滑坡易发性评价方法
本发明属于土木工程领域,具体涉及一种滑坡易发性评价方法。
背景技术:
1、目前,已有的滑坡灾害易发性评价主要分为定性和定量两种:定性的方法,通常由滑坡灾害专家利用自身知识,评价区域滑坡灾害发生的可能性;但是这类方案的评价结果极其依赖专家的主观经验,可靠性和一致性都较差。定量的方法,有基于物理力学的方法和基于统计分析的方法;基于物理力学的方法,一般构建斜坡的力学模型,直接对斜坡的稳定性进行数值模拟求解;但是,该类方法需要详细的斜坡物理力学特征数据,计算过程十分费时,多用于小区域的斜坡单体易发性分析;基于统计分析的方法有证据权、信息量和频率比等数理统计方法和人工神经网络、支持向量机、决策树、随机森林、逻辑回归等机器学习方法;数理统计方法的计算虽然简单,但是其无法捕捉滑坡与影响因子间的非线性关系,易发性评价结果可靠性不高;机器学习模型擅长处理非线性问题,已经在地质灾害评价研究中表现出了较好的性能。
2、但是,尽管机器学习模型已经被广泛应用于滑坡灾害的易发性评价,但这些方案模型均面临相同的问题,即训练数据的不确定问题:没有真实的负样本(非滑坡样本)。滑坡灾害易发性评价研究中,正样本(滑坡样本)往往来自历史滑坡资料中真实发生过的部分滑坡事件,而负样本通常选择研究区内暂未发生滑坡的区域。然而,由于滑坡事件记录不完备,此方法难以保证负样本区域从未发生滑坡,同时也无法确保未发生滑坡区域完全不存在滑坡风险。因此,在这种负样本集充满不确定性的情况下,现有的滑坡灾害易发性评价方法极易将滑坡区域错误地划分为非滑坡区域,导致最终生成的滑坡易发性评价结果出现高风险区被严重低估问题。
技术实现思路
1、本发明的目的在于提供一种可靠性高、准确性好且客观科学的滑坡易发性评价方法。
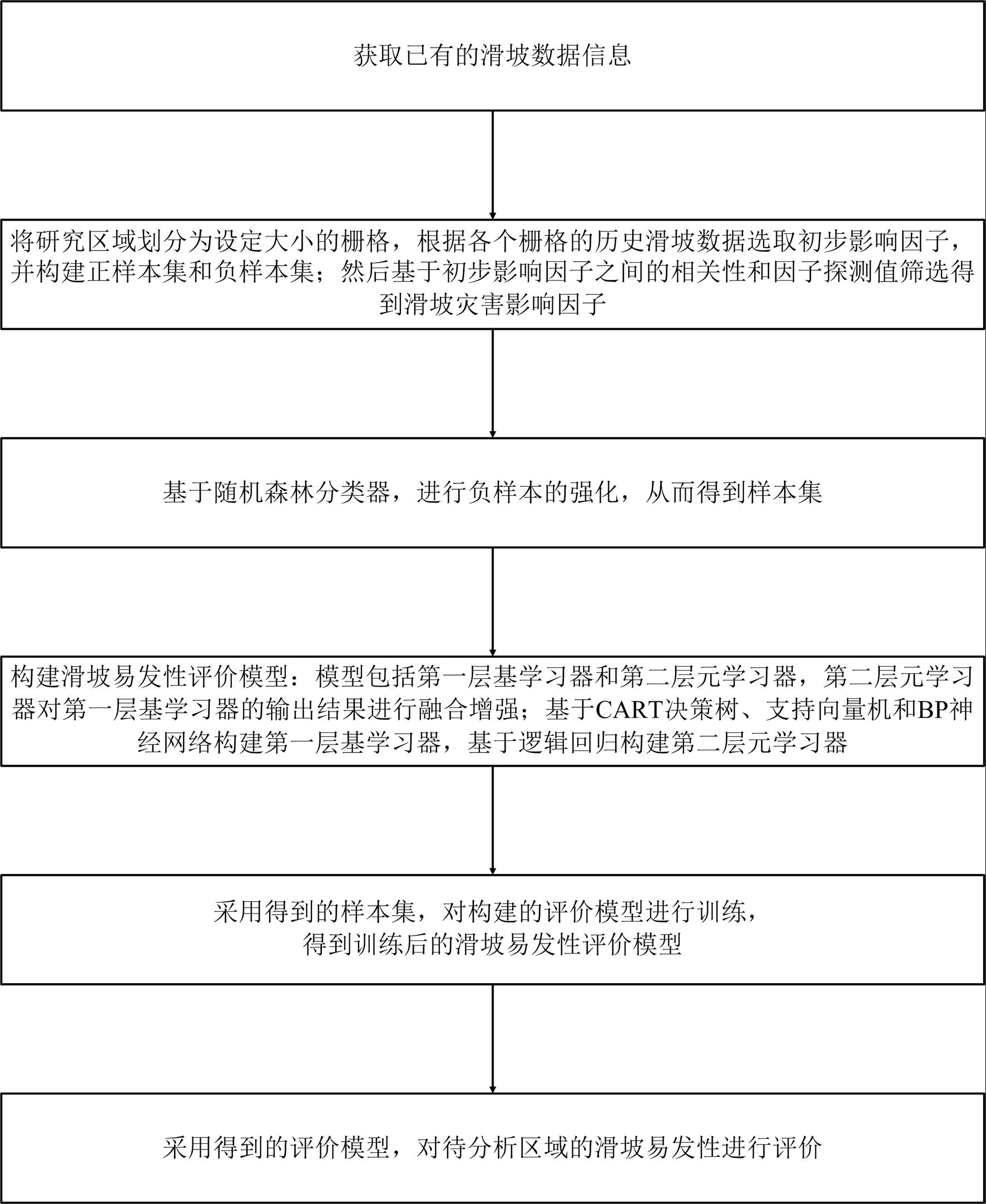
2、本发明提供的这种滑坡易发性评价方法,包括如下步骤:
3、s1. 获取已有的滑坡数据信息;
4、s2. 将研究区域划分为设定大小的栅格,根据各个栅格的历史滑坡数据选取初步影响因子,并构建正样本集和负样本集;然后基于初步影响因子之间的相关性和因子探测值筛选得到滑坡灾害影响因子;
5、s3. 基于随机森林分类器,进行负样本的强化,从而得到样本集;
6、s4. 构建滑坡易发性评价模型:模型包括第一层基学习器和第二层元学习器,第二层元学习器对第一层基学习器的输出结果进行融合增强;基于cart决策树、支持向量机和bp神经网络构建第一层基学习器,基于逻辑回归构建第二层元学习器;
7、s5. 采用步骤s3得到的样本集,对步骤s4构建的评价模型进行训练,得到训练后的滑坡易发性评价模型;
8、s6. 采用步骤s5得到的评价模型,对待分析区域的滑坡易发性进行评价。
9、所述的步骤s2,具体包括如下步骤:
10、将研究区域划分为若干个栅格;
11、根据研究区域内各个栅格的滑坡情况,选取若干个初步影响因子,并提取对应的初步影响因子栅格数据;
