反事实预测和效果评估方法、系统
本发明涉及事件预测,更为具体地,涉及一种反事实预测和效果评估方法、系统。
背景技术:
1、反事实预测技术作为因果推断的重要组成部分之一,近年来受到了越来越多的关注。反事实预测通过使用已有的观察性数据,模拟对个体被施加不同干扰后产生的效果,已经在推荐、医药、广告等多个领域取得了广泛应用,具有重要的实践意义。
2、传统的反事实预测方法主要依靠已知的结构因果模型(structural causalmodel,scm),根据已知的数据反推出模型中的其他噪声变量,再通过指定干扰项得到最终的反事实预测结果,但这种方法需要提前获得准确的因果结构。同时,如果数据规模过大或特征之间存在非线性关系,都有可能对预测结果的准确性产生影响。在进行特征之间的因果发现时,最常用的基于条件独立关系的方法会产生大量等价类,导致无法确定真实的因果结构,该方法还忽略了会对干扰项和结果都产生影响的混淆因子,这些都会影响反事实预测结果的准确性。
3、此外,由于观察性数据是已经发生的事实,个体不可能同时接受多种干预,所以无法根据观察数据验证反事实预测结果的准确性,现有的反事实预测方法大多需要依靠模拟数据或人工核验,具有高昂的执行成本和一定的实施难度。
4、因此,亟需一种避免传统方法可能产生的等价类问题,减少了混淆因子对结果准确性的影响,提高模型对于高维度数据和非线性关系的处理能力,提高应用价值的反事实预测和效果评估方法、系统。
技术实现思路
1、鉴于上述问题,本发明的目的是提供一种反事实预测和效果评估方法、系统,以解决现有技术会产生大量等价类,导致无法确定真实的因果结构,忽略会对干扰项和结果都产生影响的混淆因子,影响反事实预测结果的准确性的问题。
2、本发明提供的一种反事实预测和效果评估方法,包括:
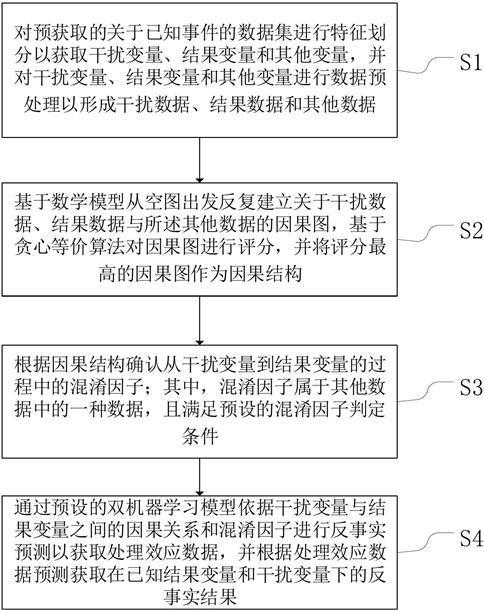
3、对预获取的关于已知事件的数据集进行特征划分以获取干扰变量、结果变量和其他变量,并对所述干扰变量、所述结果变量和所述其他变量进行数据预处理以形成干扰数据、结果数据和其他数据;
4、基于数学模型从空图出发反复建立关于所述干扰数据、所述结果数据与所述其他数据的因果图,基于贪心等价算法对所述因果图进行评分,并将所述评分最高的因果图作为因果结构;
5、根据所述因果结构确认从干扰变量到结果变量的过程中的混淆因子;其中,所述混淆因子属于所述其他数据中的一种数据,且满足预设的混淆因子判定条件;
6、通过预设的双机器学习模型依据所述干扰变量与所述结果变量之间的因果关系和所述混淆因子进行反事实预测以获取处理效应数据,并根据所述处理效应数据预测获取在已知所述结果变量和所述干扰变量下的反事实结果。
7、优选地,在获取所述反事实结果之后,还包括对所述反事实结果进行评估的步骤;其中包括;
8、通过预设的倾向算法对预获取的数据集总体中任意个体计算倾向得分,并根据所述倾向得分,在倾向得分距离小于预设阈值的情况下匹配干扰项不同的个体分别作为实验组和控制组;
9、计算相对应的实验组倾向得分和控制组倾向得分的第一误差范围,并通过所述双机器学习模型计算所述实验组在具有所述控制组的干扰变量时所产生的实验反事实结果;
10、计算所述实验反事实结果和所述实验组的真实结果的第二误差范围;
11、若所述第二误差范围小于所述第一误差范围,则所述实验反事实结果预测有效。
12、优选地,所述通过预设的倾向算法对预获取的数据集总体中任意个体计算倾向得分,包括:
13、对预获取的数据集总体中任意个体进行数据处理以提取关于所述个体的干扰项、输出结果、反事实预测结果,参与所述干扰项、所述输出结果所产生的因果关系的其他特征集合,以及对所述输出结果产生假性干扰的混淆因子集合;
14、通过预设的倾向得分计算公式根据所述混淆因子集合计算所述数据集总体中某一类个体的倾向得分。
15、优选地,所述根据所述倾向得分,在倾向得分距离小于预设阈值的情况下匹配干扰项不同的个体分别作为实验组和控制组,包括:
16、在所述数据集总体中随机抽取一组个体数据作为实验组;
17、在所述数据集总体中获取预设数量的与所述实验组具有不同干扰项,且倾向得分相近的个体作为控制组;
18、基于卡尺匹配原则对所述控制组进行筛选,以保留所述控制组中倾向得分距离小于预设阈值的个体,剔除倾向得分距离大于预设阈值的个体。
