金融特征数据的筛选方法、装置、电子设备及存储介质与流程
本发明涉及计算机,具体而言,涉及金融特征数据的筛选方法、装置、电子设备及存储介质。
背景技术:
1、在银行信用贷款的信用评分场景下,从众多与信用评分相关的特征中,筛选出用于对信用进行评分的特征,对用户进行信用评分起着至关重要的作用。通过筛选后续输入信用评分模型的特征从而提高信用评分模型的准确率和效率,并使得信用评分模型具有更好的泛化能力。尤其是在特征数量较大时,不同特征的选择将决定最后信用评分模型的整体效果。
2、目前,一般通过精通信用评分的专家对特征进行人工筛选,但是人工筛选效率较低,且由于受到人工不确定因素影响,不易探索更大的特征组合空间。
技术实现思路
1、有鉴于此,本技术的目的在于提供一种金融特征数据的筛选方法、装置、电子设备及存储介质,能够从用户数据的多个特征中筛选出金融特征数据,提高了金融特征数据的筛选效率。
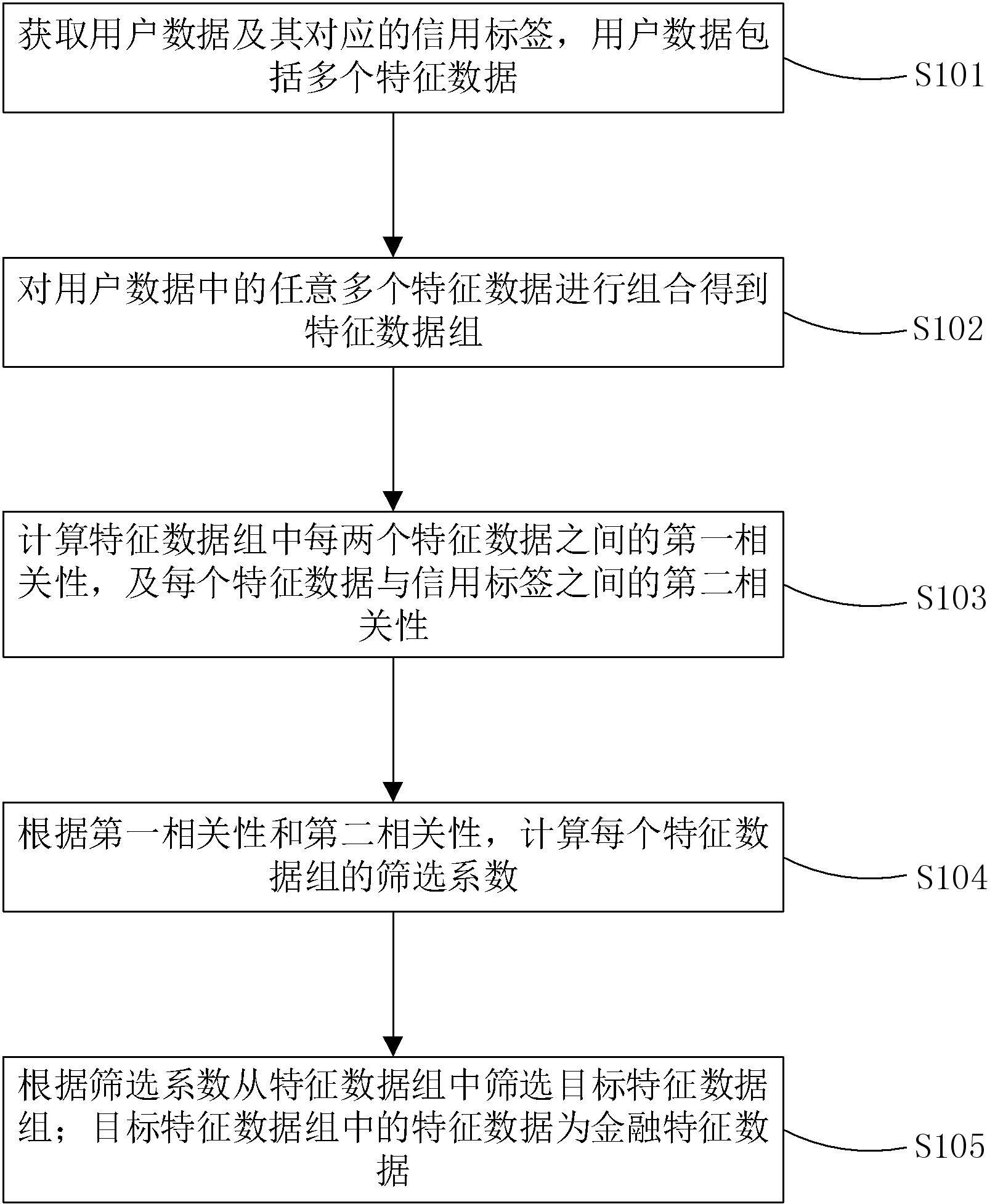
2、第一方面,本技术实施例提供了一种金融特征数据的筛选方法,该金融特征数据的筛选方法包括:
3、获取用户数据及其对应的信用标签,用户数据包括多个特征数据;
4、对用户数据中的任意多个特征数据进行组合得到特征数据组;
5、计算特征数据组中每两个特征数据之间的第一相关性,及每个特征数据与信用标签之间的第二相关性;
6、根据第一相关性和第二相关性,计算每个特征数据组的筛选系数;
7、根据筛选系数从特征数据组中筛选目标特征数据组;目标特征数据组中的特征数据为金融特征数据。
8、在一种可能的实施方式中,计算特征数据组中每两个特征数据之间的第一相关性,及每个特征数据与信用标签之间的第二相关性,包括:
9、将所有第一相关性进行累加,得到第一相关性的和值;
10、将所有第二相关性进行累加,得到第二相关性的和值;
11、根据第一相关性的和值和第二相关性的和值,计算至少一个预置惩罚系数对应的每个特征数据组的筛选系数。
12、在一种可能的实施方式中,根据筛选系数从特征数据组中筛选目标特征数据组,包括:
13、将同一预置惩罚系数对应的所有特征数据组中筛选系数最小的特征数据组确定为初始特征数据组;
14、若初始特征数据组的数量等于1,则将初始特征数据组确定为目标特征数据组;
15、若初始特征数据组的数量大于1,则根据信用标签从初始特征数据组中筛选目标特征数据组。
16、在一种可能的实施方式中,根据信用标签从初始特征数据组中筛选目标特征数据组,包括:
17、将初始特征数据组中的特征数据输入分类器中,得到初始特征数据组的信用结果;
18、计算信用结果与信用标签一致的概率值;
