一种平行语料数据对的构建方法、装置及存储介质与流程
本技术涉及自然语言处理,更具体的说,涉及一种平行语料数据对的构建方法、装置及存储介质。
背景技术:
1、在如今互联网蓬勃发展的时代,人与人之间的信息交互愈发频繁。无论是口头交谈或是文字表述,语言作为人类交流沟通的表达方式,是具有情境性的。不同的时间、特定的地点与场景,每个话语通常传达着表述者的性格特征、状态或者意图等。如,当人们质疑答案的正确性时,常会发出疑问“结果真是这样的吗?”,而非发表“没错,确实是这样。”这一类的肯定言论。在相对正式场合时,应注重表述的规范性,对比“请坐。”与“过来,坐。”,前者相对礼貌、正式,后者则更为随意。因此,平白直叙并不是单一形式,个性化的需求使得让机器能够理解、实现语言背后的风格迁移这一能力显得尤为重要。
2、风格迁移是在尽可能保留主要内容的基础上,通过编辑风格相关词语或者将文本改写以生成另一种风格的文本。目前的研究思路是,利用平行语料数据对对预训练语言模型进行有监督训练,进而利用训练得到的模型将待处理文本处理为不同风格的文本。其中,平行语料数据对是指带有属性风格a的句子,以及与之配对的带有另一个属性风格a′的句子。如,一个句子的风格为积极的,“这家餐厅的味道真不错。”,那么与之配对的另一个消极风格的句子为“这家餐厅的味道真差劲。”。但是,由于平行语料数据对的稀缺性,导致上述的思路难以落地实施。
技术实现思路
1、有鉴于此,本技术实施例公开一种平行语料数据对的构建方法、装置及存储介质,实现平行语料数据对的构建,解决平行语料数据对稀缺的问题。
2、本技术实施例提供的技术方案如下:
3、第一方面,本技术实施例提供了一种平行语料数据对的构建方法,所述方法包括:
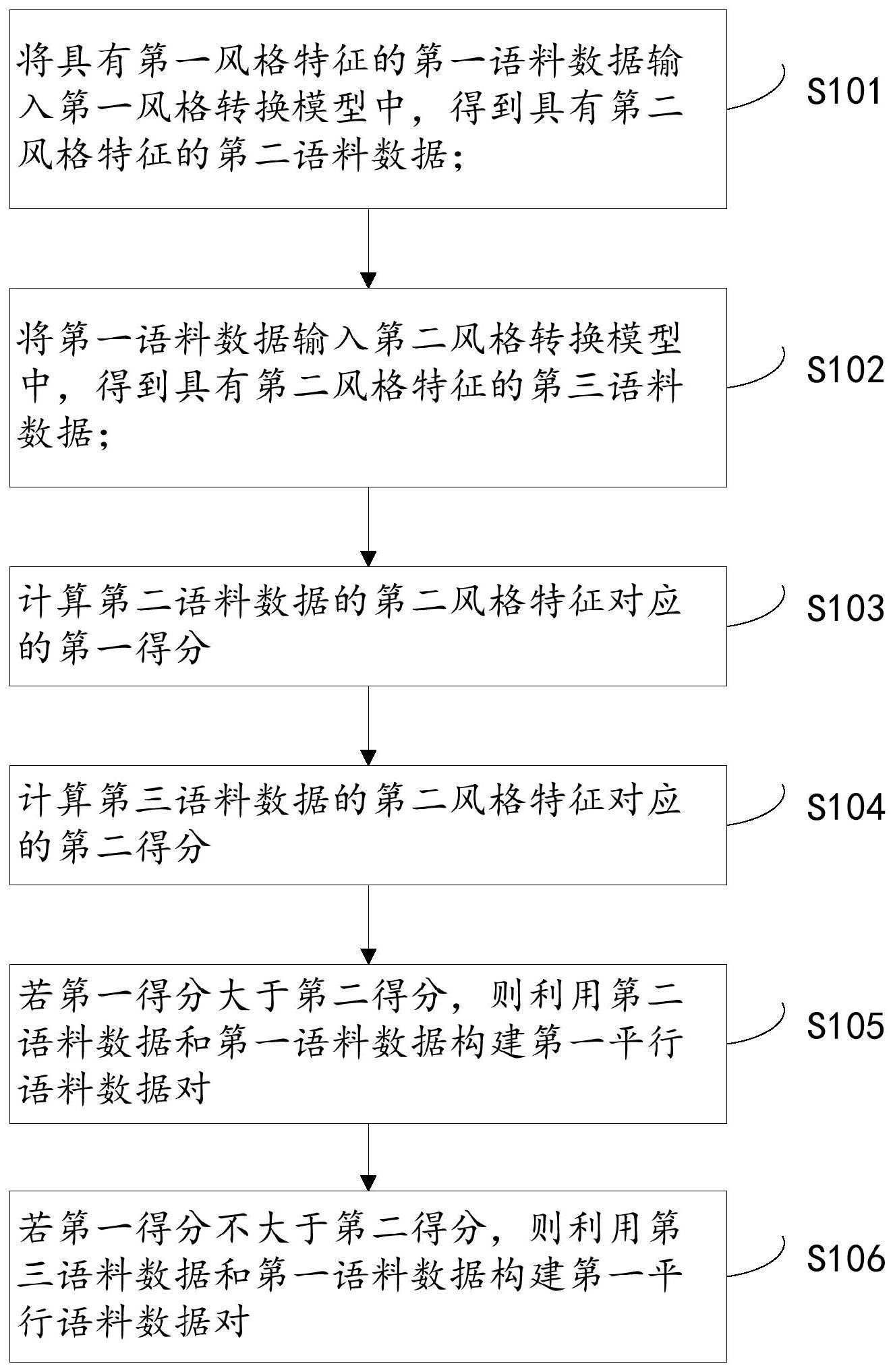
4、将具有第一风格特征的第一语料数据输入第一风格转换模型中,得到具有第二风格特征的第二语料数据;所述第一风格转换模型基于回译训练得到;
5、将所述第一语料数据输入第二风格转换模型中,得到具有所述第二风格特征的第三语料数据;所述第二风格转换模型基于对抗训练得到;
6、计算所述第二语料数据的第二风格特征对应的第一得分;
7、计算所述第三语料数据的第二风格特征对应的第二得分;
8、若所述第一得分大于所述第二得分,则利用所述第二语料数据和所述第一语料数据构建第一平行语料数据对;
9、若所述第一得分不大于所述第二得分,则利用所述第三语料数据和所述第一语料数据构建第一平行语料数据对。
10、结合上述第一方面,在一种可能的实现方式中,所述方法还包括:
11、利用所述第一平行语料数据对对第一预训练语言模型进行有监督微调,得到第二预训练语言模型;所述第一平行语料数据对包括:所述第一语料数据、第一语料数据对应的平行语料数据,所述第一语料数据对应的平行语料数据为所述第二语料数据或所述第三语料数据;
12、将所述第一语料数据输入所述第二预训练语言模型中,得到具有所述第二风格特征的第一输出结果;
13、计算所述第一输出结果和所述第一语料数据对应的平行语料数据之间的第一变化幅度值;
14、若所述第一变化幅度值大于预设阈值,则利用所述第一输出结果替换所述第一语料数据对应的平行语料数据,得到更新后的第一平行语料数据对。
