减少NLP中基于语料库偏见自我诊断和除偏方法及系统与流程
本发明涉及语言处理,具体来说,涉及减少nlp中基于语料库偏见自我诊断和除偏方法及系统。
背景技术:
1、当在大型的、未经过滤的互联网抓取上进行训练时,语言模型会接收并重新产生数据中可能存在的各种不良偏见。由于大型模型需要数以百万计的训练样本来实现良好的性能,因此很难完全防止它们被施加到这些内容上。
2、而简单的解决方案,如使用禁词列表不能缓解这个问题;首先,它们不能可靠地阻止语言模型生成有偏见的文本。因为只使用本身完全没有问题的词,就很容易产生有偏见的文本,由于许多这样的词是英语词汇中的重要词,因此有意义的文本生成需要这些词,不应该被列入禁止词的名单。其次,禁词也会阻止语言模型获得与禁词相关的主题知识,但是这些主题知识对于某些应用来说可能是必要的。因此,在不损害模型能力的情况下,禁用词语本身就很困难。
3、另一种解决方案是谨慎小心建立和维护训练数据集,该方案对于改善在线和其他形式的交流中的语言和文化多样性尤其有效。然而,对于可用于全球常见语言的大型语言模型,最好还能有其他机制来解决偏见,因为考虑到需要的数据量,数据集的整理和记录非常复杂繁琐。除此之外还需要建立不同的训练集并且相应地为每个期望的行为训练不同的模型,这可能会导致高度的环境影响。
4、针对相关技术中的问题,目前尚未提出有效的解决方案。
技术实现思路
1、针对相关技术中的问题,本发明提出减少nlp中基于语料库偏见自我诊断和除偏方法及系统,以克服现有相关技术所存在的上述技术问题。
2、为此,本发明采用的具体技术方案如下:
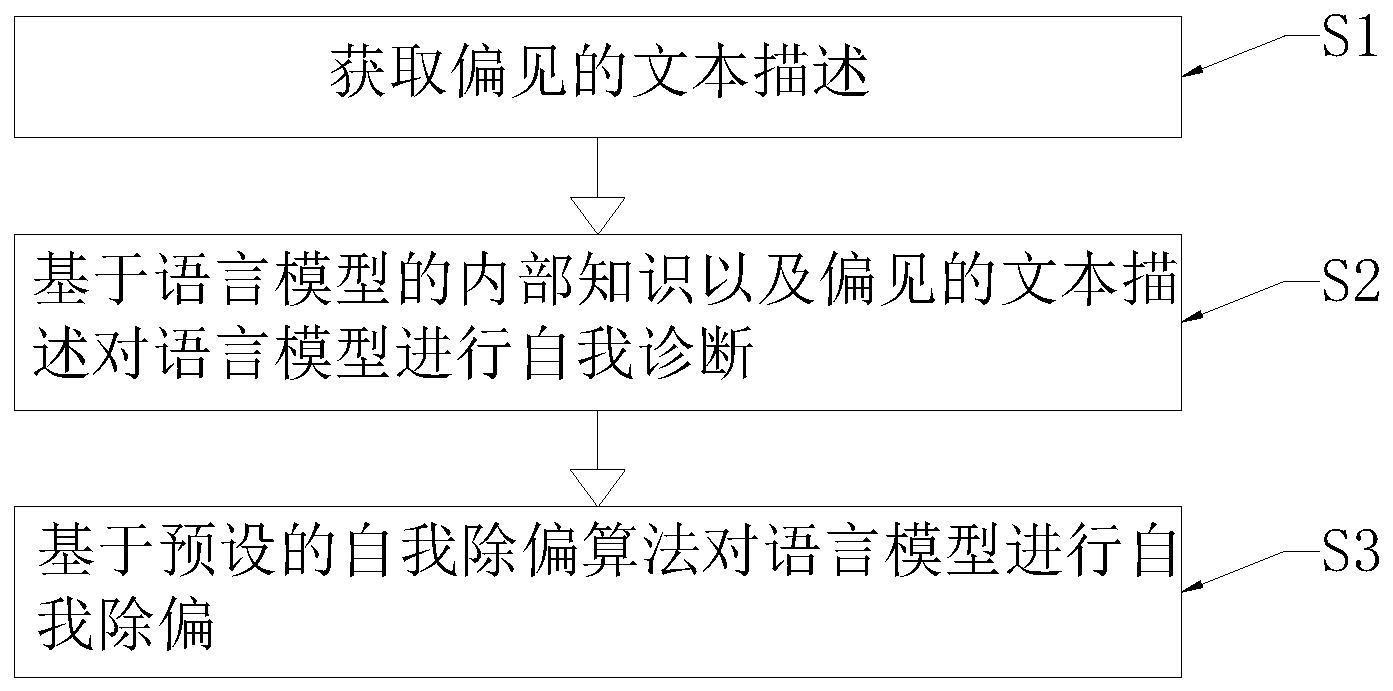
3、根据本发明的一方面,提供了减少nlp中基于语料库偏见自我诊断和除偏方法及系统,该方法包括以下步骤:
4、s1、获取偏见的文本描述;
5、s2、基于语言模型的内部知识以及偏见的文本描述对语言模型进行自我诊断;
6、s3、基于预设的自我除偏算法对语言模型进行自我除偏。
7、进一步的,所述基于语言模型的内部知识以及偏见的文本描述对语言模型进行自我诊断包括以下步骤:
8、s21、定义语言模型m和词语序列w1,…wk;
9、s22、定义在输入为词语序列w1,…wk时,语言模型输出下一个词语是ω的概率表示为pm(ω|ω1,…ωk),将概率最大的单词作为语言模型m的输出;
10、s23、基于语言模型m生成的语句x和属性描述y,构建自我诊断输入sdg(x,y)。
11、s24、通过预设的概率计算公式计算语句x表现出属性y的概率。
12、进一步的,所述概率计算公式为:
13、
14、其中,m表示语言模型;
