一种用于手语翻译的新型词级对比学习框架及手语翻译系统
本发明涉及计算机视觉、自然语言处理和手语语言学领域,尤其是涉及一种用于手语翻译的新型词级对比学习框架及手语翻译系统。
背景技术:
1、手语是听力障碍者社区日常交流中使用的视觉语言。手语翻译(sign languagetranslation,slt)在缩小听力障碍者和正常人之间的交流差距方面可以发挥重要作用。因此,slt受到研究界越来越多的关注,slt将手语视频作为输入,并生成一个自然口语句子。目前最流行的slt数据集仅包含不到9k的平行手语视频、手语词汇和口语句子。手语数据集的收集和注释是非常困难和昂贵的。因此,slt任务本质上是一个低资源的问题。
2、目前,对比学习已经成为计算机视觉和自然语言处理界非常流行的技术,其性能非常稳定。最近的工作也证明对比性学习在低资源场景下有巨大的潜力。
技术实现思路
1、本发明的第一目的在于突破在低资源条件下手语的翻译瓶颈,利用对比学习优势,缓解手语翻译的低资源状况,同时提升手语翻译性能,提供一种用于手语翻译的新型词级对比学习框架conslt(contrastive framework for sign language translation)。
2、本发明的第二目的在于提供在低资源情况下也可以学习到很好手语表示的一种基于对比学习的手语翻译方法。
3、本发明的第三目的在于提供更精准、更流畅的一种基于对比学习的手语翻译系统。
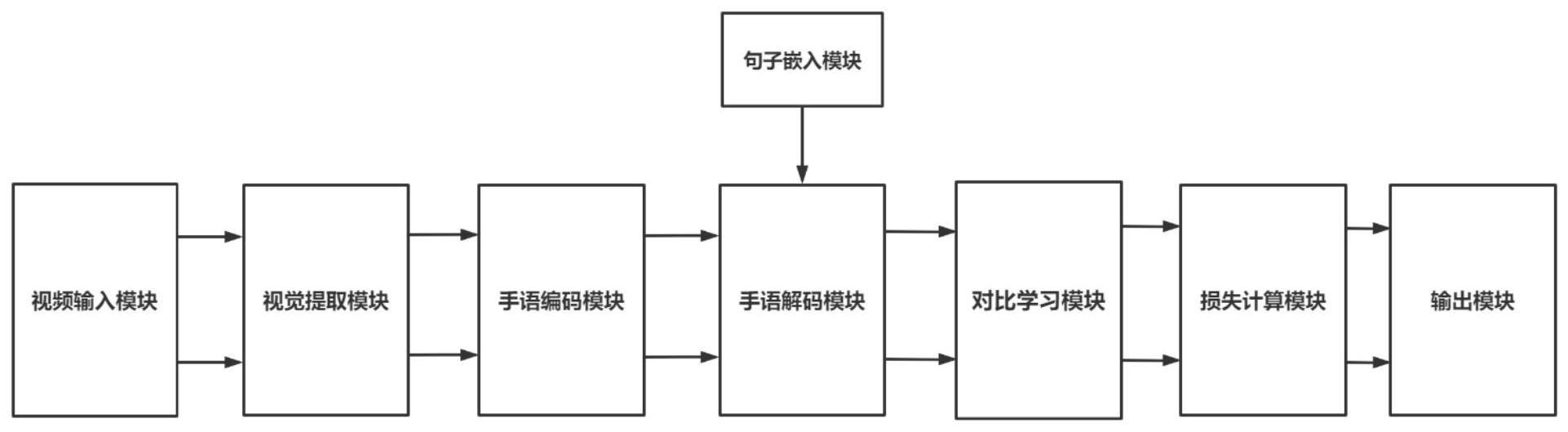
4、所述用于手语翻译的新型词级对比学习框架(简称conslt框架),包括视频输入模块、视觉提取模块、手语编码模块、句子嵌入模块、手语解码模块、对比学习模块、损失计算模块、输出模块;
5、所述视频输入模块用于进行手语翻译数据选取建模,将手语视频以视频帧的形式输入到模型中;
6、所述视觉提取模块用于将手语视频每一帧使用卷积神经网络对手语视频进行特征提取,得到包含手语视觉信息的序列特征;
7、所述手语编码模块用于将接收到的视觉特征向量通过编码器-解码器得到隐藏表示;手语编码模块中带有注意力机制;
8、所述句子嵌入模块用于将输入的手语视频对应口语句子,作为训练阶段的答案;
9、所述手语解码模块用于在接受到手语编码模块的输出的向量后,通过编码模块的特征向量生成翻译结果;手语解码模块中带有一个掩码注意力机制;
10、所述对比学习模块用于在训练阶段构建正例对及负例对;
11、所述损失计算模块用于使用ctc(connectionist temporal classification)损失函数计算手语编码模块中对齐手语词注的对齐损失,使用交叉熵损失函数计算手语解码模块中生成单词的翻译损失,并且使用kl散度计算将手语视频输出两次得到的解码模块输出的对比损失;
12、所述输出模块用于输出手语视频经过手语翻译模型得到的口语句子。
13、本发明提供一种基于对比学习的手语翻译方法,包括以下步骤:
14、1)手语语料选取建模;
15、2)手语视觉特征提取;
16、3)端到端手语视频转换;
17、4)训练阶段句子嵌入;
18、5)构建正例对及负例对;
19、6)手语翻译模型损失计算;
20、7)手语翻译结果输出。
21、在步骤1)中,所述手语语料选取建模是在视频输入模块对手语语料进行选取建模,将手语语料中的手语视频以视频帧的形式输入到模型中;