15、结合上述第一方面,在一种可能的实现方式中,所述计算所述第一输出结果和所述第一语料数据对应的平行语料数据之间的第一变化幅度值,包括:
16、计算所述第一语料数据与所述第一输出结果之间的第一双语互译质量评估bleu值;
17、计算所述第一语料数据与所述第一语料数据对应的平行语料数据之间的第二bleu值;
18、计算所述第一输出结果的第二风格特征对应的第三得分;
19、当所述第一语料数据对应的平行语料数据为所述第二语料数据时,利用所述第一得分、所述第一bleu值、所述第二bleu值和所述第三得分,计算得到所述第一变化幅度值;或者,
20、当所述第一语料数据对应的平行语料数据为所述第三语料数据时,利用所述第二得分、所述第一bleu值、所述第二bleu值和所述第三得分,计算得到所述第一变化幅度值。
21、结合上述第一方面,在一种可能的实现方式中,所述方法还包括:
22、通过多次循环计算过程对所述更新后的第一平行语料数据对进行更新,得到构建成功的第一平行语料数据对;
23、其中,所述多次循环计算过程中当前的循环计算过程,包括:
24、利用前一次的循环计算过程中的更新后的第一平行语料数据对对所述第一预训练语言模型进行有监督微调,得到第三预训练语言模型;
25、将所述第一语料数据输入所述第三预训练语言模型中,得到具有第二风格特征的第二输出结果;
26、计算所述第二输出结果和当前的循环计算过程中的所述第一语料数据对应的平行语料数据之间的第二变化幅度值;
27、若所述第二变化幅度值大于所述预设阈值,则利用所述第二输出结果替换当前的循环计算过程中的所述第一语料数据对应的平行语料数据,得到当前的循环计算过程中的更新后的第一平行语料数据对,并返回执行如下步骤:利用前一次的循环计算过程中的更新后的第一平行语料数据对对所述第一预训练语言模型进行有监督微调,得到第三预训练语言模型,直至当前的循环计算过程中的第三预训练语言模型的迁移准确率和前一次的循环计算过程中的第三预训练语言模型的迁移准确率的差值不大于预设值,得到构建成功的第一平行语料数据对。
28、结合上述第一方面,在一种可能的实现方式中,所述计算所述第二输出结果和当前的循环计算过程中的所述第一语料数据对应的平行语料数据之间的第二变化幅度值,包括:
29、计算所述第一语料数据与所述第二输出结果之间的第三bleu值;
30、计算所述第一语料数据与当前的循环计算过程中的所述第一语料数据对应的平行语料数据之间的第四bleu值;
31、计算所述第二输出结果的第二风格特征对应的第四得分;
32、计算当前的循环计算过程中的所述第一语料数据对应的平行语料数据的第二风格特征对应的第五得分;
33、利用所述第三bleu值、所述第四bleu值、所述第四得分和所述第五得分,计算得到所述第二变化幅度值。
34、结合上述第一方面,在一种可能的实现方式中,所述方法还包括:
35、将具有所述第二风格特征的第四语料数据输入所述第一风格转换模型中,得到具有所述第一风格特征的第五语料数据;
36、将所述第四语料数据输入所述第二风格转换模型中,得到具有所述第一风格特征的第六语料数据;
37、计算所述第五语料数据的第一风格特征对应的第六得分;
38、计算所述第六语料数据的第一风格特征对应的第七得分;
