一种复杂场景小目标的数据处理检测方法及数据训练方法
本发明涉及计算机视觉领域,尤其涉及一种复杂场景小目标的数据处理检测方法及数据训练方法。
背景技术:
1、目标检测是计算机视觉领域的重要问题之一,它可以应用于诸如自动驾驶、安防监控、人脸识别等领域。
2、复杂场景下的小目标检测场景通常包括,大场景,大场景中存在大量的目标和背景,小目标很容易被淹没在大量的背景中,难以被有效地检测出来;遮挡场景,小目标容易被遮挡,例如人群中的行人、车流中的摩托车、森林中的小动物等,往往会被周围的物体或者植被所遮挡,导致检测结果不准确;多变光照场景,光照条件的不断变化,往往会导致小目标的外观发生变化,例如在日落时分拍摄的人像和在正午时分拍摄的人像,往往具有明显的差异。
3、传统的目标检测方法通常采用滑动窗口和金字塔等方式对图像进行多次扫描,再使用分类器对每个窗口进行分类。但是,对于小目标来说,由于其尺寸较小,存在多种问题,如低分辨率、模糊和严重的遮挡等问题,这些问题使得传统的目标检测方法在小目标检测上的效果很难得到保证。
4、而深度学习技术的兴起为小目标检测带来了新的机遇,深度学习技术通过神经网络的训练,可以从大量数据中学习到特征,进而提高目标检测的准确率和速度。在小目标检测中,研究者们提出了一系列基于深度学习的方法,如faster r-cnn、yolo、ssd等,这些方法在一定程度上解决了小目标检测的问题。
5、但是,由于小目标的尺寸和特征与背景的差异较小,这些方法仍然存在一些限制,例如检测精度不高、漏检率高等问题。
6、这个时候建立良好的复杂场景小目标的数据处理检测方法,再结合复杂场景下的小目标数据集和yolov5网络,根据自身经验建立的多个训练模型,一方面提高复杂场景下小目标检测的准确率和效率,另一方面当训练完毕后,生成的神经网络模型还可以做到面对新的数据集或实时图像,检测出其中的人、自行车、轿车、面包车、卡车、三轮车、公共汽车和摩托车,依然可以保持良好的小目标检测准确率以及效率,对自动驾驶、安防监控、智能家居等行业都非常有意义。
技术实现思路
1、本发明的目的是为了提供一种复杂场景小目标的数据处理检测方法及数据训练方法。
2、本发明所要解决的问题是:
3、提出一种复杂场景小目标的数据处理检测方法结合数据训练方法,加强网络对小目标的敏感度,获得更多小目标初始特征和位置信息,最后结合yolov5网络和注意力机制进行模型训练,当模型训练完毕后,模型可以做到面对人、自行车、轿车、面包车、卡车、三轮车、公共汽车和摩托车等目标,依然可以保持良好的检测效率和检测质量。
4、一种复杂场景小目标的数据处理检测方法及数据训练方法采用的技术方案如下:
5、一种复杂场景小目标的数据处理检测方法,包括以下步骤:
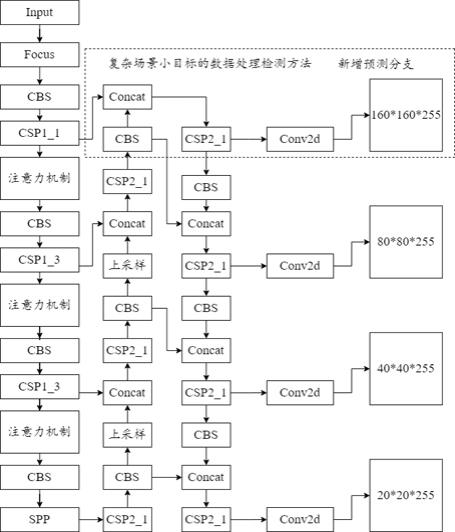
6、s31:结合特征金字塔网络和路径聚合网络的思想,在yolov5网络结构中csp2_1结构层的80×80预测特征层的基础上,加入与原网络相同的1×1卷积层和上采样层,将原yolov5的neck网络的特征层再进行一次上采样,将其分辨率由80×80扩大到160×160,以获取小目标更为浅层的初始信息;
7、s32:将扩展后的高分辨率特征图与主干网络浅层特征进行特征融合,得到具备大量语义信息和位置信息的特征层,主干网络上的浅层特征图尺寸大小为160×160,而在进行特征增强时,需要保持融合的两个特征图具有相同的分辨率,后续对应增加一个尺寸为160×160的预测分支,并且由于添加的预测分支是由浅层具有更高分辨率的特征信息生成的,含有更多的小目标初始特征和位置信息,因此对小目标更加敏感;
8、s33:将融合后的特征层输入到卷积层中进行下采样,其中卷积核为3,步距为2,最后将其与原本卷积层输出结果进行融合。
9、一种数据训练方法,包括以下步骤:
10、s41:数据准备,需准备复杂场景下小目标图像数据集,其中存在大量小目标,小目标种类有:人、自行车、轿车、面包车、卡车、三轮车、公共汽车和摩托车,训练及使用前根据卷积网络的要求,将图片统一大小,以保证后续计算顺利进行;
11、s42:数据增强,为了提高训练出来的模型性能以及模型的泛化能力,在进行训练之前对图像进行数据翻转和mosaic处理;
