一种基于改进的海鸥算法和XGBoost的模糊时间序列预测方法
本发明属于模糊时间序列预测领域,涉及一种基于改进的海鸥算法和xgboost的模糊时间序列预测方法。
背景技术:
1、在现实世界普遍存在着大量含糊、不准确和不完整的数据,一般的时间序列预测方法无法处理这类数据,因此,根据这类模糊数据提出了模糊时间序列预测模型。1965年,美国控制论专家zadeh教授发表的模糊集论文突破了经典集合理论,为模糊理论学奠定了理论基础,随着模糊理论的不断发展与完善,1993年,song和chissom两位学者在模糊理论的基础上首次提出了模糊时间序列预测模型,并对alabama大学的招生人数进行了有效预测,由此模糊时间序列预测理论和和相关研究蓬勃发展起来。在随后的研究中,模糊时间序列预测模型得到了发展和完善,大量的学者对模糊时间序列预测模型从理论到应用进行了广泛的研究,随着信息化时代的不断进步,该模型的应用领域也越来越广泛。近年来,随着各种群智能优化算法不断的涌现,将各种群智能优化算法与模糊预测模型相结合,提出相应的混合预测模型已经成为了模糊时间序列模型的研究热点。海鸥算法,是由dhiman和kumar于2018年提出的一种新型群体智能优化算法,该算法主要模拟了自然界中海鸥迁徙以及迁徙过程中的攻击行为(觅食行为)。海鸥优化算法较同类仿生优化算法有更好的收敛速度和寻优能力,但是易早熟收敛。
2、模糊区间划分是模糊时间序列预测中非常重要的一步,模糊区间划分大致可以分为等长度区间划分、聚类技术划分、和优化算法划分三种方法。
3、(1)等长度区间划分方法缺点十分明显:第一,预测精度不够高;其次,这种划分方法得到的区间所对应的模糊集在语意解释上有点牵强,具有很强的主观性和随意性,不容易被人理解和接受。
4、(2)以聚类技术的方法和优化技术为基础的方法可以把论域分割成大小不等间隔,能反映出时间序列的数据点的分布密度,一般都会得到比等区间划分方法更高的预测精度,然而聚类技术会忽略时间序列的趋势变化(即时间序列的一阶差分)信息,这显然会模糊区间划分合理性。若采取基于比率的不等长划分方法,则又存在只考虑趋势信息,忽略时间序列数据本身分布情况的问题。
5、(3)基于优化算法划分区间方法在预测精度上有很大的提高,但仿生优化算法在寻优过程中一般都会面临收敛速度慢和易陷入局部最优的问题。
6、(4)模糊关系是指模糊时间序列中时刻先后顺序的关系。模糊时间序列预测模型正是依赖时刻先后顺序的因果关系来进行预测,但是传统的模糊关系和模糊规则的处理方法往往无法注意到长期的趋势,而导致预测结果的精度下降。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种基于改进的海鸥算法和xgboost的模糊时间序列预测方法,提高模糊时间序列预测模型的预测精度。
