图像人物识别方法及其装置、设备、介质、产品与流程
本技术涉及目标识别领域,尤其涉及一种图像人物识别方法,此外还涉及该方法相应的装置、设备、非易失性存储介质以及计算机程序产品。
背景技术:
1、目标识别旨在对数字图像中的特定类别,如识别出图像中的人物对象,动物对象或汽车对象等,对图像中的目标对象进行预测,是许多计算机视觉任务的基础,例如实现图像中的目标对象实例分割或图像中的目标跟踪等;传统目标识别方法主要采用人工的方式提取特征,具有一定的局限性,近年来,随着深度学习飞速发展,神经网络的广泛应用使得目标识别也开启了新的征程,基于深度学习的目标识别方法根据检测思想的不同通常可分为两大类别:两阶段(two-stage)检测和一阶段(one-stage)检测,其中,两阶段检测算法基于提议的区域候选框,是一个“由粗到细”的过程,特点是精度高但速度慢,一阶段检测算法基于边界框的回归,是一个“一步到位”的过程,特点是速度快但精度稍逊;根据图像中目标的数量,检测任务可分为单目标和多目标识别任务,在单目标识别任务中,如果图像中存在特定类别对象,则需要给定对象的位置坐标和置信度得分,否则不输出任何结果,但目前现有技术中针对单目标人体识别的研究并不多,大部分研究工作针对的都是密集环境下的人体检测,并且目标识别模型的参数量多,占用的运行内存过大,无法将模型部署至普通cpu设备上做到实时目标检测。
2、鉴于现有的单目标识别模型所存在的问题,本技术人出于解决该问题的考虑做出相应的探索。
技术实现思路
1、本技术的目的在于满足用户需求而提供一种图像人物识别方法,此外还涉及该方法相应的装置、设备、非易失性存储介质以及计算机程序产品。
2、为实现本技术的目的,采用如下技术方案:
3、适应本技术的目的而提出的一种图像人物识别方法,包括如下步骤:
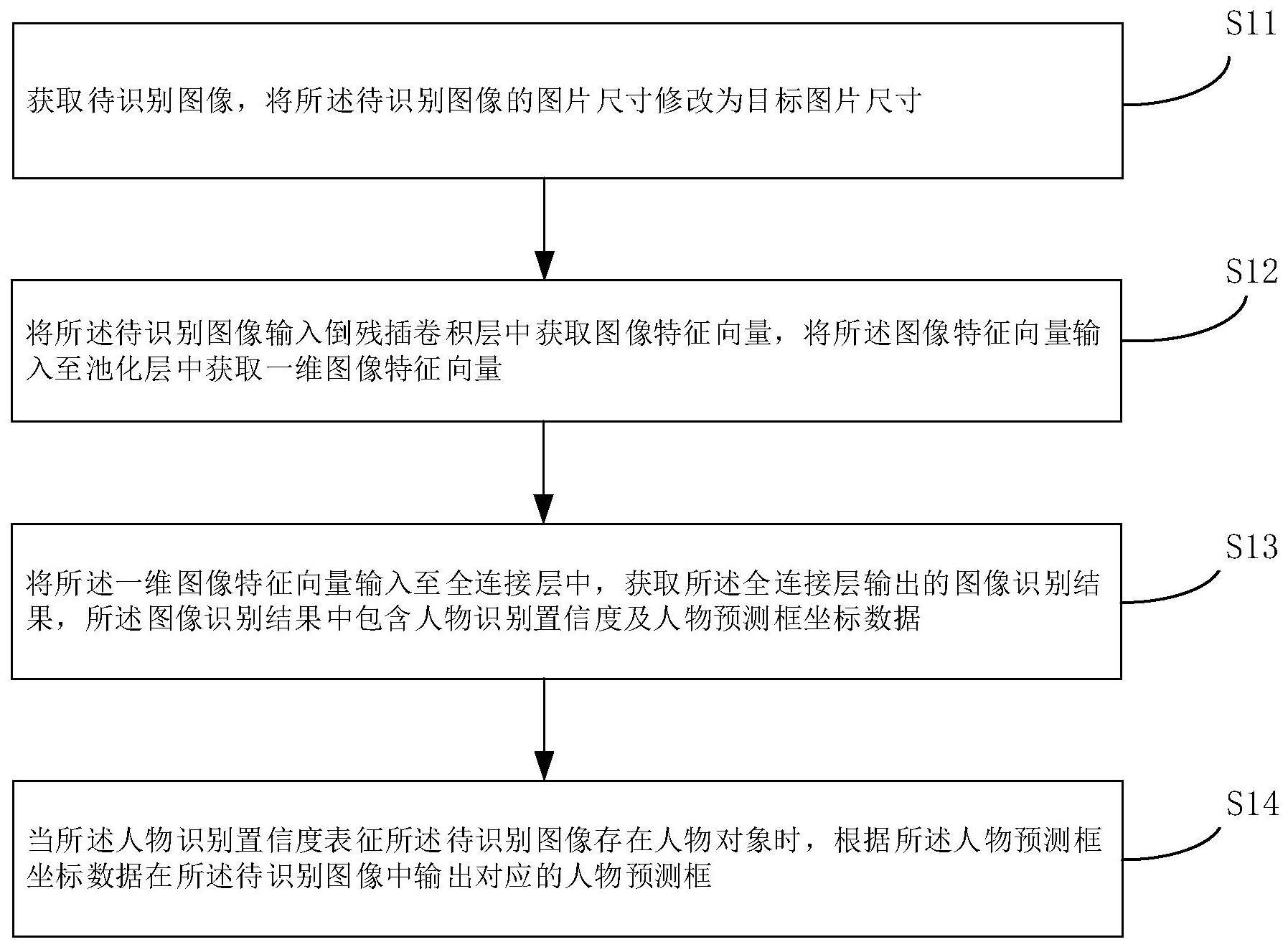
4、获取待识别图像,将所述待识别图像的图片尺寸修改为目标图片尺寸;
5、将所述待识别图像输入倒残插卷积层中获取图像特征向量,将所述图像特征向量输入至池化层中获取一维图像特征向量;
6、将所述一维图像特征向量输入至全连接层中,获取所述全连接层输出的图像识别结果,所述图像识别结果中包含人物识别置信度及人物预测框坐标数据;
7、当所述人物识别置信度表征所述待识别图像存在人物对象时,根据所述人物预测框坐标数据在所述待识别图像中输出对应的人物预测框。
8、进一步的实施例中,获取待识别图像,将所述待识别图像的图片尺寸修改为目标图片尺寸的步骤之前,包括如下步骤:
9、将为所述目标图片尺寸的训练识别图像输入至所述倒残插卷积层中获取图像特征向量,并通过所述池化层中获取所述图像特征向量的一维图像特征向量;
10、将所述一维图像特征向量输入至全连接层中,获取所述全连接层输出的训练图像识别结果;
11、根据预设的坐标框偏差数据算法,计算所述训练图像识别结果中包含的人物预测框坐标数据与所述训练识别图像对应的标注人物预测框坐标数据之间的坐标框偏差数据;
12、根据预设的交叉熵损失函数,计算所述训练图像识别结果中包含的人物识别置信度与所述训练识别图像对应的标注人物识别置信度的交叉熵损失值;
13、检测所述坐标框偏差数据与所述交叉熵损失是否分别超过各自对应的训练阈值,若皆未超过,则从样本数据集中调用下一训练识别图片及其标注人物预测框坐标数据与标注人物识别置信度实施迭代训练。
