化处理,得到每个原始图像对应的掩膜图像;
20、对每个原始图像对应的掩膜图像进行连通区域分割处理,得到每个原始图像中的每个对象对应的掩膜图像。
21、在一些可能的实施例中,基于多个原始图像对应的变换图像集,对原始分割模型进行第一训练,得到视频对象分割模型,包括:
22、将变换图像集中的k张变换图像组成对象合成视频;
23、将对象合成视频中的多张变换图像确定为多个第一图像帧;
24、将多个第一图像帧对应的变换掩膜图像确定为多个第一掩膜;
25、将对象合成视频中的一张变换图像确定为第二图像帧;第二图像帧在对象合成视频中的位置位于多个第一图像帧之后;
26、将多个第一图像帧和多个第一掩膜输入原始分割模型中的第一编码器,得到第一特征信息;
27、将第二图像帧输入原始分割模型中的第二编码器,得到第二特征信息;
28、基于原始分割模型中的解码器、第一特征信息和第二特征信息确定第二图像帧对应的预测掩膜;
29、基于第二图像帧对应的预测掩膜和变换图像集中,第二图像帧对应的变换掩膜图像对原始分割模型进行训练,得到视频对象分割模型。
30、在一些可能的实施例中,得到视频对象分割模型之后,还包括:
31、获取训练视频;训练视频通过设备拍摄获取;
32、对训练视频中的多个目标视频帧进行对象掩膜处理,得到多个目标视频帧对应的多个对象掩膜;目标视频帧为训练视频中包含有目标对象的视频帧;
33、基于多个目标视频帧和多个对象掩膜对视频对象分割模型进行第二训练,得到更新后的视频对象分割模型。
34、根据本公开实施例的第二方面,提供一种视频对象分割方法,包括:
35、获取待识别视频;
36、对待识别视频中,包含有预设对象的q个视频帧进行对象掩膜处理,得到q个视频帧对应的q个对象掩膜;q为大于1的正整数;
37、将待识别视频和q个对象掩膜输入根据权利要求1至7任一视频对象分割模型训练方法训练得到的视频对象分割模型,得到待识别视频中,包含有预设对象的剩余视频帧对应的对象掩膜。
38、根据本公开实施例的第三方面,提供一种视频对象分割模型训练装置,包括:
39、图像获取模块,被配置为执行获取多个原始图像,以及每个原始图像中的对象对应的掩膜图像;
40、图像集获取模块,被配置为执行基于每个原始图像和每个原始图像中的对象对应的掩膜图像,确定每个原始图像对应的变换图像集;每个原始图像对应的变换图像集包括原始图像对应的k张变换图像,且各张变换图像携带有变换掩膜图像;各张变换掩膜图像由各张变换掩膜图像所属的变换图像集对应的掩膜图像变换得到;k为大于1的整数;
41、训练模块,被配置为执行基于多个原始图像对应的变换图像集,对原始分割模型进行第一训练,得到视频对象分割模型。
42、在一些可能的实施例中,图像集获取模块,被配置为执行:
43、从每个原始图像中的对象对应的掩膜图像中确定目标对象对应的目标掩膜图像;每个原始图像中的对象包括目标对象;
44、对每个原始图像进行预设变换,得到每个原始图像对应的k张变换图像;
45、对目标对象对应的目标掩膜图像进行预设变换,得到目标掩膜图像对应的k张变换掩膜图像;
46、基于每个原始图像对应的,k张变换图像和k张变换掩膜图像确定每个原始图像对应的变换图像集。
47、在一些可能的实施例中,预设变换包括:
48、通过模拟帧间运行信息进行的预设变换;
49、或者通过模拟扭曲变形信息进行的预设变换;
50、或者通过数据增强进行的预设变换。
51、在一些可能的实施例中,图像获取模块,被配置为执行:
52、对每个原始图像中的预设对象进行识别,确定预设对象对应的掩膜图像。
53、在一些可能的实施例中,图像获取模块,被配置为执行:
54、对每个原始图像中的每个对象进行识别,确定每个原始图像中的每个对象的像素;