19、将概率值最大的初始特征数据组确定为目标特征数据组。
20、在一种可能的实施方式中,计算每个特征数据组的筛选系数,包括:
21、将预置惩罚系数、第一相关性的和值、以及第二相关性的和值,代入下述特征筛选表达式中计算特征数据组的筛选系数;
22、;
23、其中,f(x)为特征数据组的筛选系数,α为预置惩罚系数,r1为特征数据组的第一相关性的和值,r2为特征数据组的第二相关性的和值。
24、在一种可能的实施方式中,计算第一相关性的和值,包括:
25、将特征数据组代入下述第一相关性公式中,计算第一相关性的和值;
26、;
27、其中,为特征数据组的第一相关性的和值,n为特征数据组中特征数据的数量,为第j个特征数据的选取标志,为第k个特征数据的选取标志,为第j个特征与第k个特征之间的皮尔森相关系数,为第j个特征与第k个特征之间的第一相关性。
28、在一种可能的实施方式中,计算第二相关性的和值,包括:
29、将特征数据组、信用标签代入下述第二相关性公式中,计算第二相关性的和值;
30、;
31、其中,为特征数据组的第二相关性的和值,n为特征数据组中特征数据的数量,为第j个特征数据的预置权重,为第j个特征数据的选取标志,为第j个特征与信用标签之间的信息量,为第j个特征与信用标签之间的第二相关性。
32、第二方面,本技术实施例还提供了一种金融特征数据的筛选装置,所述金融特征数据的筛选装置包括:
33、获取模块,用于获取用户数据及其对应的信用标签,用户数据包括多个特征数据;
34、组合模块,用于对用户数据中的任意多个特征数据进行组合得到特征数据组;
35、计算模块,用于计算特征数据组中每两个特征数据之间的第一相关性,及每个特征数据与信用标签之间的第二相关性;
36、计算模块,还用于根据第一相关性和第二相关性,计算每个特征数据组的筛选系数;
37、筛选模块,用于根据筛选系数从特征数据组中筛选目标特征数据组;目标特征数据组中的特征数据为金融特征数据。
38、在一种可能的实施方式中,计算模块,具体用于将所有第一相关性进行累加,得到第一相关性的和值;将所有第二相关性进行累加,得到第二相关性的和值;根据第一相关性的和值和第二相关性的和值,计算至少一个预置惩罚系数对应的每个特征数据组的筛选系数。
39、在一种可能的实施方式中,筛选模块,具体用于将同一预置惩罚系数对应的所有特征数据组中筛选系数最小的特征数据组确定为初始特征数据组;若初始特征数据组的数量等于1,则将初始特征数据组确定为目标特征数据组;若初始特征数据组的数量大于1,则根据信用标签从初始特征数据组中筛选目标特征数据组。