12、计算各个初步影响因子之间的相关性;同时计算因子探测值,用于度量初步影响因子对滑坡灾害标签的空间分异的控制程度;
13、最后,根据计算得到的相关性和因子探测值对初步影响因子进行过滤,得到最终的影响因子。
14、所述的步骤s2,具体包括如下步骤:
15、设置栅格单元大小为;将研究区域按照设定的栅格单元大小划分为若干个栅格单元;
16、根据获取的研究区域的滑坡数据信息和滑坡成因情况,选取 n个初步影响因子; n为设定值;
17、根据研究区域的历史滑坡坐标,提取滑坡坐标对应位置的初步影响因子栅格数据构成正样本集;同时,在研究区域内,随机选取与正样本集中元素数量相同的未发生滑坡的栅格,并提取对应的初步影响因子栅格数据构成负样本集;
18、采用如下算式计算任意两个初步影响因子 x1和 x2之间的相关性:式中为初步影响因子 x1和 x2之间的协方差;为初步影响因子 x1的标准差;为初步影响因子 x2的标准差;
19、采用如下算式计算因子探测值 q,用于度量初步影响因子对滑坡灾害标签的空间分异的控制程度:式中 l为变量属性的分类数;为类 h的栅格数;为类 h的 y值方差; n为全部的栅格数;为全局的 y值方差;删除相关性值大于第一设定值的初步影响因子对,并按绝对值进行降序排列;然后,在排序后的初步影响因子对中,删除因子探测值小于第二设定值的初步影响因子,并同时删除排序在初步影响因子后且含有初步影响因子的初步影响因子对;重复本步骤直至不存在相关性值大于第一设定值的初步影响因子对,最后再删除因子探测值小于第一阈值的初步影响因子;最终,将剩余的初步影响因子作为最终的影响因子。
20、所述的步骤s3,具体包括如下步骤:
21、根据研究区域的所有网格单元集和正样本集,生成若干组候选负样本集,从而构建候选样本集;
22、将候选样本集划分为训练集和测试集;每次采用一组训练集训练随机森林分类器,并根据训练结果调整随机森林分类器的参数,最终保证随机森林分类器的准确率大于设定值;
23、采用训练后的随机森林分类器,计算候选负样本集中每个负样本的滑坡易发概率,并根据得到的概率选择若干组样本构建负样本集;
24、最终,根据得到的正样本集和负样本集,构建最终的样本集。
25、所述的步骤s3,具体包括如下步骤:
26、获取研究区域的所有网格单元,构成所有网格单元集cell;将m个已知滑坡灾害所在的网络单元标记为正样本集;在所有网格单元集cell和正样本集的差集中,随机选择m个网络单元生成一组候选负样本,并重复本操作直至得到m组候选负样本;将m组候选负样本与正样本集构成m组候选样本集;
27、将候选样本集按照设定的比例划分为训练集和测试集;每次采用一组训练集训练随机森林分类器,并根据训练结果调整随机森林分类器的参数,最终保证随机森林分类器的准确率在训练集中大于第三设定值,且在测试集中大于第四设定值;