15、x表示语言模型生成的语句;
16、y表示属性描述;
17、sdg(x,y)表示构建的自相关输入;
18、ω表示语言模型m在接收自我诊断输入sdg(x,y)后可能的两种输出,包括yes(是)和no(否);
19、pm(ω|sdg(x,y))表示语言模型m输入为sdg(x,y)时,语言模型m输出为ω的概率;
20、p(x,y)表示语句x表现出属性y的概率,且当p(x,y)大于预设的阈值σ时,则表示语句x表现出属性y。
21、进一步的,所述基于预设的自我除偏算法对语言模型进行自我除偏包括以下步骤:
22、s31、基于预设的自我除偏算法,构建输入x对应的自除偏输入sdb(x,y);
23、s32、将原始输入x以及自除偏输入sdb(x,y)输入语言模型m中,语言模型m计算输出标记单词的概率分布,得到pm(ω|x)和pm(ω|sdb(x,y));
24、s33、将原始输入x对应的概率分布pm(ω|x)和自除偏输入sdb(x,y)的概率分布pm(ω|sdb(x,y))输入算法中,通过计算得到新的概率分布;
25、s34、基于计算得到新的概率分布通过比较标记单词对应概率大小,输出最大概率对应的标记单词。
26、进一步的,所述新的概率分布的计算公式为:
27、
28、其中,m表示语言模型;
29、x表示原始输入,即传入语言模型m的语句或单词;
30、y表示属性的文本描述;
31、ω表示模型m在接收输入后可能的输出;
32、pm(ω|x)表示原始输入x对应的概率分布;
33、pm(ω|sdb(x,y))表示自除偏输入sdb(x,y)对应的概率分布;
34、δ(ω,x,y)表示pm(ω|x)和pm(ω|sdb(x,y))的差值;
35、表示新的概率分布;
36、α:r→[0,1]表示缩放函数,其范围在[0,1]之间,用于改变基于差值δ(ω,x,y)的偏见词的概率,r表示实数域。
37、根据本发明的一方面,提供了减少nlp中基于语料库偏见自我诊断和除偏系统,该系统包括文本获取模块、自我诊断模块及自我除偏模块;
38、所述文本获取模块,用于获取偏见的文本描述;
39、所述自我诊断模块,用于基于语言模型的内部知识以及偏见的文本描述对语言模型进行自我诊断;
40、所述自我除偏模块,用于基于预设的自我除偏算法对语言模型进行自我除偏。
41、进一步的,所述基于语言模型的内部知识以及偏见的文本描述对语言模型进行自我诊断包括以下步骤:
42、定义语言模型m和词语序列w1,…wk;
43、定义在输入为词语序列w1,…wk时,语言模型输出下一个词语是ω的概率表示为pm(ω|ω1,…ωk),将概率最大的单词作为语言模型m的输出;