39、若所述第六得分大于所述第七得分,则利用所述第五语料数据和所述第四语料数据构建第二平行语料数据对;
40、若第六得分不大于所述第七得分,则利用所述第六语料数据和所述第四语料数据构建第二平行语料数据对。
41、结合上述第一方面,在一种可能的实现方式中,所述第一风格转换模型包括第一翻译模型、第二翻译模型、第一风格解码器、第二风格解码器和第一属性分类器,所述方法还包括:
42、通过如下训练过程训练所述第一风格解码器:
43、将具有所述第一风格特征的第一训练文本输入所述第一翻译模型中,得到具有所述第一风格特征的第一翻译文本;
44、将所述第一翻译文本输入所述第二翻译模型的编码器中,得到无风格特征的第一隐向量;
45、将所述第一隐向量输入所述第一风格解码器中,得到具有所述第一风格特征的第一回译文本;
46、将所述第一回译文本输入所述第一属性分类器中,得到第一分类结果;
47、利用所述第一分类结果训练所述第一风格解码器;
48、通过如下训练过程训练所述第二风格解码器:
49、将具有所述第二风格特征的第二训练文本输入所述第一翻译模型中,得到具有所述第二风格特征的第二翻译文本;
50、将所述第二翻译文本输入所述第二翻译模型的编码器中,得到无风格特征的第二隐向量;
51、将所述第二隐向量输入所述第二风格解码器中,得到具有所述第二风格特征的第二回译文本;
52、将所述第二回译文本输入所述第一属性分类器中,得到第二分类结果;
53、利用所述第二分类结果训练所述第二风格解码器。
54、结合上述第一方面,在一种可能的实现方式中,所述第二风格转换模型包括第一风格生成器、第二风格生成器和第二属性分类器,所述方法还包括:
55、通过如下训练过程训练所述第一风格生成器和所述第二风格生成器:
56、对具有所述第一风格特征的第一训练文本进行加噪处理,得到第一加噪文本;
57、将所述第一加噪文本输入所述第一风格生成器中进行数据重构,得到具有所述第一风格特征的第一重构文本;
58、计算所述第一重构文本与所述第一训练文本之间的交叉熵损失值,得到第一损失值;
59、将所述第一重构文本输入所述第二属性分类器中,得到第三分类结果;
60、将所述第一训练文本输入所述第二风格生成器中进行数据重构,得到具有所述第二风格特征的第二重构文本;
61、对所述第二重构文本进行加噪处理,得到第二加噪文本;
62、将所述第二加噪文本输入所述第一风格生成器中进行数据重构,得到具有所述第一风格特征的第三重构文本;
63、计算所述第三重构文本与所述第一训练文本之间的交叉熵损失值,得到第二损失值;
64、将所述第三重构文本输入所述第二属性分类器中,得到第四分类结果;
65、对具有所述第二风格特征的第二训练文本进行加噪处理,得到第三加噪文本;
66、将所述第三加噪文本输入所述第二风格生成器中进行数据重构,得到具有所述第二风格特征的第四重构文本;
67、计算所述第四重构文本与所述第二训练文本之间的交叉熵损失值,得到第三损失值;
68、将所述第四重构文本输入所述第二属性分类器中,得到第五分类结果;
69、将第二训练文本输入所述第一风格生成器中进行数据重构,得到具有第一风格特征的第五重构文本;
70、对所述第五重构文本进行加噪处理,得到第四加噪文本;
71、将所述第四加噪文本输入所述第二风格生成器中进行数据重构,得到具有所述第二风格特征的第六重构文本;