2、为达到上述目的,本发明提供如下技术方案:
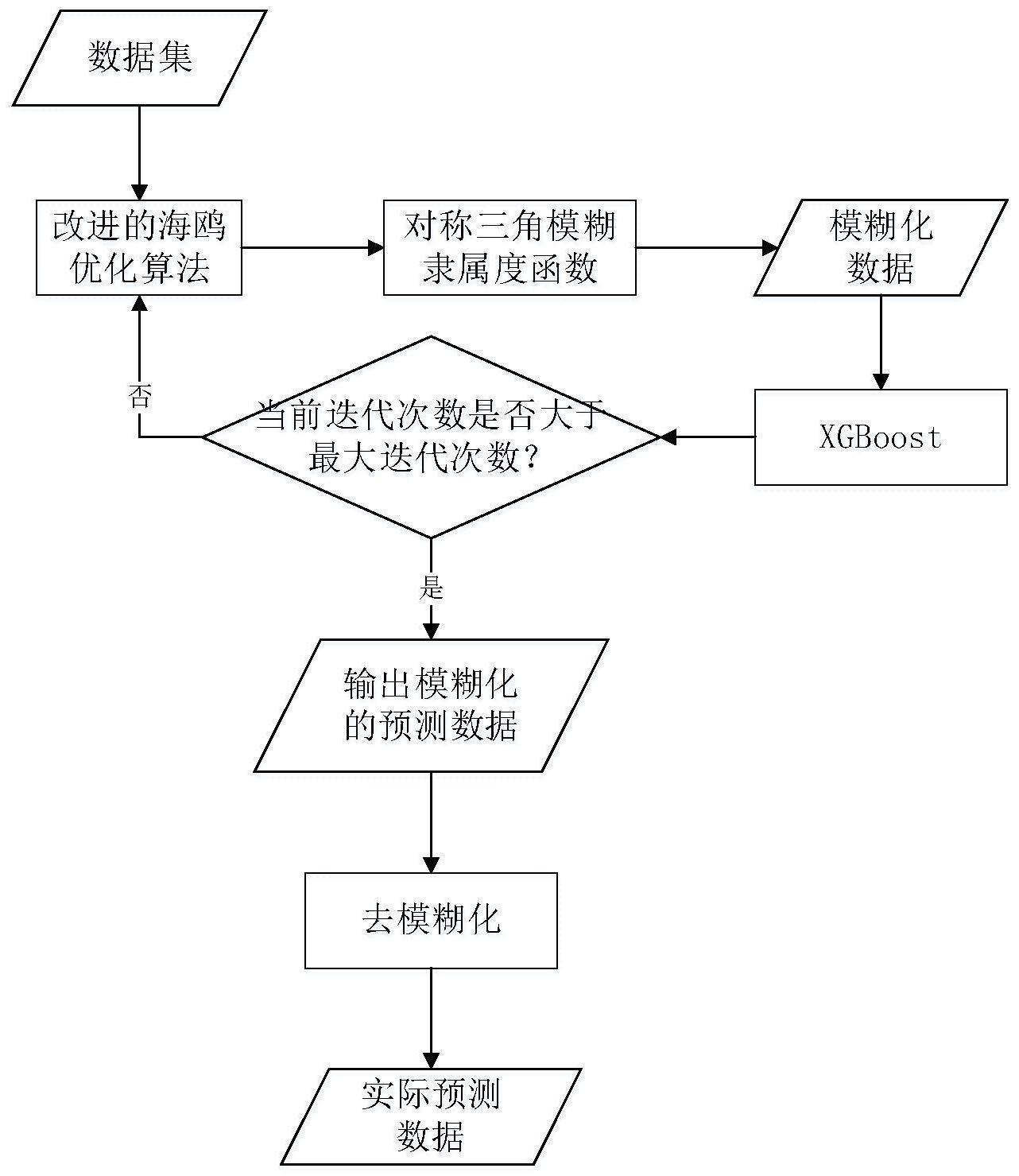
3、一种基于改进的海鸥算法和xgboost的模糊时间序列预测方法,其包括以下步骤:
4、s1、确定模糊时间预测模型的参数,包括模糊区间数n、模糊时间序列预测模型的阶数p、改进的海鸥优化算法的种群数量p以及改进的海鸥优化算法的最大迭代次数maxiteration;
5、s2、基于随机迁徙行为和powell算法对海鸥优化算法进行改进;
6、s3、通过改进的海鸥算法将论域u划分为n个区间{u1,u2,…un},输出n-1个分割点;
7、s4、采用对称三角模糊隶属度函数将原始时间序列数据模糊化;
8、s5、训练xgboost模型以预测模糊隶属度变化,输出模糊时间序列f(t);
9、s6、判断海鸥优化算法当前的迭代次数是否大于maxiteration,若小于,则返回步骤s2,若大于,则对模糊时间序列f(t)进行去模糊化,得到实际预测数据。
10、进一步地,步骤s2包括以下步骤:
11、s21、在步骤s1已确定的参数的基础上,设置如下参数:海鸥活动的上界ub和下界lb以及超参数fc;
12、s22、初始化海鸥群体,包括每只海鸥的位置和适应值,并确定最佳海鸥个体;同时赋予海鸥一个随机迁徙动作:
13、ws(t)=a*ps(t)*cos(2ωπ)
14、式中,ws(t)表示随机迁徙动作,ω表示随机数,ω∈(0,1);
15、s23、执行海鸥的迁徙行为:首先计算出每个海鸥个体的最佳位置pbs(t)的方向ms(t),再向ms(t)移动且通过参数b平衡,最后到达新位置ds(t);
16、s24、执行海鸥的攻击行为:每个海鸥个体随机螺旋运动向四周搜索适应值更小的位置,并更新完成一次迭代后的位置ps(t);同时,将powell算法引入海鸥的攻击行为中,如下式所示:
17、if t%n≡0then ps(t)=powell(ps(t))
18、式中,n表示每n次迭代后使用一次powell算法进行局部搜索。
19、进一步地,步骤s5具体为:在xgboost模型的训练阶段,建立p阶模糊时间序列预测模型:
20、(f(t-p),f(t-p+1),…,f(t-1),f(t))
21、则在预测阶段,xgboost模型的输入为{f(t-p),f(t-p+1),…,f(t-1(,输出为f(t)。
22、同时,在步骤s5中,针对模糊时间序列f(t)进行标准化。