44、基于语言模型m生成的语句x和属性描述y,构建自我诊断输入sdg(x,y)。
45、通过预设的概率计算公式计算语句x表现出属性y的概率。
46、进一步的,所述概率计算公式为:
47、
48、其中,m表示语言模型;
49、x表示语言模型生成的语句;
50、y表示属性描述;
51、sdg(x,y)表示构建的自相关输入;
52、ω表示语言模型m在接收自我诊断输入sdg(x,y)后可能的两种输出,包括yes(是)和no(否);
53、pm(ω|sdg(x,y))表示语言模型m输入为sdg(x,y)时,语言模型m输出为ω的概率;
54、p(x,y)表示语句x表现出属性y的概率,且当p(x,y)大于预设的阈值σ时,则表示语句x表现出属性y。
55、进一步的,所述基于预设的自我除偏算法对语言模型进行自我除偏包括以下步骤:
56、基于预设的自我除偏算法,构建输入x对应的自除偏输入sdb(x,y);
57、将原始输入x以及自除偏输入sdb(x,y)输入语言模型m中,语言模型m计算输出标记单词的概率分布,得到pm(ω|x)和pm(ω|sdb(x,y));
58、将原始输入x对应的概率分布pm(ω|x)和自除偏输入sdb(x,y)的概率分布pm(ω|sdb(x,y))输入算法中,通过计算得到新的概率分布;
59、基于计算得到新的概率分布通过比较标记单词对应概率大小,输出最大概率对应的标记单词。
60、进一步的,所述新的概率分布的计算公式为:
61、
62、其中,m表示语言模型;
63、x表示原始输入,即传入语言模型m的语句或单词;
64、y表示属性的文本描述;
65、ω表示模型m在接收输入后可能的输出;
66、pm(ω|x)表示原始输入x对应的概率分布;
67、pm(ω|sdb(x,y))表示自除偏输入sdb(x,y)对应的概率分布;
68、δ(ω,x,y)表示pm(ω|x)和pm(ω|sdb(x,y))的差值;
69、表示新的概率分布;
70、α:r→[0,1]表示缩放函数,其范围在[0,1]之间,用于改变基于差值δ(ω,x,y)的偏见词的概率,r表示实数域。
71、本发明的有益效果为:
72、1、本发明能够证明语言模型,尤其是大型语言模型,具有自我诊断的能力,基于这种能力,可以构建简单方法,通过模型输出、自我诊断及删除不期望出现情况的方法降低模型输出不当语言的概率。
73、2、本发明通过使用自去偏置输入和缩放函数,构建自我除偏算法降低模型输出不当词语的概率大小(得分),从而减少不当词语的输出。
74、3、本发明通过引入缩放函数中的超参数衰减常数λ,以避免在特定情况下出现强迫某些词概率为零使得无法评估语言模型质量。
- 还没有人留言评论。精彩留言会获得点赞!