72、计算所述第六重构文本与所述第二训练文本之间的交叉熵损失值,得到第四损失值;
73、将所述第六重构文本输入所述第二属性分类器中,得到第六分类结果;
74、利用所述第一损失值、所述第二损失值、所述第三损失值、所述第四损失值、所述第三分类结果、所述第四分类结果、所述第五分类结果和所述第六分类结果训练所述第一风格生成器和所述第二风格生成器。
75、第二方面,本技术实施例提供了一种平行语料数据对的构建装置,所述装置包括:
76、风格转换单元,用于将具有第一风格特征的第一语料数据输入第一风格转换模型中,得到具有第二风格特征的第二语料数据;所述第一风格转换模型基于回译训练得到;
77、所述风格转换单元,还用于将所述第一语料数据输入第二风格转换模型中,得到具有所述第二风格特征的第三语料数据;所述第二风格转换模型基于对抗训练得到;
78、风格得分计算单元,用于计算所述第二语料数据的第二风格特征对应的第一得分;
79、所述风格得分计算单元,还用于计算所述第三语料数据的第二风格特征对应的第二得分;
80、构建单元,用于若所述第一得分大于所述第二得分,则利用所述第二语料数据和所述第一语料数据构建第一平行语料数据对;
81、所述构建单元,还用于若所述第一得分不大于所述第二得分,则利用所述第三语料数据和所述第一语料数据构建第一平行语料数据对。
82、第三方面,本技术实施例提供了一种平行语料数据对的构建装置,包括:
83、存储器,用于存储指令;
84、处理器,用于执行所述存储器中的所述指令以执行以上第一方面任一项所述的平行语料数据对的构建方法。
85、第四方面,本技术实施例提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当所述指令在终端设备上运行时,使得所述终端设备执行以上第一方面任一项所述的平行语料数据对的构建方法。
86、第五方面,本技术实施例提供一种计算机程序产品,所述计算机程序产品在终端设备上运行时,使得所述终端设备执行以上第一方面任一项所述的平行语料数据对的构建方法。
87、基于上述技术方案,本技术具有以下有益效果:
88、本技术实施例公开了一种平行语料数据对的构建方法、装置及存储介质。其中,该方法包括:将具有第一风格特征的第一语料数据输入第一风格转换模型中,得到具有第二风格特征的第二语料数据;第一风格转换模型基于回译训练得到;将第一语料数据输入第二风格转换模型中,得到具有第二风格特征的第三语料数据;第二风格转换模型基于对抗训练得到;计算第二语料数据的第二风格特征对应的第一得分;计算第三语料数据的第二风格特征对应的第二得分;若第一得分大于第二得分,则利用第二语料数据和第一语料数据构建第一平行语料数据对;若第一得分不大于第二得分,则利用第三语料数据和第一语料数据构建第一平行语料数据对。可见,本技术实施例中通过回译、对抗这两种不同训练方式训练得到的模型,得到不同的风格转换后的语料数据,丰富了平行语料数据对的构建方式,解决平行语料数据对稀缺的问题。而且,会对风格转换后的语料数据进行风格得分计算,并基于风格得分进行筛选,如此能构建出优质的第一平行语料数据对,提高平行语料数据对的质量。
- 还没有人留言评论。精彩留言会获得点赞!