40、在一种可能的实施方式中,筛选模块,还用于将初始特征数据组中的特征数据输入分类器中,得到初始特征数据组的信用结果;计算信用结果与信用标签一致的概率值;将概率值最大的初始特征数据组确定为目标特征数据组。
41、在一种可能的实施方式中,计算模块,具体用于将预置惩罚系数、第一相关性的和值、以及第二相关性的和值,代入下述特征筛选表达式中计算特征数据组的筛选系数;;其中,f(x)为特征数据组的筛选系数,α为预置惩罚系数,r1为特征数据组的第一相关性的和值,r2为特征数据组的第二相关性的和值。
42、在一种可能的实施方式中,计算模块,具体用于将特征数据组代入下述第一相关性公式中,计算第一相关性的和值;;其中,为特征数据组的第一相关性的和值,n为特征数据组中特征数据的数量,为第j个特征数据的选取标志,为第k个特征数据的选取标志,为第j个特征与第k个特征之间的皮尔森相关系数,为第j个特征与第k个特征之间的第一相关性。
43、在一种可能的实施方式中,计算模块,具体用于将特征数据组、信用标签代入下述第二相关性公式中,计算第二相关性的和值;;其中,为特征数据组的第二相关性的和值,n为特征数据组中特征数据的数量,为第j个特征数据的预置权重,为第j个特征数据的选取标志,为第j个特征与信用标签之间的信息量,为第j个特征与信用标签之间的第二相关性。
44、第三方面,本技术实施例还提供了一种电子设备,包括:处理器、存储介质和总线,存储介质存储有处理器可执行的机器可读指令,当电子设备运行时,处理器与存储介质之间通过总线通信,处理器执行机器可读指令,以执行如第一方面任一项金融特征数据的筛选方法的步骤。
45、第四方面,本技术实施例还提供了一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,计算机程序被处理器运行时执行如第一方面任一项金融特征数据的筛选方法的步骤。
46、本技术实施例提供了一种金融特征数据的筛选方法、装置、电子设备及存储介质,该金融特征数据的筛选方法包括:获取用户数据及其对应的信用标签,用户数据包括多个特征数据;对用户数据中的任意多个特征数据进行组合得到特征数据组;计算特征数据组中每两个特征数据之间的第一相关性,及每个特征数据与信用标签之间的第二相关性;根据第一相关性和第二相关性,计算每个特征数据组的筛选系数;根据筛选系数从特征数据组中筛选目标特征数据组;目标特征数据组中的特征数据为金融特征数据。本技术通过每两个特征数据之间的第一相关性、特征数据与信用标签之间的第二相关性,计算每个特征数据组的筛选系数,然后根据筛选系数从特征数据组中确定金融特征数据,能够从用户数据的多个特征中筛选出金融特征数据,提高了金融特征数据的筛选效率。
- 还没有人留言评论。精彩留言会获得点赞!