基于分布式集群的数据处理方法、系统、设备及存储介质与流程
本发明涉及数据处理,特别是涉及一种基于分布式集群的数据处理方法、系统、设备及存储介质。
背景技术:
1、目前,人工智能正与5g、云计算、边缘计算等新一代信息技术互为支撑,推动生产生活方式和社会治理方式的智能化变革,而伴随而来的是人工智能落地场景日趋复杂化,融合云边端设备的跨域分布式人工智能占比越来越高。
2、深度学习模型的应用极为广泛,例如手机中的植物物种识别,语音识别并转换为文字等。部署在终端设备中的深度学习模型初期训练所需算力较为庞大,单个终端设备计算能力不足,并且单个终端设备所拥有的训练数据不足,因此,最常见的一种解决方案是联合边缘域内所有的终端设备实现分布式训练,共同更新模型参数,最终完成深度学习模型训练。
3、传统的跨域分布式优化算法,通常采用的是sgd(stochastic gradient descent,随机梯度下降)算法,是一种简单但非常有效的方法,但是该算法收敛速度较慢。
4、此外,用边缘域设备进行协同模型训练时,面临数据传输带宽受限,通信传输负载重的问题,不利于实现高效的训练。
5、综上所述,如何进行深度学习模型的分布式训练,提高收敛速度,提高训练速度,是目前本领域技术人员急需解决的技术问题。
技术实现思路
1、本发明的目的是提供一种基于分布式集群的数据处理方法、系统、设备及存储介质,以进行深度学习模型的分布式训练,提高收敛速度,提高训练速度。
2、为解决上述技术问题,本发明提供如下技术方案:
3、一种基于分布式集群的数据处理方法,应用于分布式集群中的每一个终端设备中,且n个终端设备均与目标边缘域设备通信连接,n为正整数,所述基于分布式集群的数据处理方法包括:
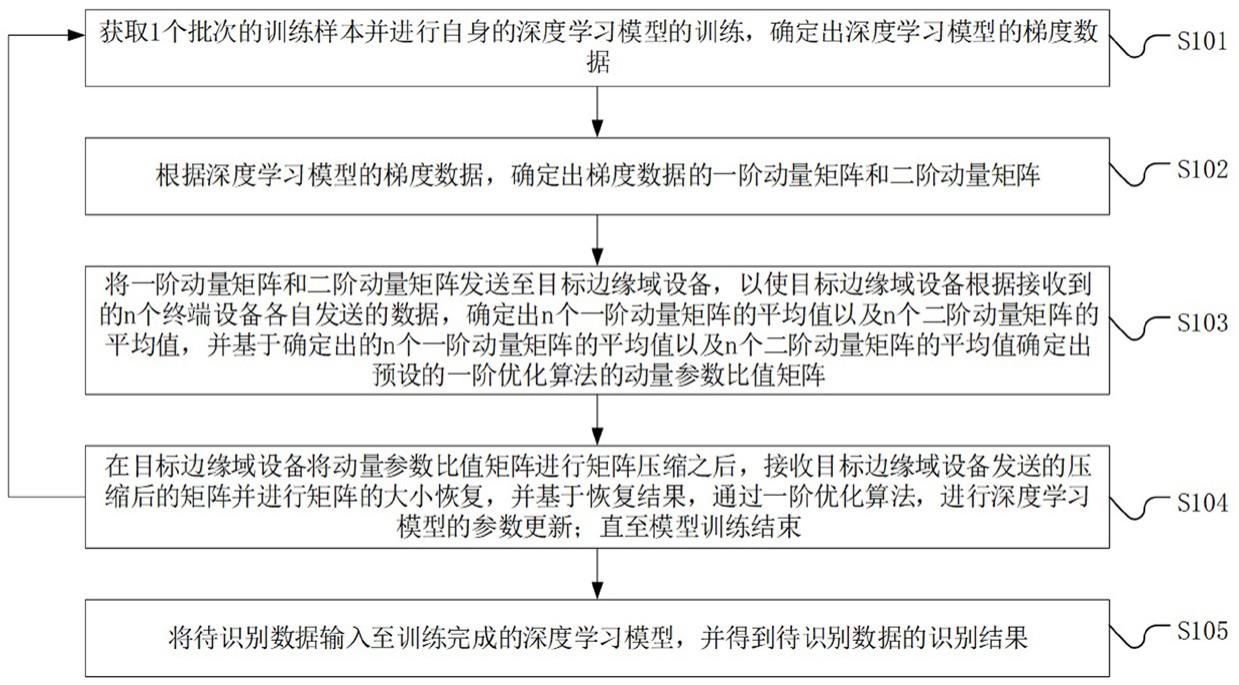
4、获取1个批次的训练样本并进行自身的深度学习模型的训练,确定出所述深度学习模型的梯度数据;
5、根据所述深度学习模型的梯度数据,确定出所述梯度数据的一阶动量矩阵和二阶动量矩阵;
6、将所述一阶动量矩阵和所述二阶动量矩阵发送至所述目标边缘域设备,以使所述目标边缘域设备根据接收到的n个终端设备各自发送的数据,确定出n个一阶动量矩阵的平均值以及n个二阶动量矩阵的平均值,并基于确定出的n个一阶动量矩阵的平均值以及n个二阶动量矩阵的平均值确定出预设的一阶优化算法的动量参数比值矩阵;
7、在所述目标边缘域设备将所述动量参数比值矩阵进行矩阵压缩之后,接收所述目标边缘域设备发送的压缩后的矩阵并进行矩阵的大小恢复,并基于恢复结果,通过所述一阶优化算法,进行所述深度学习模型的参数更新,并返回执行所述获取1个批次的训练样本并进行自身的深度学习模型的训练的操作,直至模型训练结束;
8、将待识别数据输入至训练完成的所述深度学习模型,并得到所述待识别数据的识别结果。
9、优选的,在确定出所述梯度数据的一阶动量矩阵之后,还包括:
10、判断基于本批次的训练样本所确定出的一阶动量矩阵,与基于上一批次的训练样本所确定出的一阶动量矩阵之间的差值是否小于预设的第一数值;
11、如果是,则对基于本批次的训练样本所确定出的一阶动量矩阵进行保存,并且针对后续的各个训练批次,均使用所保存的所述一阶动量矩阵作为确定出的所述梯度数据的一阶动量矩阵。
12、优选的,在确定出所述梯度数据的二阶动量矩阵之后,还包括:
13、判断基于本批次的训练样本所确定出的二阶动量矩阵,与基于上一批次的训练样本所确定出的二阶动量矩阵之间的差值是否小于预设的第二数值;
14、如果是,则对基于本批次的训练样本所确定出的二阶动量矩阵进行保存,并且针对后续的各个训练批次,均使用所保存的所述二阶动量矩阵作为确定出的所述梯度数据的二阶动量矩阵。
15、优选的,在确定出所述梯度数据的一阶动量矩阵和二阶动量矩阵之后,还包括:
16、对一阶动量矩阵和二阶动量矩阵均进行偏置校正;
17、相应的,所述将所述一阶动量矩阵和所述二阶动量矩阵发送至所述目标边缘域设备,包括:
18、将进行了偏置校正之后的一阶动量矩阵和进行了偏置校正之后的二阶动量矩阵发送至所述目标边缘域设备。
19、优选的,在确定出所述梯度数据的一阶动量矩阵和二阶动量矩阵之后,还包括:
20、对一阶动量矩阵进行cholesky分解;
21、相应的,将所述一阶动量矩阵发送至所述目标边缘域设备,包括:
22、将 m或者 m t发送至所述目标边缘域设备以使所述目标边缘域设备根据接收的数据恢复出所述一阶动量矩阵;
23、其中, m表示的是对所述一阶动量矩阵进行cholesky分解之后所得到的三角矩阵, m t表示的是三角矩阵 m的转置矩阵。
24、优选的,在确定出所述梯度数据的一阶动量矩阵和二阶动量矩阵之后,还包括:
25、对二阶动量矩阵进行cholesky分解;
26、相应的,将所述二阶动量矩阵发送至所述目标边缘域设备,包括:
27、将 v或者 v t发送至所述目标边缘域设备以使所述目标边缘域设备根据接收的数据恢复出所述二阶动量矩阵;
28、其中, v表示的是对所述二阶动量矩阵进行cholesky分解之后所得到的三角矩阵, v t表示的是三角矩阵 v的转置矩阵。
29、优选的,所述目标边缘域设备将所述动量参数比值矩阵进行矩阵压缩,包括:
30、所述目标边缘域设备将所述动量参数比值矩阵进行矩阵的量化压缩。
31、优选的,所述目标边缘域设备将所述动量参数比值矩阵进行矩阵的量化压缩,包括:
32、所述目标边缘域设备将 a× b大小的所述动量参数比值矩阵,按照每相邻的 k个数据求平均值的方式,进行矩阵的量化压缩,得到大小的压缩后的矩阵。
33、优选的,所述目标边缘域设备基于确定出的n个一阶动量矩阵的平均值以及n个二阶动量矩阵的平均值确定出预设的一阶优化算法的动量参数比值矩阵,包括:
34、所述目标边缘域设备基于确定出的n个一阶动量矩阵的平均值以及n个二阶动量矩阵的平均值,按照的方式,确定出预设的一阶优化算法的动量参数比值矩阵 r t;