22、所述手语语料包含手语视频、手语词注、口语句子三元组,该三元组记为d={(x,z,y)}∈(x,z,y);其中,x,z,y分别表示手语视频、手语词注、口语句子;
23、具体的,表示t帧的手语视频,是对应的手语词注序列,是对应的口语句子;手语词注序列是一个逐字的手语转录,由于手语词注和口语语法的显著区别,手语词注序列的词序与口语句子不同;tz和ty分别是手语词注序列和口语句子的长度。
24、在步骤2)中,所述手语视觉特征提取是在视觉提取模块将手语视频每一帧使用卷积神经网络对手语视频进行特征提取,得到包含手语视觉信息的序列特征。
25、在步骤3中,所述端到端手语视频转换是将提取到的视觉特征向量送至手语编码模块,通过编码器解码器得到隐藏表示;在接受到手语编码模块的输出的向量后,手语解码模块通过编码模块的特征向量去生成翻译结果;
26、具体的,手语语料中的手语视频建模后采用基于transformer的编码器-解码器结构进行视频到文本的转换;
27、手语编码模块用于学习有意义的时空表示和手语表示,通过对齐手语视频中手语词注,将视觉信息编码到文本空间中,为手语翻译任务提供帮助;使用ctc损失对齐手语视频中的手语词注;手语编码模块输出含有手语语义信息的特征向量;手语编码模块中带有注意力机制,注意力机制摆脱输入序列长度的限制,是一种使模型对重要信息重点关注并充分学习吸收的技术;
28、手语视频的帧级表示由一个预先训练好的手语嵌入网络提取;通过位置编码(positional encoding,pe)方法为编码器的输入embedding添加位置信息到帧级表示;输入的input送入transformer编码器模块,生成手语视频的隐藏表示;这些操作表述为:
29、fi=signembedding(xi), (1)
30、
31、
32、其中,i∈[1,tx]表示视频的第i帧,signembedding表示预先训练好的手语嵌入网络,pe表示编码器的输入embedding添加位置信息到帧级表示,encoder表示编码器;
33、在接受到手语编码模块的输出的向量后,有一个begin的标识符,识别到begin后,手语解码模块通过编码模块的特征向量生成翻译结果;解码阶段的每个步骤都从输出序列中输出一个单词;每个步骤的输出在下一个时间步骤中被输入到底部解码器,使其解码结果向上输出给更高一层;在这些解码器输入中嵌入并添加位置编码以指示每个单词的位置,重复此过程,直到到达出现标识符end,表示解码模块已经完成输出。
34、手语解码模块有一个掩码注意力机制,主要是因为解码是一个顺序操作的过程,在第k个时间步预测单词时,只能看到前k-1个预测结果,因此要对后续部分内容进行掩码操作;同时在解码器的注意力机制中,k,v来自编码器的输出,而q则来自解码器的上一个输出;
35、这些操作表述为:
36、wt=wordembedding(yt), (4)
37、
38、
39、ot=softmax(wht+b). (7)
40、其中,p(y|x}的条件概率和目标函数计算如下:
41、
42、
43、在步骤4)中,所述训练阶段句子嵌入的具体步骤可为:在训练阶段,句子嵌入模块输入手语视频x对应口语句子y,作为训练阶段的答案;将口语句子y转为句子嵌入,将文本中的文字表示转为向量表示,为了在高位空间中捕捉词汇间的关系,使用一个线性层将文字表示投影到高维空间中。
