一种基于异步众核向量处理器的芯片架构的制作方法
本发明涉及半导体芯片设计,具体涉及一种面向嵌入式应用的低功耗众核芯片架构。
背景技术:
1、很多面向嵌入式应用的芯片,有着非常大的计算量需求,例如,人工智能(ai)边缘处理芯片、无线通信基带芯片、机器人/自动驾驶芯片,等等。目前来说,这些嵌入式应用,大量采用现场可编程门阵列(fpga)实现计算。但是,fpga的开发较困难,对研发人员的水平要求较高,编程慢、编译慢,给研发带来不便。
2、近年来,有很多的片上系统(soc)芯片,在处理器(包括cpu和dsp)的总线上,挂一些专用加速器。这样的soc芯片,解决了部分嵌入式应用的计算需求。但是,由于加速器往往针对某种特定的应用或算法而设计,这限制了芯片的灵活性,不利于新产品/新技术的研发。
3、与fpga相似,嵌入式众核向量处理器具有高并行度、高计算能力的特点,具有广泛的应用场景。然而,嵌入式众核向量处理器是一种新型的计算平台,其结构中有很多的技术难点需要解决。这些技术难点包括:
4、1)众核向量处理器中各处理器核心间的片上互连方法;
5、2)低功耗控制方法;由于核心数目多,又是面向嵌入式应用,低功耗设计成为一项关键需求;
6、3)芯片的高计算能力;fpga主要应用于高并行度、高计算量的实时应用场景,同样,采用本架构的芯片,亦需要非常高的计算能力,因此,提高芯片的计算能力,成为采用本架构芯片的一项关键技术;
7、4)广泛的应用场景;正如fpga是一种通用计算平台,本芯片也应是一种通用计算平台,可广泛应用于通信、雷达、图像处理、人工智能等众多嵌入式场合。因此,芯片的计算能力,应具有广泛的普适性。
技术实现思路
1、有鉴于此,本发明提出一种基于异步众核向量处理器的芯片架构。本发明既能适应一些嵌入式应用方面高计算量的需求,又能适应嵌入式系统低功耗的要求。
2、本发明采用的技术方案为:
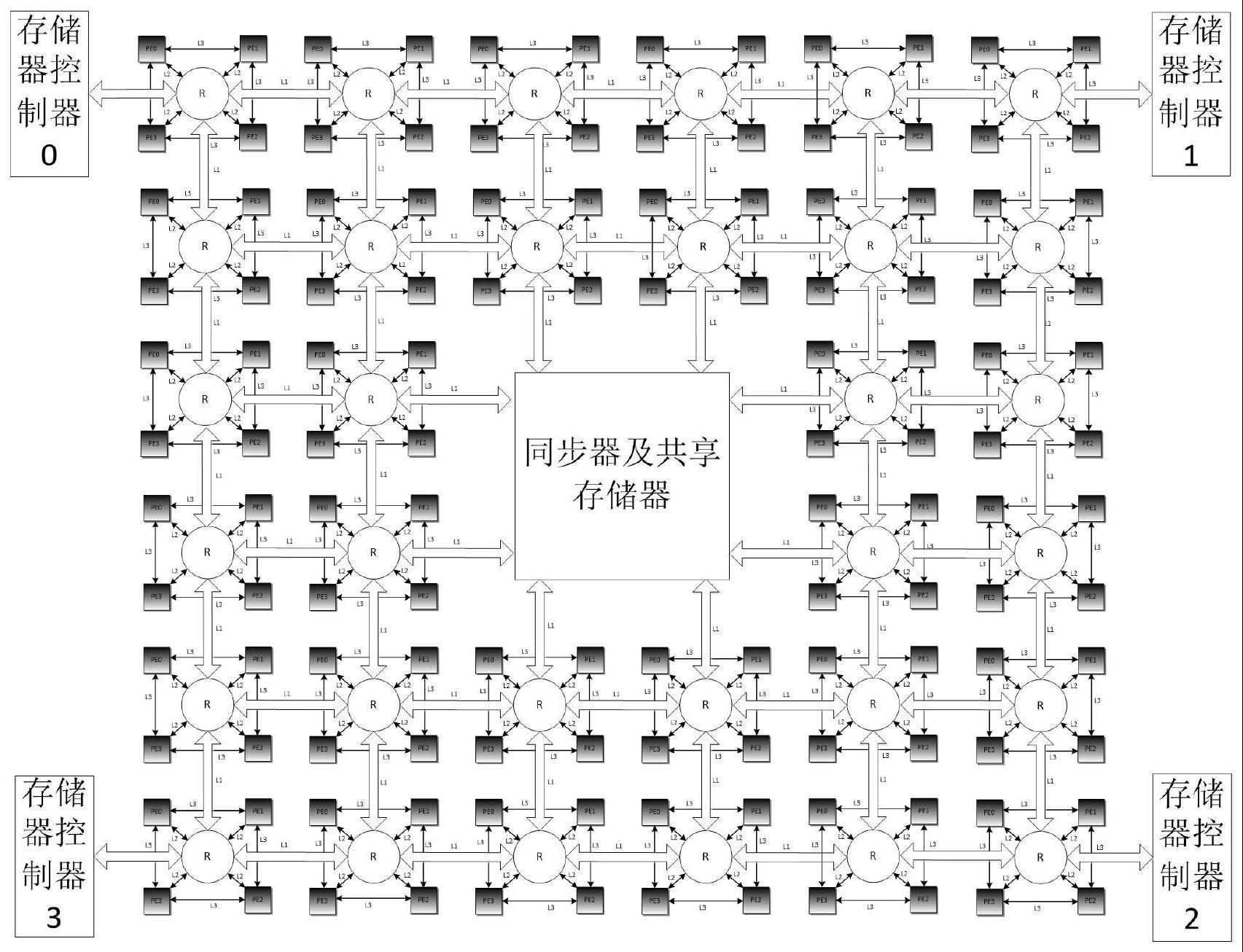
3、一种基于异步众核向量处理器的芯片架构,采用片上网络实现众核处理单元的互连;所述片上网络包括配置网络、数据网络、片上网络路由器和片上网络互连线,其中,配置网络用于配置数据网络和各处理单元的时钟和电源的开关及调整,数据网络用于处理单元间通信,片上网络路由器与处理单元间采用异步先入先出缓冲器进行异步时钟隔离。
4、进一步地,所述处理单元包括一个标量处理器、一个向量运算单元、一个交叉开关、一个直接存储器访问控制器、一个片上网络接口电路和多个sram存储器,处理单元内不设高速缓存;向量运算单元具有多个并行的存储器读写接口,向量运算单元挂在标量处理器的扩展指令接口上;标量处理器、向量运算单元和直接存储器访问控制器通过交叉开关访问任意一块sram存储器;标量处理器及直接存储器访问控制器均通过片上网络接口电路实现与片上网络之间的数据交换。
5、进一步地,处理单元内的sram存储器被分为两组;第一组sram存储器上的交叉开关,标量处理器的访问优先权高于向量运算单元和直接存储器访问控制器的访问优先权;第二组sram存储器上的交叉开关,向量运算单元和直接存储器访问控制器的访问优先权高于标量处理器的访问优先权;第一组sram存储器的地址在先,第二组sram存储器的地址紧接在第一组sram存储器地址的后面,第一组sram存储器的地址和第二组sram存储器的地址均按块交织。
6、进一步地,所述片上网络为网格结构或三维网格结构。
