一种识别检测盒检测结果的方法及系统与流程
本发明属于图像检测,具体涉及一种识别检测盒检测结果的方法及系统。
背景技术:
1、试剂盒为现在市场上的检测试剂的主要载体,例如新冠抗原检测试剂盒、验孕棒等试剂盒,而试剂条被固定在试剂盒内,为检测提供唯一的检测结果标识。
2、heyer公司的covid-19neutralizing ab test产品,是一款新冠病毒抗原检测的试剂盒,与市面上的其他产品不同的是,本款产品通过手机app与云端进行连接交互,从而管理使用者的抗原检测结果。
3、试剂盒上有两条线,分别是c线与t线,其中在检测结果中如果c线显示红色代表此试剂条可以正常使用,不显示颜色则表示此试剂条不可以正常使用;t线颜色的深浅代表检测结果的多样性,比如说弱阳、中等、强阳等类型。但是在实际的检测结果测试过程中,c线的颜色的值只是代表试剂条是否正常使用,现阶段无特殊具体的意义,但是t线的颜色的值,代表的是弱阳、中等、强阳具体类型的量化,covid-19病毒有很多种,例如德尔塔病毒、奥密克戎病毒等,单纯这两种病毒来说它们的毒性并不相同,德尔塔病毒毒性强,奥密克戎病毒毒性弱,具体数值的意义为毒性强的病毒的弱阳、中等、强阳等类型的阈值与毒性弱的阈值高,比如说德尔塔病毒的量化数值弱阳(0<x<59)、中等(60<x<149)、强阳(150<x<249),而奥密克戎病毒的量化数值弱阳(0<x<39)、中等(40<x<119)、强阳(120<x<249),两种不同的病毒在试剂条上同一种颜色代表的感染程度不同,尤其是在类型的阈值附近很容易产生误判。
4、heyer公司的技术方案是首先必须有一张背景卡,背景卡中有左上、右上、左下、右下四个定位二维码,通过这四个二维码做位置标定,中间的黑框中有检测盒的标准样例图片,生产出的检测盒大小与黑框一致,只有将检测盒与黑框位置吻合,才可以进行下一步的检测;
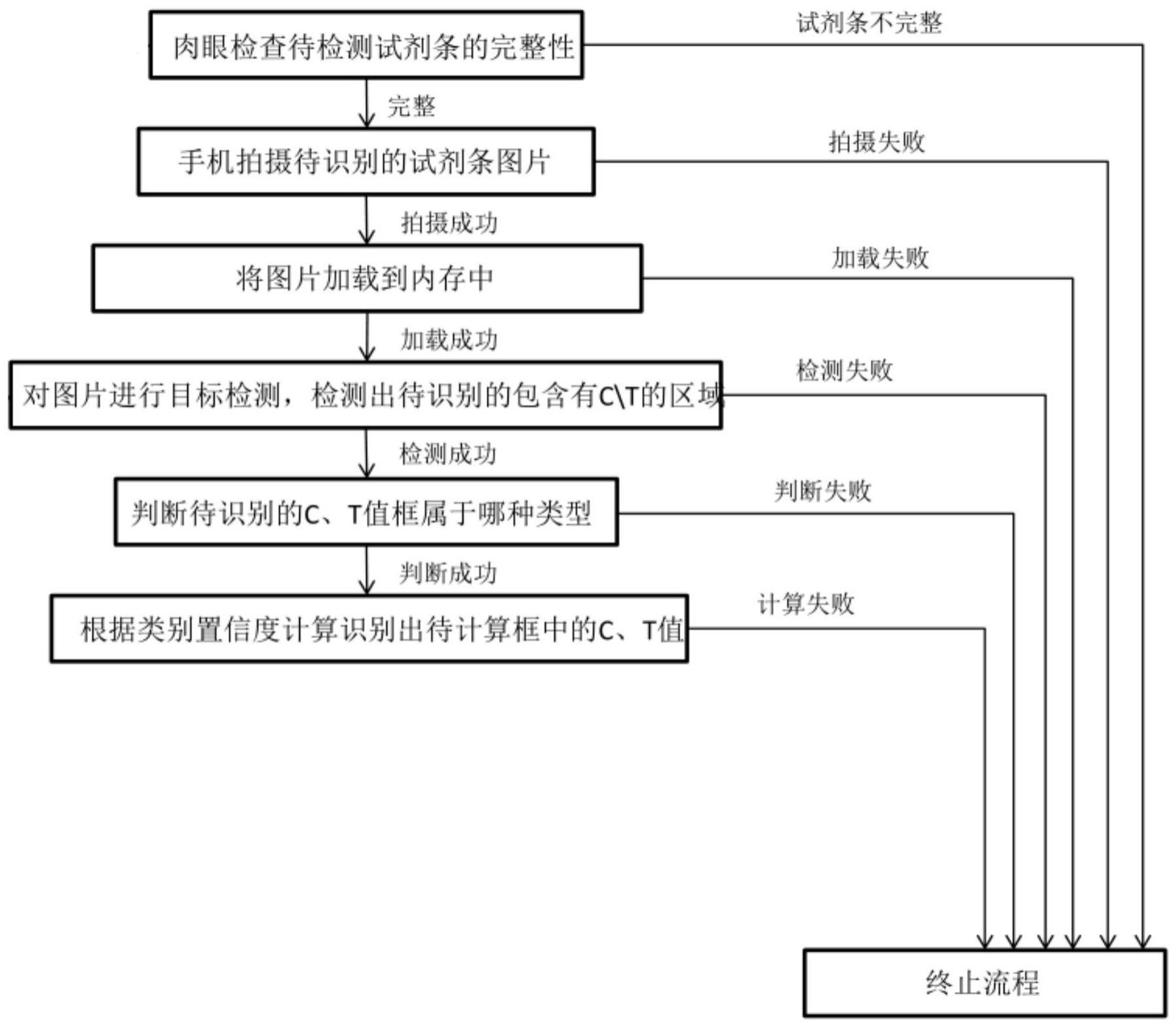
5、具体方法如下:
6、(1)将待识别的试剂条放置在四只角有定位二维码的背景卡中,将试剂条的位置与背景卡的检测盒标准样例图相对应;
7、(2)使用手机拍摄待识别的试剂条为图片,并将图片加载到内存中;
8、(3)根据预设在程序中的位置坐标,对图片中的二维码、待识别c、t值区域进行切割;
9、(4)计算出二维码的字符串值;
10、(5)根据传统的计算机视觉计算颜色值的方法(图像特征颜色矩计算),粗略计算出c、t值。
11、现有的识别技术依赖于检测试剂盒上的c线与t线的位置,相当于不可以兼容众多试剂条厂商的识别结果,因为每个厂商的试剂盒刻模有差异,c线与t线的位置有差异,所以对于其他厂商的试剂条识别不出结果。