23、进一步地,在步骤s6中,对模糊时间序列f(t)进行去模糊化的步骤具体为:
24、先确定实际预测数据的范围:
25、根据模糊区间数n,f(t)可表示为:
26、
27、式中,表示模糊隶属度;
28、若存在两个相邻的模糊隶属度之和趋近于1,则实际预测数据在范围(ci,ci+1)之间,其中ci表示区间ui的中心,此时实际预测数据计算方式为:
29、
30、若模糊隶属度或者趋近于1,则实际预测数据在区间u1或un中,即为或者
31、本发明的有益效果在于:
32、(1)本发明通过使用powell算法和随机迁徙行为来改进海鸥优化算法,提高了算法的收敛能力,解决了海鸥算法易早熟收敛且易陷入局部最优值的问题,这一改进使得海鸥优化算法更加准确和高效;
33、(2)本发明使用xgboost模型对每个区间的模糊隶属度的变化进行预测,克服了模糊关系导致的精度不高的问题,使得模糊时间预测模型更加精准和可靠。
34、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
技术特征:
1.一种基于改进的海鸥算法和xgboost的模糊时间序列预测方法,其特征在于:该方法包括以下步骤:
2.根据权利要求1所述的模糊时间序列预测方法,其特征在于:步骤s2包括以下步骤:
3.根据权利要求1所述的模糊时间序列预测方法,其特征在于:步骤s5具体为:在xgboost模型的训练阶段,建立p阶模糊时间序列预测模型:
4.根据权利要求1所述的模糊时间序列预测方法,其特征在于:在步骤s5中,针对模糊时间序列f(t)进行标准化。
5.根据权利要求1所述的模糊时间序列预测方法,其特征在于:在步骤s6中,对模糊时间序列f(t)进行去模糊化的步骤具体为:
技术总结
本发明涉及一种基于改进的海鸥算法和XGBoost的模糊时间序列预测方法,属于模糊时间序列预测领域。该方法具体为:确定模糊时间预测模型的参数;基于随机迁徙行为和Powell算法对海鸥优化算法进行改进;通过改进的海鸥算法将论域U划分为n个区间;采用对称三角模糊隶属度函数将原始时间序列数据模糊化;训练XGBoost模型以预测模糊隶属度变化,输出模糊时间序列F(t);判断海鸥优化算法当前的迭代次数是否大于最大迭代次数,若小于,返回继续改进海鸥优化算法,若大于,则去模糊化,得到实际预测数据。本发明能够提高模糊时间序列预测模型的预测精度,使得预测结果更精准可靠。
技术研发人员:陈开源,鲜思东
受保护的技术使用者:重庆邮电大学
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!