一种基于对比学习和动态卷积的细粒度文本生成图像方法
本发明属于图像生成的领域,具体涉及一种基于对比学习和动态卷积的细粒度文本生成图像方法,是根据给定的英文句子表述,生成符合英文句子语义的图像。
背景技术:
1、当听见或者看到一句话时,人们会不自觉的联想出这句话对应的画面。人可以轻松的处理语言信息和视觉信息的转换。能够理解语言和图片之间复杂关系,实现文本信息到图像信息的转化,是实现真正人工智能的前提。
2、图像具象化文字,相比文字更加生动。图像可以简单而直观的传达信息,比如儿童图书中带有大量的图像,儿童更容易理解接受。相比于文本,图像可以在短时间内获得更多的信息,并且不同国家的人都可以理解同一幅图像信息。同时,人类更加善于记忆图像或者画面,比如很多记忆方法是把文字信息转变成一个画面场景进行记忆,达到短时间记忆更多文字信息的效果。图像相对于文本有很多好处,但是图像信息的生产和获取难度相对文本信息会更加困难。如果能够让计算机理解文本和图像的映射关系,就可以轻松的获取大量符合文本语义的高分辨率图像。文本生成图像是根据文本信息和噪音向量生成符合文本语义的图像,可以通过改变输入的噪音向量来得到大量符合给定文本语义的图像。这极大减小了获取图像的难度。文本生成图像在视觉问答、娱乐交互和计算机辅助设计等方面具有巨大的潜力。
3、文本生成图像需要先根据训练集中的文本和图像对文本进行编码,再根据编码生成图像。如果仅使用单个句子提取的文本编码可能会遗漏一些关键的细节描述,无法提供足够的语义信息来帮助生成对抗网络(gan)生成细节丰富的图像。在attngan中,引入单词信息来帮助生成器生成图像的不同子区域,通过提供更多的文本信息来更好地表达文本语义,帮助生成器生成高质量图像,进而达到当时最先进的效果。最近,df-gan通过串联多个深度文本图像融合块,将句子信息有效地融入视觉特征之中。df-gan在只使用了句子信息的情况下,生成图像的质量远远超过attngan生成图像的质量,这证明attngan使用直接拼接的方式融合图像特征和单词信息并不能实现文本信息和视觉特征的深度融合。所以,在生成图像的过程中,合理地利用文本信息,使得文本信息能够更充分有效地融合进图像特征之中,也是决定生成图像视觉真实性和生成图像符合文本语义的关键因素。因此,尽可能提供更多文本信息表示文本语义和把文本信息有效融入图像特征之中是文本生成图像任务的两个关键因素。为此,本发明提出在df-gan中的深度文本图像融合块中合理的添加单词信息,充分挖掘文本语义的同时,使单词信息能够有效地融入图像特征之中。
4、其次,为了进一步促使生成图像和文本在潜在语义上保持一致,本发明将对比损失应用在真实图像与生成图像之间,减小相同语义图像对之间的距离,增大不同语义图像对之间的距离。通过使生成图像更“像”真实图像的方式,促进生成图像符合文本语义。
