基于类人视觉感知和语言记忆网络的视觉对话生成方法与流程
本发明属于计算机视觉,具体地说是一种基于类人视觉感知和语言记忆网络的视觉对话生成方案。
背景技术:
1、视觉对话旨在探索一个智能体使它能够像人类一样恰当的回应一系列问题用自然语言依赖对话历史和所给图像的理解。大多数视觉语言任务更加关注实体级或者区域级的视觉特征。相比而言,视觉对话更具挑战性因为它需要智能体足够充分的理解图像而不仅限于实体级和区域级,以此来应对对话内容的多样性和复杂性。因此,它需要智能体能够多视角的全面理解图像和理解深层次对话历史中的语义交互细节。如何像人类一样能够从多个视角理解图像并且掌握复杂语言内容的细节信息成为了一个最重要的挑战在视觉对话中。视觉对话目前在计算机视觉领域是一个热门的研究课题之一,其应用场景非常广泛,包括:人工智能聊天机器人,以及帮助视障人员快速掌握所处的场景信息;
2、随着近几年深度学习的发展,视觉对话技术也得到了巨大的发展,但是仍然存在以下挑战和问题:
3、一、现有的方法对于图像信息的处理较少,图像理解不够充分。
4、例如,jiang 2020在视觉对话任务中引入了外部知识即图像的场景图用来刻画object-relation视觉特征,从视觉和语义两个视觉共同描绘图像。chen 2021认为在图像中能够准确地定位问题相关视觉object是重要,因此他提出去理解视觉对象在视觉对话历史中通过最小化视觉对象的先验分布和后验分布之间的距离。chen 2021提出一个关系意识的图卷积网络来抽取图像中实体间的空间关系为了提升智能体对图像的理解。尽管上述方法已经逐渐的加强对视觉上下文特征的探索,但是它们主要来自于object-local特征,仍然忽略了能够体现整张图像的视觉环境的全局视觉上下文信息。
5、二、缺乏细粒度的文本上下文语义特征的学习。
6、例如,gan 2019引入一个迭代推理的理念并提出了一个recurrent dualattention network,在每轮对话中都更新问题的语义表示这使模型能够细粒度的理解多模态的上下文。schwartz2019尝试构建了一个基于对话中问答对的图结构然后利用一个通用的注意力机制模型捕获对话内容的细节和细微差别信息从而帮助模型预测答案。kang2019提出了两个注意力模块refer和find去解决模糊不清的指代在问题中。虽然上述工作已经关注了文本内容的学习,但仍于粗粒度的学习阶段,忽视了细粒度语言信息的重要性。
技术实现思路
1、本发明是为了解决目前现有技术上的不足之处所提出的。具体地,本发明提出了一种基于类人视觉感知和语言记忆网络的视觉对话生成方案,以期能为智能体提供全面的视觉特征理解信息,以及更加细粒度的文本语言记忆信息,从而提高智能体对于图像和文本的理解以预测视觉对话智能体答案的生成的恰当性和准确性。
