基于外部知识和主题信息的服装文本摘要生成方法
本发明属于服装信息化方法,具体涉及基于外部知识和主题信息的服装文本摘要生成方法。
背景技术:
1、随着互联网的发展,人们在享受数字信息便利的同时也不得不面对其所带来的数据爆炸问题。如何使用计算机技术对文本内容进行抽取,使人们可以快速准确地获取文本的主题和主要内容的研究就变得至关重要,文本摘要模型的研究成为学术界的热点研究方向。
2、同时,随着新一代人工智能的发展,服装纺织等传统工业急需依靠智能化转型提高产业的竞争力。如何帮助用户快速了解服装产品的款式、用料、产地等信息,提高用户的购买欲望已经成为互联网时代服装产业迫切需要处理的难题。在服装领域文本摘要的相关技术中,如何有效利用知识图谱的外部知识去指导文本摘要生成的研究由于缺少相关的服装领域知识图谱而进展缓慢。因此,如何构建特定的服装领域知识图谱,并利用其做为外部知识对服装文本摘要生成进行指导,提高服装文本摘要的生成效果成为一种有效的解决思路。
技术实现思路
1、本发明的目的是提供基于外部知识和主题信息的服装文本摘要生成方法,能够有效提高服装文本摘要的生成效果。
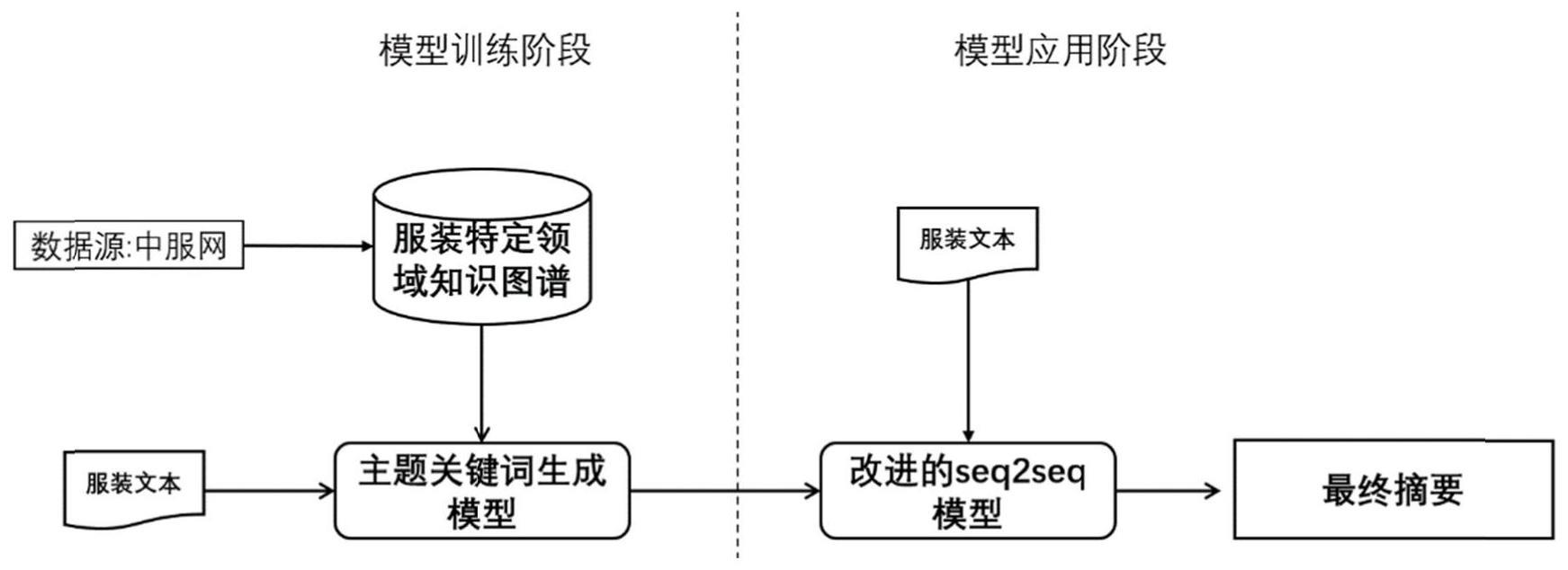
2、本发明所采用的技术方案是,基于外部知识和主题信息的服装文本摘要生成方法,具体按照以下步骤实施:
3、步骤1,构建服装特定领域知识图谱;
4、步骤2,利用步骤1中的知识图谱与预训练模型结合改进lda模型生成服装文本主题关键词;
5、步骤3,构建由treelstm与transformer相结合的改进seq2seq模型,并在其中引入步骤2中获取的主题关键词,最后训练该模型并保存得到文本摘要生成模型,输入服装文本获得摘要即成。
6、本发明的特点还在于,步骤1具体按照以下步骤实施:
7、步骤1.1,原始数据收集及处理
8、从中服网获取有关服装材料,厂商的介绍文章,清洗后得到的数据作为构建知识图谱的原始数据,利用正则表达式对原始数据进行清洗处理,删去空格,统一文本格式,删去不正确与多余的文本数据,将处理完成后的服装文本数据作为源数据集;
9、步骤1.2,服装领域知识图谱构建
10、将服装知识图谱定义为ckg=(v,e),其中v代表构建的服装知识图谱中所有的节点集合,e代表各个服装实体之间的关系集合;
11、步骤1.3,服装知识图谱的持久化与展示
12、使用neo4j数据库作为具体的持久化平台,读取步骤1.2所获取的excel文件,读取三元组数据,使用create与match命令将构建所有三元组数据插入neo4j数据库,完成服装知识图谱ckg的持久化与展示,最终获取服装领域知识图谱。
13、步骤1.2具体按照以下步骤实施:
14、步骤1.2.1,服装关系类型定义
15、服装知识图谱ckg=(v,e)中的e代表各个服装实体之间的关系集合,其具体为e={vi,rk,vj},其中vi,rk∈v,代表服装实体,rk∈r,rk代表实体vi,rk之间的关系,r代表所有实体关系的集合;
16、步骤1.2.2,服装实体抽取
17、以步骤1.1中获取的数据为源数据进行服装实体抽取;
18、步骤1.2.3,服装关系对应
19、将步骤1.2.2中抽取的服装实体按公司名称进行分类标识,在每个公司分类下,将公司名称与其包含的其余服装实体按照实体字典d定义的含义与步骤1.2.1定义的关系集合r对应,组装成三元组数据结构,将最终获取的三元组数据集合按行写入excel文件存储。
20、步骤2具体按照以下步骤实施:
21、步骤2.1,数据预处理
22、利用正则表达式将步骤1.2中获取的文本数据预处理分为多个句集合s={s1,s2,s3,···,sn},其中sn代表第n个句子,然后利用预训练模型simbert获取所有句子的句向量特征
23、步骤2.2,主题句划分
24、基于对步骤2.1处理后的句向量特征计算每个句子之间的余弦相似度,公式如下:
25、
26、其中si,sj代表第i,j个句子,得到所有句子之间的余弦相似度后以此为依据,利用谱聚类算法对句集合进行聚类,将主题相似的句子划分为多个聚类簇集合c={c1,c2,···,cn},其中cn={s1,s2,···,si};
27、步骤2.3,文本内容知识化
28、将服装文本进行主题句划分后,并为其引入外部知识;
29、步骤2.4,服装文本主题词识别
30、将初始的候选词空间由源文档自身包含的词汇内容扩展至服装文本所包含的所有外部知识,改进的lda模型中,每个聚类簇ci都有自己的主题分布,该主题分布为多项式分布,记参数α使该主题分布符合狄利克雷分布,每个主题下都包含其对应的词分布,记参数β使该词分布符合狄利克雷分布。
31、步骤2.3具体按照以下步骤实施:
32、步骤2.3.1,分词处理
33、利用jieba分词器对步骤2.2获取到文本的句聚类集c中包含的每个聚类簇进行分词处理,生成对应的词集w={w1,w2,···,wm},其中每个wm中都包含本聚类簇下所有的分词结果;
34、步骤2.3.2,知识链接
35、以步骤2.2获取的聚类簇集合c中的每个聚类簇为基本单位,将步骤2.3.1获取的文本分词与步骤1建立的服装知识库进行链接,获取每个聚类簇下所有分词的相关背景知识,记为知识集合k,具体为k={k1,k2,···,kn},其中kn代表当前句聚类下所有的相关知识,记为kn={w1,w2,···,wt},其中wt代表每个分词的关联外部知识,其存储形式为wt={i1,i2,···,ii},其中ii代表根据分词从外部知识库获取的第i个知识;
36、步骤2.3.3,同义词消歧
37、将步骤2.3.2获取到的知识k输入词林进行筛选,删去部分频繁出现且词义类似的词。
38、步骤2.4中对于每个句聚类簇ci主题词的识别过程具体为:
39、步骤2.4.1,设定当前句聚类簇ci的先验分布为p(ci);
40、步骤2.4.2,利用符合狄利克雷分布的参数α,对聚类簇ci所属的知识集ki进行吉布斯采样,获取其可能的主题分布θi;
41、步骤2.4.3,从主题分布θi中使用吉布斯采样获取聚类簇ci的第j个词的主题zi,j;
42、步骤2.4.4,利用符合狄利克雷分布的参数β,对聚类簇ci所属的知识集ki通过吉布斯采样获取其每个主题zi,j对应的词分布
43、步骤2.4.5,从词分布中根据当前聚类簇ci所包含的句子数m选取前m个主题词ti,j。
44、步骤3具体为:
45、步骤3.1,首先为treelstm与transformer构造输入序列,对源文本进行数据预处理,对transformer编码器,输入序列的处理方式是先进行分词,将源文本的句子切分成单词,切分后的输入序列s表示为s={x1,x2,···,xn},n代表切分后的单词总数,treelstm编码器则使用语义依存分析为其构造树形输入数据,获得输入序列,将结果记为xj,j代表源文本中的单词数;
46、步骤3.2,构建一个改进的seq2seq序列模型,包括编码层、注意力层、解码层、指针网络层,由transformer与treelstm作为编码层,由lstm层构成解码层,注意力层负责特征融合,指针网络用于优化最终输出;
47、步骤3.3,将步骤2中所得到的服装文本关键词与知识特征通过bert预训练模型抽取特征,记为知识主题特征tv;
48、步骤3.4,使用注意力机制,将主题特征tv与语义特征sv,全文特征hv进行融合,生成全文本的语义主题特征stv和全文主题特征htv;
49、步骤3.5,构建门控机制融合与指针网络融合取舍已有的语义主题特征stv与全文主题特征向量htv,其中门控与指针网络的计算公式如下所示:
50、g=sigmod(w5stv+w6hlstm+w7din+bg) (2)