44、在步骤5)中,所述构建正例对及负例对的具体步骤可为:
45、采用不同的dropout采样,将一个符号视频x送入模型两次;由于dropout机制在transformer中随机丢弃部分单元,可以为每个词yt获得两个不同的隐藏表征,表示为ht和为每个词yt构建正数对
46、对于解码步骤中的每个词,conslt框架将其和由dropout生成的增强版本作为正例对;conslt不使用所有其他批次的句子或词作为负面例子,而是随机抽取词汇表中不在当前句子中的k个词作为负面例子来挖掘不同的负面例子;给定一个句子y,将句子y中的所有词集表示为s;从一个候选词集(词汇表v中不在当前句子s中的所有词)中随机抽取k个词,为每个词yt构建一个负面样本子集将y-通过一个负例embedding查找表为每个词构建负例对
47、在步骤6)中,所述手语翻译模型损失计算的具体步骤可为:在损失计算模块,使用ctc损失函数计算手语编码模块中对齐手语词注的对齐损失,使用交叉熵损失函数计算手语解码模块中生成单词的翻译损失,使用kl散度计算将手语视频输出两次得到的解码模块输出的对比损失。
48、在步骤7)中,所述手语翻译结果输出是通过输出模块输出经过手语翻译模型得到的口语句子。
49、本发明还提供一种基于对比学习的手语翻译系统,包括视频输入单元、句子输入单元、视频特征提取模块、手语编码模块、手语解码模块、对比学习模块、存储单元、损失计算模块、文本输出单元;
50、所述视频输入单元用于进行手语翻译数据选取建模,将手语视频以视频帧的形式输入到系统中;
51、所述句子输入单元用于输入已有数据集,包含手语视频对应口语句子,作为训练阶段的答案;
52、所述视频特征提取模块用于将手语视频每一帧使用卷积神经网络对手语视频进行特征提取,得到包含手语视觉信息的序列特征;
53、所述手语编码模块用于将提取到的视觉特征向量送至手语编码模块,通过编码器-解码器得到隐藏表示;
54、所述手语解码模块用于在接受到手语编码模块的输出的向量后,手语解码模块通过编码模块的特征向量去生成翻译结果;
55、所述对比学习模块用于在训练阶段,通过对比学习模块构建模型所需正例对及负例对;
56、所述存储单元用于存储手语翻译数据;
57、所述损失计算模块用于使用ctc损失函数计算手语编码模块中对齐手语词注的对齐损失,使用交叉熵损失函数计算手语解码模块中生成单词的翻译损失,并且使用kl散度计算将手语视频输出两次得到的解码模块输出的对比损失;
58、所述文本输出单元用于输出手语视频经过手语翻译模型得到的口语句子输出。
59、本发明的优点在于:
60、1)本发明首次从自然语言处理的角度探索手语翻译的对比学习。对比学习直接利用数据本身作为监督信息,数据本身提供的信息比标签信息更丰富,从而可以学习到更丰富的手语数据的特征表示。
61、2)本发明为手语翻译提出一种新的词级对比学习方法,词级对比学习方法是一种自监督学习,从表示学习的角度为缓解手语翻译训练数据不足的低资源问题提供了一种新的见解。通过词级对比学习,在低资源情况下也可以学习到很好的手语表示,使手语翻译系统翻译得更精准,更流畅。
62、3)本发明所提的conslt框架表现性能一直优于基线,并且该框架不受模型限制,可以适用于不同的模型。该方法广泛适应于各种手语相关的自然语言处理和视觉任务中,具有较好的应用前景和应用价值。
- 还没有人留言评论。精彩留言会获得点赞!