12、现有的识别技术使用传统的计算机视觉方法,机械化的去识别c线与t线的位置,然后根据固定的方法去计算c线与t线的颜色值,这种方法会受检测环境光照、拍摄手机等外界因素的强烈影响,可能会造成结果与现实结果有较大的误差。
13、现有技术中很明显存在不能很好兼容检测众多厂商不同尺寸的试剂条的缺陷,即满足了试剂条a的检测,却不兼容试剂条b、c的检测,如果兼容的更多,需要在程序中预设更多的待切割坐标,这样对程序的鲁棒性,兼容性都有很大的困难与挑战,提高了公司的运营成本。除此之外,现有技术也只是使用传统的计算机视觉计算颜色值的方法,粗略的计算了c、t的颜色值,对于一些边界值计算的并不是很准确,这样对于用户来说,可能会在程序层面出现错误计算从而造成covid-19检测误判的情况,对公司的权威性造成一定的负面影响。
技术实现思路
1、本发明的目的在于克服现有技术只能识别一种规格的试剂盒,且必须依靠背景卡进行识别,识别出的结果不精确的缺陷。
2、为了实现上述目的,本发明提出了一种识别检测盒检测结果的方法,所述方法包括:
3、对试剂盒图片使用目标检测方法,检测出基准线和检测线所在的区域,以及该区域每种检测类型的置信度,取置信度最大的类型作为该试剂盒的检测类型;
4、根据检测类型的置信度计算试剂盒图片中的基准线和检测线的具体值;
5、所述目标检测方法为bp神经网络或卷积神经网络。
6、作为上述方法的一种改进,所述目标检测方法包括采样层和全连接层,具体步骤包括:
7、步骤b1:获得与预设输入图片大小相同的特征图;
8、步骤b2:采样层提取特征图中的待识别特征;
9、步骤b3:获得若干个预测框用于待检测目标的选择;
10、步骤b4:全连接层计算并提取预测框中的目标物信息;
11、步骤b5:计算得到预测的目标物框、目标物坐标与每种检测类型的置信度。
12、作为上述方法的一种改进,获得预测框的方法包括:
13、将图片分割为若干个n*n的网格,对其中的每个网格都预测m个位于该网格附近的矩形框,即预测框。
14、作为上述方法的一种改进,预测m个位于网格附近的矩形框具体为:
15、如果目标物在网格的左上角,则预测框取左边和上方的两个网格;
16、如果目标物在网格的右上角,则预测框取右边和上方的两个网格;
17、如果目标物在网格的左下角,则预测框取左边和下方的两个网格;
18、如果目标物在网格的右下角,则预测框取右边和下方的两个网格。
19、作为上述方法的一种改进,计算置信度公式如下:
20、
21、其中,convalue表示计算的置信度的值;numm表示检测目标周围的预测框的数量;α表示显著性水平;
22、loss(z,x,y)表示置信度损失值,计算公式如下:
23、loss(z,x,y)=-l(z,x,y)*logp(z,x,y)-(1-l(z,x,y))*log(1-p(z,x,y))
24、式中:0≤z≤3;0≤x≤width;0≤y≤height