51、pgen=sigmod(w9hlstm+w10htv+bpgen) (3)
52、其中w5,w6,w7,bg,w9,w10,bpgen为训练参数;hlstm为解码器隐层状态,din为解码器输入,g∈[0,1],用于控制语义主题特征stv与全文主题特征htv融合,pgen的范围是[0,1],当pgen=1时,使用预测的词作为输出,当pgen=0时,选择从源文本进行拷贝;
53、步骤3.6,利用集束搜索扩展最终摘要生成的候选词空间,设置搜索宽度q=5;
54、步骤3.7,训练该模型并存储;
55、步骤3.8,输入服装文本进入模型,得到服装文本摘要。
56、步骤3.2中编码器与解码器具体为:
57、步骤3.2.1,使用transformer抽取源文本的时序位置特征,记为文本全文特征hv;
58、步骤3.2.2,使用treelstm抽取文本语义特征,treelstm首先会按照句法依存树的形式读取输入序列,然后使用输出门oj,遗忘门fjk,输入门ij控制信息的传递,其中,uj控制当前输入与当前结点的子节点输出状态信息的融合,然后通过输入门ij获得当前结点状态,最后将所有的隐层状态连接记录得到文本的语义特征表示记为文本语义特征sv,具体公式如下:
59、
60、
61、
62、cj=ij⊙uj+∑k∈c(j)fjk⊙ck (7)
63、其中,hk代表单元子节点的隐藏状态,w和u为参数矩阵,表示hk与输入xj之间的相关性,oj,fjk和ij分别代表treelstm的输出门,遗忘门和输入门,cj代表treelstm当前节点的存储单元;训练过程中,模型学习参数矩阵,使得语义重要的单词输入时,输入门值接近1;当输入是相对不重要的单词时,输入门的值接近0,即可控制对文本重要语义信息的获取;
64、步骤3.2.3,使用lstm用作生成摘要的解码器,将transformer与treelstm获得到的隐层状态进行拼接融合,记为din,作为单向lstm解码器的输入,将单向lstm获取到的的隐层特征状态记录为hlstm。
65、步骤3.4具体为:
66、步骤3.4.1,利用软注意力机制获取文本的全文主题特征htv,如下式:
67、
68、a=softmax(s(hv,tv)) (9)
69、htv=∑ahv (10)
70、上式中,w1,w2为训练参数;s(hv,tv)代表由多层感知机计算出的hv与tv的相似度;之后使用softmax()函数对其归一化得到权重a,与transformer编码器获取的全文特征hv相乘,得到最终的全文主题特征向量htv;
71、步骤3.4.2,通过软注意力机制可以获取到文本的语义主题特征stv,具体过程如下式所示:
72、
73、a=softmax(s(sv,tv)) (12)
74、stv=∑asv (13)
75、上式中,w3,w4为训练参数,s(sv,tv)代表由多层感知机计算出的sv与tv的相似度;之后使用softmax()函数对其归一化得到权重a,与语义主题特征sv相乘得到文本的语义主题特征stv。
76、本发明的有益效果是,通过自主构建的服装领域下专有知识图谱,并利用其做为外部知识指导服装领域文本主题关键词与文本摘要的生成,有效提高了摘要的生成效果。该服装领域下专有知识图谱可有效解决传统文本主题关键词生成过程中缺少外部知识引导、中文分词歧义较大的问题,从而提高了服装文本主题关键词的获取效率。文本摘要生成模型通过结合transformer提取的文本时序特征与treelstm提取的文本语义特征,提高了文本特征的提取效率。且通过使用注意力机制将外部知识与文本的主题关键词融合入服装文本摘要的生成中,有效地解决了当前服装文本摘要生成过程中存在的语义编码信息获取不完全,语义不通畅及生成摘要缺少文本关键信息等问题。该技术应用于服装信息化处理过程中可有效促进服装产业智能化、互联网化的进展。
- 还没有人留言评论。精彩留言会获得点赞!