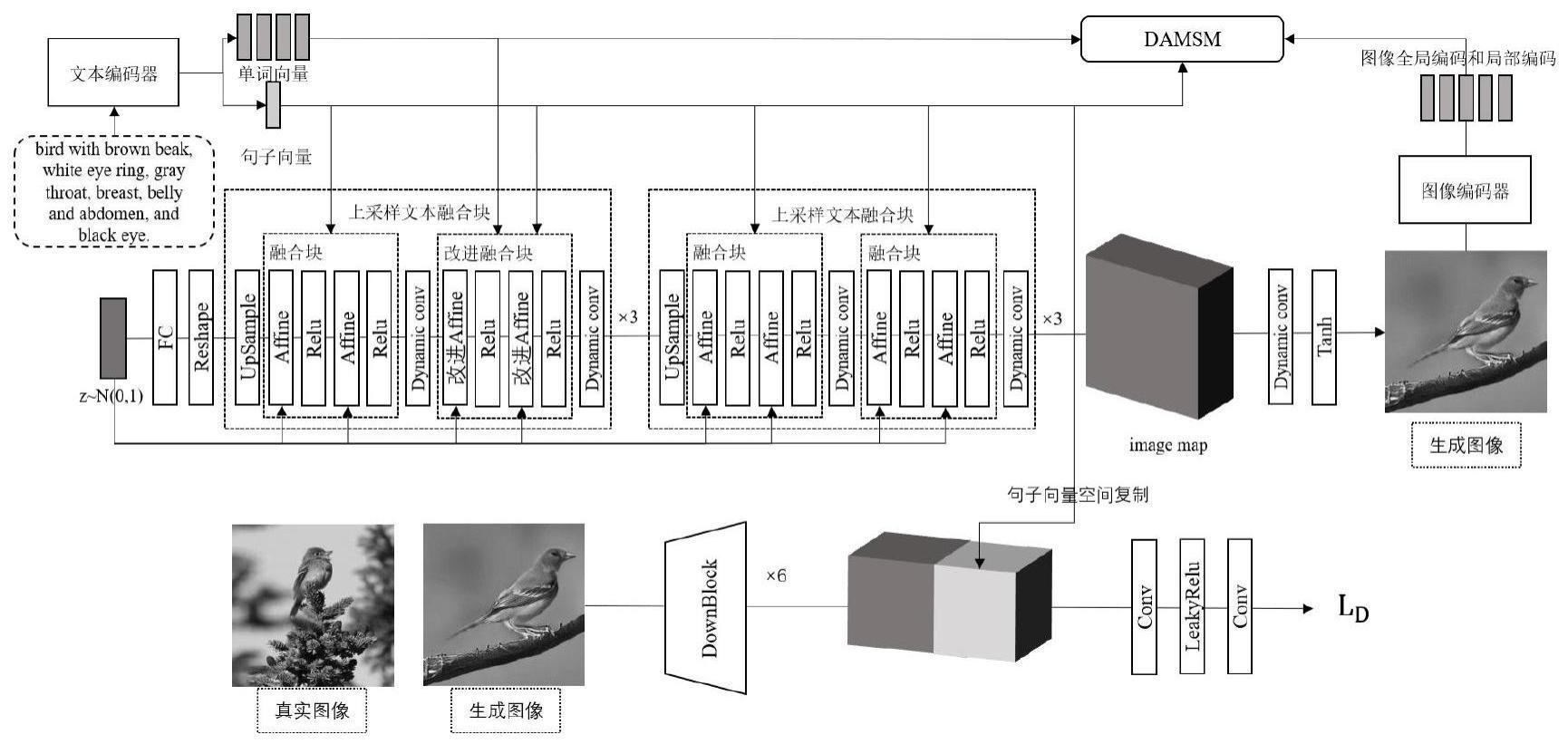
5、最后,由于df-gan在生成图像的过程中使用普通卷积,使得不同语义文本输入使用相同的卷积核参数。为了更好使生成器根据给定文本动态地生成图像,本发明引入动态卷积。由于不同语义文本对应的图像有很大差异,动态卷积可以根据融入语义后的图像特征动态地调整多个卷积核的权重,使生成器间接的根据输入的文本信息动态地生成图像,进而提高生成图像的质量。
技术实现思路
1、本发明的目的是针对现有技术的不足,提出基于对比学习和动态卷积的细粒度文本生成图像方法,引入单词信息,使生成器能够根据单词信息生成图像的子区域,使生成图像具有更丰富的细节,加入对比损失,使给定文本和生成图像在潜在语义上更加一致,生成器采用动态卷积,在只增加少量的计算成本的情况下,强化了生成器的表达能力,使生成对抗网络更快收敛。
2、第一方面,提供基于对比学习和动态卷积的细粒度文本生成图像方法,包括以下步骤:
3、步骤(1)、获取英文文本,以及英文文本语义相同的真实图像;
4、步骤(2)、构建文本编码器、图像编码器,并对其训练;
5、步骤(3)、构建文本生成图像模型,并对其训练;
6、所述文本生成图像模型采用df-gan作为基准模型,包括生成器、鉴别器;
7、所述生成器包括依次串联的全连接层、reshape函数、6个串联的上采样文本融合块、动态卷积层、tanh函数;
8、所述6个串联的上采样文本融合块中前三个上采样文本融合块结构相同,其包括依次串联的第一上采样层、第一融合块、第一动态卷积层、第二改进融合块、第二动态卷积层;后三个上采样文本融合块结构相同,其包括依次串联的第二上采样层、第三融合块、第三动态卷积层、第四融合块、第四动态卷积层;
9、所述第一融合块、第三融合块、第四融合块结构相同,均各自包括依次串联的第一affine层、第一relu函数、第二affine层、第二relu函数;
10、所述第二改进融合块包括依次串联的第三改进affine层、第三relu函数、第四改进affine层、第五relu函数;
11、所述第一affine层、第二affine层结构相同,均是用于将句子信息融合至图像特征;具体是:
12、①将句子编码s,噪音向量z进行拼接,作为当前子区域的文本条件;通过多层感知机从上述文本条件中得到通道缩放参数γj1和移位参数θj1,每个子区域j都有一个多层感知机mlpj1,实现每个子区域都有自己的缩放参数和移位参数;
13、γj1=mlpj1(concat(z,s)) 式(1)
14、θj1=mlpj1(concat(z,s)) 式(2)
15、其中concat()表示拼接函数;j表示图像特征的第j个子区域;
16、②将上一层输出的图像特征经过仿射变换,使图像子区域融入句子信息;
17、aff(hjlast1|concat(z,s))=γ1jhjlast1+θ1j 式(3)