25、其中,z表示图片的通道数;x表示预测框中心点的横坐标;y表示预测框中心点的纵坐标;width表示图片对应的宽的值;height表示图片对应的高的值;
26、l(z,x,y)表示置信度标签所对应的矩阵,即每个预测框中初始化置信度矩阵;矩阵中包含有每个预测框的通道号、横坐标、纵坐标初始化的置信度组成,此矩阵为一个一维矩阵;
27、p(z,x,y)表示需要预测的置信度矩阵;即通过神经网络计算的每个预测框中参考置信度矩阵,矩阵中包含有每个预测框的通道号、横坐标、纵坐标与预测到的参考置信度组成,此矩阵为一个一维矩阵。
28、作为上述方法的一种改进,α值优先为0.1。
29、作为上述方法的一种改进,基准线和检测线的值计算方法为:
30、cvalue=valuestart+convalue*valuerandom
31、tvalue=valuestart+abs(atan(100*convalue-50)*2/π)*(valueend-valuestart)
32、其中,cvalue表示基准线计算值;tvalue表示检测线计算值;valuestart表示在检测实践中的经验起始值;valueend表示在检测实践中的经验终止值;convalue表示通过计算得到的类别置信度值;atan()表示atan归一化处理;abs()表示取绝对值;valuerandom表示随机值,计算公式如下:
33、valuerandom=valuelow+rand()%(valuehigh-valuelow+1)
34、其中,rand()表示生成随机数的函数;valuelow表示生成随机数范围的最小值;valuehigh表示生成随机数范围的最大值。
35、本技术还提供一种识别检测盒检测结果系统,基于上述方法实现,所述系统包括:
36、目标检测模块,用于对试剂盒图片使用目标检测方法,检测出基准线和检测线所在的区域,以及该区域每种检测类型的置信度,取置信度最大的类型作为该试剂盒的检测类型;和
37、计算基准线和检测线模块,用于根据检测类型的置信度计算试剂盒图片中的基准线和检测线的具体值。
38、与现有技术相比,本发明的优势在于:
39、1、本发明不需要背景卡的配合即可进行检测,使用目标检测的方法识别出待识别区域,包括待识别的二维码、c线与t线的检测框,然后将这些识别框切割下来。这种识别方法不会依赖于厂商检测盒的刻模位置,可以识别出检测盒中任意位置的c线与t线;
40、2、本发明使用检测置信度来计算现有c线与t线的颜色值,这样在经验值与检测值中间通过一个合理的计算参数得出的颜色值,使c线与t线的值更加准确客观,对于检测结果有极强的参考意义;
41、3、本发明使用人工智能,目标检测与分类的方法获得待要识别的c线与t线的目标位置,使识别结果更加客观准确。
- 还没有人留言评论。精彩留言会获得点赞!