55、基于每个对象的像素对原始图像进行二值化处理,得到每个原始图像对应的掩膜图像;
56、对每个原始图像对应的掩膜图像进行连通区域分割处理,得到每个原始图像中的每个对象对应的掩膜图像。
57、在一些可能的实施例中,训练模块,被配置为执行:
58、将变换图像集中的k张变换图像组成对象合成视频;
59、将对象合成视频中的多张变换图像确定为多个第一图像帧;
60、将多个第一图像帧对应的变换掩膜图像确定为多个第一掩膜;
61、将对象合成视频中的一张变换图像确定为第二图像帧;第二图像帧在对象合成视频中的位置位于多个第一图像帧之后;
62、将多个第一图像帧和多个第一掩膜输入原始分割模型中的第一编码器,得到第一特征信息;
63、将第二图像帧输入原始分割模型中的第二编码器,得到第二特征信息;
64、基于原始分割模型中的解码器、第一特征信息和第二特征信息确定第二图像帧对应的预测掩膜;
65、基于第二图像帧对应的预测掩膜和变换图像集中,第二图像帧对应的变换掩膜图像对原始分割模型进行训练,得到视频对象分割模型。
66、在一些可能的实施例中,训练模块,被配置为执行:
67、获取训练视频;训练视频通过设备拍摄获取;
68、对训练视频中的多个目标视频帧进行对象掩膜处理,得到多个目标视频帧对应的多个对象掩膜;目标视频帧为训练视频中包含有目标对象的视频帧;
69、基于多个目标视频帧和多个对象掩膜对视频对象分割模型进行第二训练,得到更新后的视频对象分割模型。
70、根据本公开实施例的第四方面,提供一种视频对象分割装置,包括:
71、视频获取模块,被配置为执行获取待识别视频;
72、对象掩膜确定模块,被配置为执行对待识别视频中,包含有预设对象的q个视频帧进行对象掩膜处理,得到q个视频帧对应的q个对象掩膜;q为大于1的正整数;
73、分割模块,被配置为执行将待识别视频和q个对象掩膜输入根据权利要求1至7任一视频对象分割模型训练方法训练得到的视频对象分割模型,得到待识别视频中,包含有预设对象的剩余视频帧对应的对象掩膜。
74、根据本公开实施例的第五方面,提供一种电子设备,包括:处理器;用于存储处理器可执行指令的存储器;其中,处理器被配置为执行指令,以实现如上述第一方面或者第二方面中任一项的方法。
75、根据本公开实施例的第六方面,提供一种计算机可读存储介质,当计算机可读存储介质中的指令由电子设备的处理器执行时,使得电子设备能够执行本公开实施例的第一方面或者第二方面中任一项的方法。
76、根据本公开实施例的第七方面,提供一种计算机程序产品,计算机程序产品包括计算机程序,计算机程序存储在可读存储介质中,计算机设备的至少一个处理器从可读存储介质读取并执行计算机程序,使得计算机设备执行本公开实施例的第一方面或者第二方面中任一项的方法。
77、本公开的实施例提供的技术方案至少带来以下有益效果:
78、获取多个原始图像,以及每个原始图像中的对象对应的掩膜图像;基于每个原始图像和每个原始图像中的对象对应的掩膜图像,确定每个原始图像对应的变换图像集;每个原始图像对应的变换图像集包括原始图像对应的k张变换图像,且各张变换图像携带有变换掩膜图像;各张变换掩膜图像由各张变换掩膜图像所属的变换图像集对应的掩膜图像变换得到;k为大于1的整数;基于多个原始图像对应的变换图像集,对原始分割模型进行第一训练,得到视频对象分割模型。本技术通过包含有变换图像和变换掩膜图像的变换图像集对原始分割模型进行训练,无需标签数据,从而减少了训练成本。
79、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
- 还没有人留言评论。精彩留言会获得点赞!