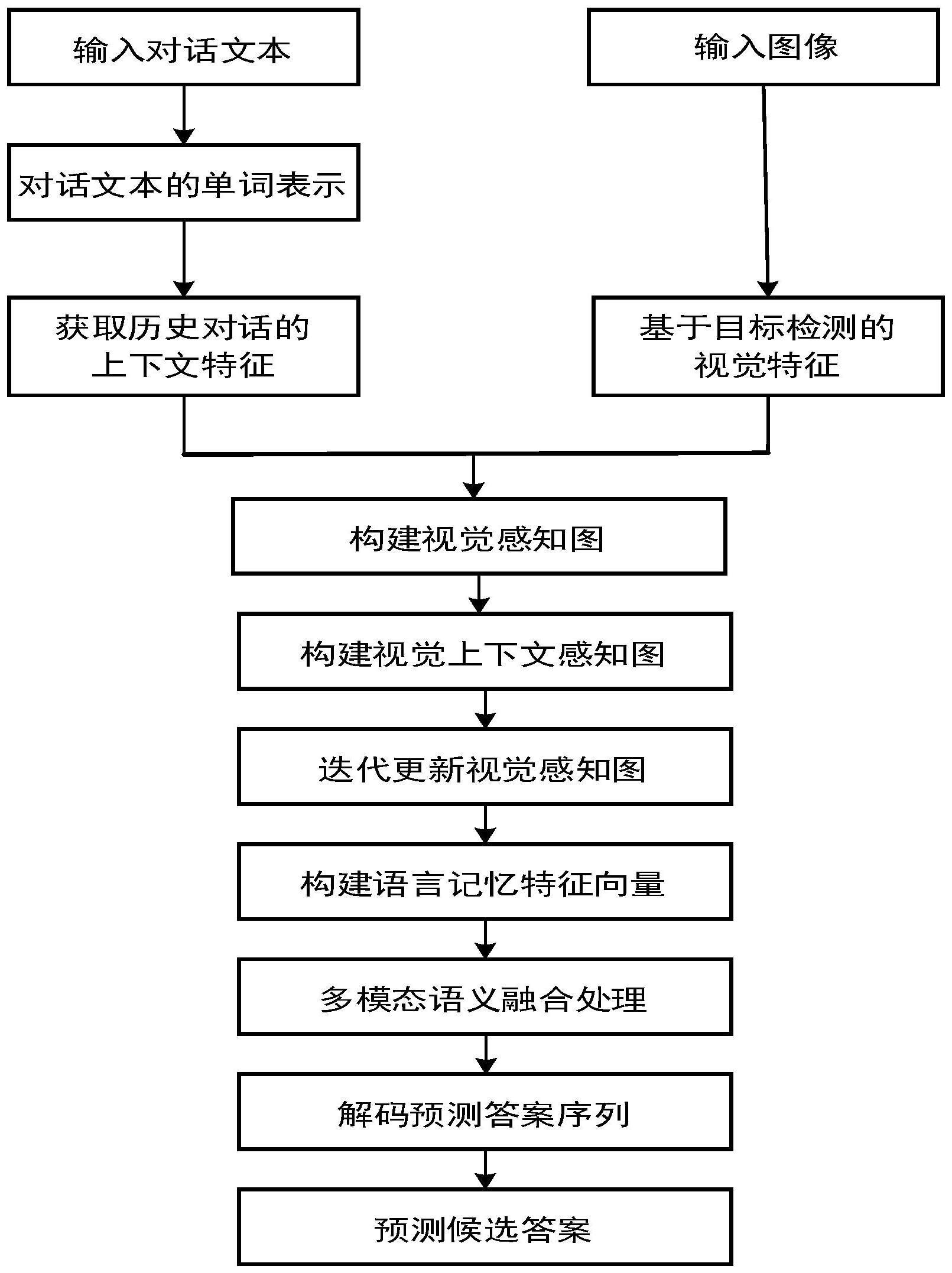
2、为了实现上述目的,本发明采用的技术方案为一种基于类人视觉感知和语言记忆网络的视觉对话生成方法,包括以下步骤,
3、步骤1、视觉对话中文本输入的预处理和单词表的构建;
4、步骤2、视觉对话的图像特征表示以及对话文本的特征表示;
5、步骤3、构建视觉上下文感知图;
6、步骤4、迭代更新视觉上下文感知图获取类人的全局和局部视觉特征向量;
7、步骤5、获取在当前问题指导下的历史对话上下文语言记忆特征向量;
8、步骤6、多模态语义融合处理;
9、步骤7、解码预测答案特征序列;
10、步骤8、基于类人视觉感知和语言记忆网络的视觉对话生成网络模型的参数优化;
11、步骤9、预测候选答案,包括对损失函数随着模型训练学习最小化损失,当损失最小时,取对应损失最小时的答案序列作为模型所预测的候选答案序列。
12、而且,步骤1的实现方式包括以下子步骤,步骤1.1、获取视觉对话数据集,所述视觉对话数据集包含了句子文本和图像;对视觉对话数据集中所有包含的句子文本进行分词处理,得到经分割后的句子序列;
13、步骤1.2、从分割后的句子序列中得到所有单词,并从中筛选词频率大于设定阈值的所有单词,并构建数据集中所有单词对应的单词索引表记为voc;再对索引表voc中的每一个单词进行one-hot编码,得到one-hot向量表;
14、步骤1.3、随机初始化一个词嵌入矩阵we,通过使用词嵌入矩阵we将每个单词的one-hot向量映射到相应的词向量上,从而得到每个单词的向量表示。
15、而且,步骤2的实现方式包括以下子步骤,
16、步骤2.1、从视觉对话数据集中获取任意一张图像i,使用目标检测特征提取器得到图像i的视觉特征;
17、步骤2.2、从视觉对话数据集中获取任意一张图像所对应的对话历史文本记为u,当前问题q以及真实的答案标签记为agt;
18、步骤2.3、使用双向长短时记忆网络对步骤2.2中的对话历史文本u中的第r轮对话ur进行语义编码得到隐藏层状态序列表示为采用最后一个隐藏状态特征向量hr,l作为第r轮对话ur的句子级特征表示hr,得到总的对话历史u所对应的句子级特征hu;
19、步骤2.4、使用双向长短时记忆网络对步骤2.2中的当前问题q进行语义编码提取当前问题的上下文特征向量记为,取bi-lstm的最后一个隐藏层状态特征hq,l作为当前问题的句子级特征向量hq。