35、其中,表示的是所述目标边缘域设备确定出的n个一阶动量矩阵的平均值,表示的是所述目标边缘域设备确定出的n个二阶动量矩阵的平均值,ε为预设的第三参数且ε>0。
36、优选的,基于恢复结果,通过所述一阶优化算法,进行所述深度学习模型的参数更新,包括:
37、通过进行所述深度学习模型的参数更新;
38、其中, x t表示的是进行第 t次训练之后的所述深度学习模型的参数, x t+1表示的是进行第 t+1次训练之后的所述深度学习模型的参数, η表示的是学习率, λ表示的是衰减系数,为 r t´表示的是在接收所述目标边缘域设备发送的压缩后的矩阵并进行矩阵的大小恢复之后,所得到的恢复结果。
39、优选的,根据所述深度学习模型的梯度数据,确定出所述梯度数据的一阶动量矩阵,包括:
40、根据所述深度学习模型的梯度数据,通过 m t= β1 m t-1+(1- β1) g t确定出所述梯度数据的一阶动量矩阵;
41、其中, β1表示的是预设的第一参数, m t表示的是进行第 t次训练时所确定出的梯度数据的一阶动量矩阵, m t-1表示的是进行第 t-1次训练时所确定出的梯度数据的一阶动量矩阵, g t表示的是进行第 t次训练时所确定出的所述深度学习模型的梯度数据, t表示的是训练次数。
42、优选的,根据所述深度学习模型的梯度数据,确定出所述梯度数据的二阶动量矩阵,包括:
43、根据所述深度学习模型的梯度数据,通过 v t= β2 v t-1+(1- β2)( g t- m t)2确定出所述梯度数据的二阶动量矩阵;
44、其中, β2表示的是预设的第二参数, m t表示的是进行第 t次训练时所确定出的梯度数据的一阶动量矩阵, v t表示的是进行第 t次训练时所确定出的梯度数据的二阶动量矩阵, v t-1表示的是进行第 t-1次训练时所确定出的梯度数据的二阶动量矩阵, g t表示的是进行第 t次训练时所确定出的所述深度学习模型的梯度数据, t表示的是训练次数。
45、优选的,所述将待识别数据输入至训练完成的所述深度学习模型,并得到所述待识别数据的识别结果,包括:
46、将待识别数据输入至训练完成的所述深度学习模型,进行计算机图像识别、或者进行自然语言识别、或者进行模式识别,得到所述待识别数据的识别结果。
47、优选的,所述模型训练结束的触发条件为:
48、所述深度学习模型收敛,和/或进行所述深度学习模型的训练次数达到了设定的次数阈值。
49、优选的,还包括:
50、当失去与所述目标边缘域设备的通信连接时,输出故障提示信息。
51、优选的,还包括:
52、对与所述目标边缘域设备之间的通信耗时进行统计。
53、优选的,所述终端设备所使用的所述深度学习模型为数据中心发送的进行了模型预训练的深度学习模型。
54、一种基于分布式集群的数据处理系统,应用于分布式集群中的每一个终端设备中,且n个终端设备均与目标边缘域设备通信连接,n为正整数,所述基于分布式集群的数据处理系统包括:
55、梯度数据确定模块,用于获取1个批次的训练样本并进行自身的深度学习模型的训练,确定出所述深度学习模型的梯度数据;
56、动量确定模块,用于根据所述深度学习模型的梯度数据,确定出所述梯度数据的一阶动量矩阵和二阶动量矩阵;
57、动量发送模块,用于将所述一阶动量矩阵和所述二阶动量矩阵发送至所述目标边缘域设备,以使所述目标边缘域设备根据接收到的n个终端设备各自发送的数据,确定出n个一阶动量矩阵的平均值以及n个二阶动量矩阵的平均值,并基于确定出的n个一阶动量矩阵的平均值以及n个二阶动量矩阵的平均值确定出预设的一阶优化算法的动量参数比值矩阵;
58、参数更新模块,用于在所述目标边缘域设备将所述动量参数比值矩阵进行矩阵压缩之后,接收所述目标边缘域设备发送的压缩后的矩阵并进行矩阵的大小恢复,并基于恢复结果,通过所述一阶优化算法,进行所述深度学习模型的参数更新,并触发所述梯度数据确定模块,直至模型训练结束;
59、执行模块,用于将待识别数据输入至训练完成的所述深度学习模型,并得到所述待识别数据的识别结果。
60、一种基于分布式集群的数据处理设备,包括:
61、存储器,用于存储计算机程序;
62、处理器,用于执行所述计算机程序以实现如上述所述的基于分布式集群的数据处理方法的步骤。
63、一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上述所述的基于分布式集群的数据处理方法的步骤。
64、应用本发明实施例所提供的技术方案,应用于分布式集群中的每一个终端设备中,且n个终端设备均与目标边缘域设备通信连接。在训练时,各个终端设备均会获取1个批次的训练样本并进行所述深度学习模型的训练,确定出所述深度学习模型的梯度数据,本技术采用的是基于一阶动量矩阵和二阶动量矩阵的一阶优化算法,相较于传统的sgd方案,可以提高收敛速度。根据所述深度学习模型的梯度数据,可以确定出梯度数据的一阶动量矩阵和二阶动量矩阵并发送至目标边缘域设备,也即目标边缘域设备可以根据接收到的n个终端设备各自发送的数据,确定出n个一阶动量矩阵的平均值以及n个二阶动量矩阵的平均值,并基于确定出的n个一阶动量矩阵的平均值以及n个二阶动量矩阵的平均值确定出预设的一阶优化算法的动量参数比值矩阵。
65、考虑到动量参数比值矩阵规模较大,因此目标边缘域设备会将动量参数比值矩阵进行矩阵压缩之后再发给各个终端设备,终端设备接收目标边缘域设备发送的压缩后的矩阵之后便可以进行矩阵的大小恢复,进而基于恢复出的矩阵,通过一阶优化算法,进行所述深度学习模型的参数更新,继续下一轮训练直到模型训练结束。可以看出,由于目标边缘域设备是对动量参数比值矩阵进行了矩阵压缩之后再发送,因此降低了需要通信传输的数据量,也就有利于降低训练耗时。
66、综上所述,本技术的方案可以进行深度学习模型的分布式训练,提高了收敛速度,降低了训练耗时。
- 还没有人留言评论。精彩留言会获得点赞!