7、进一步地,采用片上网络实现众核处理单元的互连,具体方式为:每4个处理单元一起形成一个正交单元,多个正交单元按照二维网格阵列形式排布在平面上,通过片上网络相连;每个正交单元中设有一个片上网络路由器,片上网络路由器之间通过第一链路相连;在正交单元内部,片上网络路由器与处理单元之间通过第二链路相连,处理单元之间通过第三链路相连。
8、进一步地,所述片上网络路由器具有8个输入接口和8个输出接口,分别对应4个处理单元和东西南北4个方向的输出接口和输入接口,每个输入接口及输出接口均为异步先入先出缓冲器,以实现异步时钟隔离;在输入方向,每个输入先入先出缓冲器内的数据包,输出后首先经过路由选择,然后发送到合适的输出端口;在输出方向,多个路由选择模块送来的数据包,经仲裁及多路选择后,送入输出先入先出缓冲器;输出先入先出缓冲器的输出的数据包,又送给本地处理单元或下一级路由器。
9、进一步地,芯片中还设置有同步器,同步器连接在片上网络上,与同步器位置相邻的地方还设置有片上共享存储器;在芯片的4个角上,各设有一个ddr存储器控制器。
10、进一步地,所述同步器包括栅格同步器、旋转锁、互斥信号量;
11、互斥信号量为一组寄存器,每个寄存器均充当一个信号量使用,当某资源被某处理单元使用时,设置该资源对应的信号量寄存器为1,从而避免其它处理单元使用;当该资源被释放时,清除该寄存器,以提供给其它处理单元使用;各信号量和各处理单元之间没有固定的映射关系;
12、旋转锁的使用方式为:当某资源被某处理单元使用时,又有其他处理单元请求该资源,则旋转锁依次缓存所有其他处理单元的编号信息;该资源被释放时,旋转锁自动通知缓存中第一顺位的处理单元使用该资源;各旋转锁与各处理单元之间没有固定的映射关系;
13、栅格同步器由一组栅格同步器单元构成,每个栅格同步单元都由一个标志寄存器、一个掩码寄存器、一个同步达成运算逻辑和一个通知分发电路构成,每个标志寄存器和掩码寄存器的位宽都与处理单元的个数相同,每个处理单元在标志寄存器里占据一位、在掩码寄存器里占据一位;在同步设置阶段,将需要参与同步的处理单元所对应的掩码寄存器位设置为1,将不需要参与同步的处理单元所对应位置的掩码寄存器位设置为0;在工作之前,标志寄存器里的所有位都清零;开始工作后,每个处理单元运行到同步点后,将它对应的标志寄存器位设置为1;同步达成运算逻辑对掩码寄存器的每个比特取反,并与标志寄存器按位进行或运算,然后将所有位或运算的结果,进行与运算,若运算结果为1,则表示所有参与同步的处理单元都已到达同步点,此时通知分发电路开始工作;通知分发电路按照掩码寄存器的内容,给掩码寄存器位为1的处理单元发送同步达成通知;待所有同步达成通知分发完成后,标志寄存器清零,等待下一次同步过程。
14、本发明的有益效果在于:
15、1、本发明的众核芯片架构具有高并行度、高计算能力。这主要是因为处理单元(pe)的数目多,且每个pe为向量处理器,具有较高的计算能力。
16、2、低功耗。这主要是因为每个pe的时钟和电源独立,可独立关断不工作pe的时钟和电源。
17、3、编程简单、编译快。每个pe可采用c语言编程,整个芯片亦可采用c语言编程,这比采用硬件描述语言的fpga的编程要简单很多、编译要快很多。
18、4、适用范围广。这主要是因为本发明的基本部件为向量处理器,向量计算是计算数学的最基本运算,因此,芯片能适应非常广泛的计算任务,芯片的灵活性也得以保障。
- 还没有人留言评论。精彩留言会获得点赞!