14、进一步的实施例中,将所述待识别图像输入倒残插卷积层中获取图像特征向量的步骤之中,包括如下步骤:
15、对所述待识别图像进行向量编码获取原始图像向量,调用膨胀卷积层升维提取所述原始图像向量,获取升维图像特征向量;
16、调用深度可分卷积层提取所述升维图像特征向量,获取深度图像特征向量;
17、调用压缩卷积层降维提取所述深度图像特征向量,获取降维图像特征向量;
18、对所述原始图像向量与所述降维图像特征向量进行向量相加,获取所述待待识别图像对应的图像特征向量。
19、进一步的实施例中,将所述图像特征向量输入至池化层中获取一维图像特征向量的步骤之中,包括如下步骤:
20、对所述图像特征向量的一个或多个通道的特征图分别进行全局平均池化,获取各所述特征图各自对应的池化均值;
21、生成包含各所述池化均值的一维图像特征向量。
22、进一步的实施例中,将所述一维图像特征向量输入至全连接层中,获取所述全连接层输出的图像识别结果,所述图像识别结果中包含人物识别置信度及人物预测框坐标数据的步骤之中,包括如下步骤:
23、将所述一维图像特征向量输入至所述全连接层中,其中,所述全连接层的宽度为所述一维图像特征向量具有的数据数量;
24、获取所述全连接层输出的图像识别结果,所述图像识别结果中包含人物识别置信度及人物预测框坐标数据,所述人物预测框坐标数据包含预测框左上角平面坐标数据及预测框右下角平面坐标数据。
25、进一步的实施例中,当所述人物识别置信度表征所述待识别图像存在人物对象时,根据所述人物预测框坐标数据在所述待识别图像中输出对应的人物预测框的步骤之中,包括如下步骤:
26、获取所述人物预测框坐标数据包含预测框左上角平面坐标数据及预测框右下角平面坐标数据;
27、确定出所述预测框左上角平面坐标数据及预测框右下角平面坐标数据在所述待识别图像中各自对应的坐标位置;
28、基于各所述坐标位置,所述待识别图像中输出呈矩形的人物预测框,所述人物预测框中包含所述待识别图像中人物对象的图像区域。
29、进一步的实施例中,当所述人物识别置信度表征所述待识别图像存在人物对象时,根据所述人物预测框坐标数据在所述待识别图像中输出对应的人物预测框的步骤之后,包括如下步骤:
30、获取待处理视频数据中的视频帧图像,将所述视频帧图像作为待识别图像进行人物预测框识别;
31、获取具有人物预测框的视频帧图像,获取所述待处理视频数据对应的预测框特效;
32、将所述预测框特效合成至所述所述视频帧图像中输出的人物预测框处,生成人物特效视频帧图像。
33、适应本技术的目的而提出的一种图像人物识别装置,其包括:
34、图像尺寸修改模块,用于获取待识别图像,将所述待识别图像的图片尺寸修改为目标图片尺寸;
35、图像特征提取模块,用于将所述待识别图像输入倒残插卷积层中获取图像特征向量,将所述图像特征向量输入至池化层中获取一维图像特征向量;
36、图像人物识别模块,用于将所述一维图像特征向量输入至全连接层中,获取所述全连接层输出的图像识别结果,所述图像识别结果中包含人物识别置信度及人物预测框坐标数据;
37、预测框输出模块,用于当所述人物识别置信度表征所述待识别图像存在人物对象时,根据所述人物预测框坐标数据在所述待识别图像中输出对应的人物预测框。
38、进一步的实施例中,所述图像特征提取模块包括:
39、特征升维提取子模块,用于对所述待识别图像进行向量编码获取原始图像向量,调用膨胀卷积层升维提取所述原始图像向量,获取升维图像特征向量;