19、优选地,所述倾向得分距离为所述控制组中各个个体的倾向得分与所述实验组中各个个体的倾向得分的差值;所述预设阈值为预先根据所述控制组中各个个体的倾向得分与所述实验组中各个个体的倾向得分计算的匹配容忍度。
20、优选地,所述混淆因子判定条件为:
21、在所述因果结构的图解中将所述其他数据中的某一数据所对应的节点作为混淆因子时,需同时满足:
22、所述混淆因子没有所述干扰变量的后代节点,且阻断所述干扰变量与所述结果变量之间的伪路径;
23、所述混淆因子不会打破所述干扰变量与所述结果变量之间的路径;
24、不会由于所述混淆因子产生新的伪路径。
25、优选地,所述依据所述干扰变量与所述结果变量之间的因果关系和所述混淆因子进行反事实预测以获取处理效应数据,包括:
26、将预获取的样本数据划分为第一子样本和第二子样本;将所述结果变量划分为第一结果变量和第二结果变量;
27、在所述第一子样本上以所述混淆因子为条件,采用随机森林方法用所述干扰变量拟合所述第一结果变量以获取初级第一结果函数,并计算所述第二子样本上的所述第一结果变量与所述初级第一结果函数的初级第一残差;在所述第一子样本上以所述混淆因子为条件,采用随机森林方法用所述干扰变量拟合所述第二结果变量以获取初级第二结果函数,并计算所述初级第二结果函数和所述第二结果变量的初级第二残差;并对所述初级第一残差和所述初级第二残差进行回归拟合以获取拟合后的初级斜率系数;
28、在所述第二子样本上以所述混淆因子为条件,采用随机森林方法用所述干扰变量拟合所述第一结果变量以获取二级第一结果函数,并计算所述第一子样本上的所述第一结果变量与所述二级第一结果函数的二级第一残差;在所述第二子样本上以所述混淆因子为条件,采用随机森林方法用所述干扰变量拟合所述第二结果变量以获取二级第二结果函数,并计算所述二级第二结果函数和所述第二结果变量的二级第二残差;并对所述二级第一残差和所述二级第二残差进行回归拟合以获取拟合后的二级斜率系数;
29、对所述初级斜率系数和所述二级斜率系数求取均值,并将所述均值作为处理效应数据。
30、优选地,已知干扰变量下的反事实结果为已知的与所述干扰变量对应的结果变量加所述处理效应数据。
31、本发明还提供一种反事实预测和效果评估系统,实现如前所述的反事实预测和效果评估方法,包括:
32、数据处理模块,用于对预获取的关于已知事件的数据集进行特征划分以获取干扰变量、结果变量和其他变量,并对所述干扰变量、所述结果变量和所述其他变量进行数据预处理以形成干扰数据、结果数据和其他数据;
33、因果结构确认模块,用于基于数学模型从空图出发反复建立关于所述干扰数据、所述结果数据与所述其他数据的因果图,基于贪心等价算法对所述因果图进行评分,并将所述评分最高的因果图作为因果结构;
34、混淆因子判定模块,用于根据所述因果结构确认从干扰变量到结果变量的过程中的混淆因子;其中,所述混淆因子属于所述其他数据中的一种数据,且满足预设的混淆因子判定条件;
35、反事实预测模块,用于通过预设的双机器学习模型依据所述干扰变量与所述结果变量之间的因果关系和所述混淆因子进行反事实预测以获取处理效应数据,并根据所述处理效应数据预测获取在已知所述结果变量和所述干扰变量下的反事实结果。
36、优选地,还包括反事实结果评估模块;其中,所述反事实结果评估模块用于:
37、通过预设的倾向算法对预获取的数据集总体中任意个体计算倾向得分,并根据所述倾向得分,在倾向得分距离小于预设阈值的情况下匹配干扰项不同的个体分别作为实验组和控制组;
38、计算相对应的实验组倾向得分和控制组倾向得分的第一误差范围,并通过所述双机器学习模型计算所述实验组在具有所述控制组的干扰变量时所产生的实验反事实结果;
39、计算所述实验反事实结果和所述实验组的真实结果的第二误差范围;
40、若所述第二误差范围小于所述第一误差范围,则所述实验反事实结果预测有效。
41、从上面的技术方案可知,本发明提供的反事实预测和效果评估方法,通过贪心等价算法获取因果结构,避免了传统方法可能产生的等价类问题,同时减少了混淆因子对结果准确性的影响;使用双重机器学习模型进行反事实预测,提高模型对于高维度数据和非线性关系的处理能力,最后使用倾向得分匹配,从原始数据集中构建了实验组和控制组,通过对比倾向得分误差和预测-真实值误差范围,为因果推断结果的验证提供了参考,提高整体的应用价值。
- 还没有人留言评论。精彩留言会获得点赞!