20、而且,步骤3的实现方式为,利用步骤2.1中图像i的视觉特征v和当前问题的句子级特征向量hq作为构建视觉上下文感知图的输入,在图构建的过程中,将图像i的视觉特征v与hq进行注意力对齐,得到含有当前问题信息的图像特征,将构建图节点的特征表示和节点间的边权重表示分别为v*和
21、而且,步骤4的实现方式为,将步骤3中建立的视觉上文感知图利用多层图卷积神经网络进行更新获取类人的图像的全局和局部视觉特征向量。
22、而且,步骤5的实现方式为,利用步骤2.3中获得的第r轮的对话历史特征向量hr与当前问题特征向量hq来构建上语言记忆特征向量表示;首先,将第0轮到第r轮的对话历史特征向量进行拼接获得总的对话历史特征然后将与hq进行特征融合操作,获得话题特征向量表示最后将所有轮的对话历史进行迭代更新学习获得最终的语言记忆特征tm。
23、而且,步骤6的实现方式为,利用步骤2.1中获得的当前问题的句子级特征向量hq,步骤4中获得的视觉上下文特征向量和步骤5中获得的语言记忆特征向量tm,进行视觉和文本间的不同模态的特征融合处理以获得最终的高级的融合后的视觉语言特征向量s*。
24、而且,步骤7的实现方式为将候选答案a*利用bi-lstm如同问题编码一样,取最后一个隐藏状态向量作为a*中每个答案的句子级特征表示;设pt包含了100个候选答案各自的概率值,随后取pt中概率最大的值和次序作为最终预测的答案值。
25、而且,步骤8的实现方式为,利用步骤7中计算的预测答案pt与真实答案agt之间的损失代价函数f:
26、
27、式中,yt,i表示第t轮问题对应的第i候选答案的真实答案标签的one-hot编码向量表示,pt,i表示第t轮问题对应的第i候选答案的概率值。
28、另一方面,本发明提供一种基于类人视觉感知和语言记忆网络的视觉对话生成系统,用于实现如上所述的一种基于类人视觉感知和语言记忆网络的视觉对话生成方法。
29、与已有技术相比,本发明的有益效果体现在:
30、1、本发明从两个视角来编码图像信息即全局视角和局部视角,它不仅捕获了实体级的视觉特征,还捕获了图像级的视觉特征,以此来丰富图像信息表示。
31、2、本发明针对语言理解设计了一个迭代学习策略。这个学习策略将整个对话历史按轮分解,然后随着对话的进行以迭代的方式捕获每轮对话历史与问题间的语义交互信息。以这种方式,使得模型能够捕获文本的细微细节信息增强模型对语言内容的记忆和理解。
32、3、本发明在通过对视觉和文本语义的深层学习和特征提取过程中,加强了模型的学习能力,对于智能体预测答案效果获得了很大的提升,预测结果也更加精准。
33、本发明方案实施简单方便,实用性强,解决了相关技术存在的实用性低及实际应用不便的问题,能够提高用户体验,具有重要的市场价值。
- 还没有人留言评论。精彩留言会获得点赞!