40、特征深度提取子模块,用于调用深度可分卷积层提取所述升维图像特征向量,获取深度图像特征向量;
41、特征降维提取子模块,用于调用压缩卷积层降维提取所述深度图像特征向量,获取降维图像特征向量;
42、特征向量相加子模块,用于对所述原始图像向量与所述降维图像特征向量进行向量相加,获取所述待待识别图像对应的图像特征向量。
43、较佳的实施例中,所述图像特征提取模块还包括:
44、特征池化子模块,用于对所述图像特征向量的一个或多个通道的特征图分别进行全局平均池化,获取各所述特征图各自对应的池化均值;
45、一维向量生成子模块,用于生成包含各所述池化均值的一维图像特征向量。
46、进一步的实施例中,所述图像人物识别模块包括:
47、全连接输入子模块,用于将所述一维图像特征向量输入至所述全连接层中,其中,所述全连接层的宽度为所述一维图像特征向量具有的数据数量;
48、全连接输出子模块,用于获取所述全连接层输出的图像识别结果,所述图像识别结果中包含人物识别置信度及人物预测框坐标数据,所述人物预测框坐标数据包含预测框左上角平面坐标数据及预测框右下角平面坐标数据。
49、进一步的实施例中,所述预测框输出模块包括:
50、平面坐标获取子模块,用于获取所述人物预测框坐标数据包含预测框左上角平面坐标数据及预测框右下角平面坐标数据;
51、坐标位置确定子模块,用于确定出所述预测框左上角平面坐标数据及预测框右下角平面坐标数据在所述待识别图像中各自对应的坐标位置;
52、预测框输出子模块,用于基于各所述坐标位置,所述待识别图像中输出呈矩形的人物预测框,所述人物预测框中包含所述待识别图像中人物对象的图像区域。
53、为解决上述技术问题本技术实施例还提供一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机可读指令,所述计算机可读指令被所述处理器执行时,使得所述处理器执行上述所述图像人物识别方法的步骤。
54、为解决上述技术问题本技术实施例还提供一种存储有计算机可读指令的存储介质,所述计算机可读指令被一个或多个处理器执行时,使得一个或多个处理器执行上述所述图像人物识别方法的步骤。
55、为解决上述技术问题本技术实施例还提供一种计算机程序产品,包括计算机程序及计算机指令,该计算机程序及计算机指令被处理器执行时,使得所述处理器执行上述所述图像人物识别方法的步骤。
56、相对于现有技术,本技术的优势如下:
57、本技术通过构建轻量化的单目标人物对象识别模型,为移动终端设备或普通配置终端设备提供可本地执行的单目标人物对象识别功能,通过轻量化的倒残插卷积层提取需进行人物对象识别的图像的图像特征向量,并将图像特征向量池化为一维图像特征向量输入至小尺寸的全连接层中进行全连接操作获取全连接回归结果作为图像识别结果,在人物置信度表征图像存在人物对象时,根据人物预测框坐标数据在图像中输出对应的人物预测框,以通过人物预测框标示出图像中具有人物对象的图像区域。
58、其次,本技术以轻量化为目的构建的单目标人物对象识别模型,相比于两阶段模型,本技术的模型无需候选框提取的过程,相比单阶段模型,本技术的模型不需要执行非极大值抑制操作,且本技术的模型复杂度较低,易于扩展并且人物识别效果显著,一方面可以作为数据预处理模块过滤不符合条件的样本,另一方面可以作为其他视觉类任务的高效且低算力占用人物对象识别功能模块。
- 还没有人留言评论。精彩留言会获得点赞!