28、采用训练后的得到的m组随机森林分类器,分别计算候选样本集中每个负样本的滑坡易发概率,并依次提取每组候选负样本集中滑坡易发概率最低的负样本,构成强化后的负样本集;
29、最后,将正样本集和负样本集合并,得到最终的样本集sam。
30、所述的步骤s4,具体包括如下步骤:
31、构建具有两层学习器的评价模型:基于cart决策树、支持向量机和bp神经网络构建第一层基学习器,第二层元学习器由逻辑回归对基学习器的输出结果进行融合增强;
32、采用样本集对基学习器进行训练;
33、将基学习器的输出作为元学习器的输入,并结合样本集的标签完成训练。
34、所述的步骤s4,具体包括如下步骤:
35、构建具有两层学习器的评价模型:基于cart决策树、支持向量机和bp神经网络构建第一层基学习器,第二层元学习器由逻辑回归对基学习器的输出结果进行融合增强;
36、构建基学习器:基学习器由三个cart决策树、支持向量机和两层bp神经网络并行组成;
37、其中,cart决策树基于基尼不纯度减少最大化的方式进行分裂节点选择;采用如下算式计算数据集 t的基尼不纯度:式中 n为类别的总数;为数据集 t中类 i的概率;若数据集 t划分为和,则采用如下算式计算基尼不纯度:式中 t为数据集 t的数据量;为数据集的数据量;为数据集的数据量;
38、设定样本集特征空间线性可分,并建立支持向量机;引入径向基核函数将低维的样本空间映射到高维空间,从而实现线性可分,进而在特征空间进行最优超平面分割:式中为分割超平面函数; w为 n维权重向量; x为样本的n维特征向量; b为偏差;归一化后,的样本为 a类,的样本为 b类;
39、bp神经网络由输入层、输出层、中间各50个节点的双层网络隐含层组成;输入层为样本,输出层为样本类别,采取误差向后传播的方法更新网络节点权重;
40、构建元学习器:元学习器采用逻辑回归对基学习器的输出结果进行融合增强,减轻复杂度并防止过拟合,最后直接输出滑坡灾害易发性的概率;
41、基学习器的训练:将样本集sam的训练数据分为五折,每个基学习器依次利用其中的四折数据进行训练,并利用剩余的一折数据预测生成基学习器的输出;重复五次直至每折数据均被基学习器训练且预测输出;
42、元学习器的训练:组合三个基学习器的五折数据预测输出作为元学习器输入,结合样本集sam的标签完成最终的训练,得到滑坡易发性的评价模型。
43、所述的步骤s6,具体包括如下步骤:
44、获取目标区域的数据信息;
45、根据得到的数据信息,采用得到的训练后的滑坡易发性评价模型,对目标区域的每个栅格进行滑坡易发性预测;
46、根据每个栅格的滑坡易发性预测结果,与设定的阈值进行比较,并根据比较结果判定目标区域中每个栅格的滑坡易发性,完成待分析区域的滑坡易发性评价。
47、本发明提供的这种滑坡易发性评价方法,通过强化负样本策略得到可靠的负样本集,通过构建的滑坡易发性评价模型,提高了滑坡易发性评价结果的准确率;因此本发明的可靠性高、准确性好且客观科学。
- 还没有人留言评论。精彩留言会获得点赞!