18、其中aff表示仿射变换;n1表示当前图像特征的子区域数量,表示当前图像特征hlast1的子区域维度。
19、所述第三改进affine层、第四改进affine层结构相同,均用于将句子信息和单词信息融合至图像特征;具体是:
20、①使用1×1卷积把单词编码e∈rd×l转化为与当前图像特征维度相同的单词编码
21、
22、其中u1表示维度变换矩阵;表示当前图像特征hlast2的子区域的维度;
23、②将e′和上一层输出的图像特征相乘,归一化后得到当前图像特征的权重:
24、
25、其中αj,i表示当前图像特征第j个子区域对第i个单词的权重,上标t表示转置;n2当前图像特征hlast2的子区域的维度;
26、③通过αj,i与单词编码相乘,得到与当前图像子区域相关所有单词的动态表示cj,即为单词上下文向量;
27、
28、④将句子编码s,单词上下文向量cj和噪音向量z进行拼接,作为当前子区域的文本条件;通过多层感知机mlp2j从上述文本条件中得到通道缩放参数γ2j和移位参数θ2j,实现每个子区域都有自己的缩放参数和移位参数;
29、γ2j=mlp2j(concat(z,s,cj)) 式(7)
30、θ2j=mlp2j(concat(z,s,cj)) 式(8)
31、⑤将上一层输出的图像特征经过仿射变换,使图像子区域不但会融合句子信息,还会使图像子区域能够融入与当前子区域最相关的单词信息,弥补了原始框架只使用句子信息可能忽略单词信息的问题,使生成器实现细粒度生成图像;
32、aff(hjlast2|concat(z,s,cj))=γ2jhjlast2+θ2j 式(9)
33、所述鉴别器包括依次串联的6个相同的下采样层、第一卷积层、leakyrelu层和第二卷积层;每个下采样层包括2个卷积层、两个leakyrelu层;
34、步骤(4)、利用训练好的文本生成图像模型实现文本生成图像。
35、第二方面,提供一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行所述的方法。
36、第三方面,提供一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现所述的方法。
37、本发明采用以上技术方案与现有技术相比,有益效果为:
38、(1)本发明基于注意力机制在df-gan上引入单词信息,使生成器能够根据单词信息生成图像的子区域,使生成图像具有更丰富的细节。
39、(2)本发明加入对比损失,使相同语义图像之间更加接近,不同语义图像之间更加疏远,从而更好地保证文本与生成图像之间的语义一致性。
40、(3)本发明在生成器采用动态卷积,在只增加少量的计算成本的情况下,强化了生成器的表达能力,使生成对抗网络更快收敛。
- 还没有人留言评论。精彩留言会获得点赞!