12、s43:将上述的一种复杂场景小目标的数据处理检测方法与yolov5相结合,并结合注意力机制,建立最终检测网络,训练模型,模型训练在进行梯度下降的过程中,初始学习率设置为0.01,并通过"one-cycle policy"学习率调整策略和"autoselect"学习率自适应选择策略来动态改变和选择学习率,降低损失,以提高准确率;
13、s44:使用二元交叉熵损失函数用于对象损失,计算公式为:
14、,其中表示所有格子即像素点的个数,表示预测的第i个格子中第j 个边界框是否包含目标,b表示每个格子预测的边界框数量,是一个指示函数,当格子i中第j个边界框包含目标时为1,否则为 0,则表示当格子i中第j个边界框不包含目标时为 1,否则为 0;
15、使用二元交叉熵损失函数用于类别损失,计算公式为:,其中表示预测的第i个格子中第j个边界框属于第c个类别的概率,是一个指示函数,当边界框属于第c个类别时为 1,否则为0;
16、使用均方误差损失用于边界框坐标损失,计算公式为:,其中、分别表示第i个格子中第j个边界框的预测中心的横坐标、预测中心的纵坐标、宽度和高度,、、、分别表示第i个格子中第j个边界框的真实中心的横坐标、真实中心的纵坐标、宽度和高度,t用于表示具体位置的x、y、w、h四个参数,用于计算指定位置各参数的均方差,是一个超参数,用于平衡边界框坐标损失和其他损失的权重;
17、使用giou损失函数计算预测框与真实框之间的重叠程度,计算公式为:、,其中是一个包含预测框和真实框的最小闭合区域的面积,表示第i个格子中第j个边界框的真实坐标,表示预测的坐标,表示预测坐标与真实坐标的交集与并集的比值,用于预测的边界框与真实边界框之间的,是广义交并比;
18、s45:yolov5网络在后处理阶段使用非极大值抑制来处理网络输出的边界框;
19、s46:模型训练,训练每一个epoch都包括了前向传播和后向传播,并且不断迭代,在迭代后期,学习率降低频率增快,损失逐渐降低,准确率缓慢增加;
20、其中上述步骤s42中的mosaic数据增强是利用了四张图片,对四张图片进行拼接,每一张图片都有其对应的框,将四张图片拼接之后就获得一张新的图片,同时也获得这张图片对应的框,然后将这样一张新的图片传入到神经网络当中去学习,相当于直接传入四张图片进行学习,丰富了检测物体的背景。
21、其中上述步骤s43中的"one-cycle policy"学习率调整策略是一种基于学习率随时间变化的周期函数的训练方法,能够在训练过程中自适应地调整学习率,以提高训练效率和准确性,这种策略可以帮助模型更快地收敛,并且具有一定的泛化性能,而"autoselect"学习率自适应选择策略可以自动选择最优的学习率,并调整学习率的变化率和初始值以适应数据集和模型的不同。
22、其中上述步骤s45中在yolov5网络的前向传播过程中,网络输出一个包含多个边界框的预测结果。每个边界框包含了预测的物体类别、位置以及置信度等信息,在非极大值抑制的处理过程中,首先对于同一类别的边界框,根据它们的置信度排序,选择置信度最高的边界框作为最终的预测结果。然后,对于其余边界框,计算它们与最终预测结果的(intersection over union,交并比)值,若值大于一定阈值,则将其删除。这个过程将不断迭代,直到所有的边界框都被处理完毕。
23、其中上述步骤s46中的前向传播的目的是通过反复调整网络参数,使得输出结果逐渐接近标签数据,从而提高模型的预测准确率,在训练过程的前向传播阶段,由于网络参数是随机初始化的,输出结果很可能与标签数据存在较大差距,因此需要通过反向传播来调整网络参数,从而优化网络模型的性能。
24、本发明的有益效果:复杂场景下的小目标检测的大量聚集和严重的遮挡等特点带来的检测精度不高、漏检率高、低分辨率、模糊的问题可以通过复杂场景小目标的数据处理检测方法中增加的更多小目标初始特征、位置信息的预测分支及特征的融合,以及注意力机制进一步缓解。具体来说,通过训练复杂场景下的小目标检测模型(包括卷积神经网络架构、注意力机制以及复杂场景小目标的数据处理检测方法),可以把复杂场景下的的小目标以较高的效率和准确率检测出来,这些目标包括人、自行车、轿车、面包车、卡车、三轮车、公共汽车和摩托车。
25、对比来说,在训练过程中,针对同样的训练模型,常规的算法,常规的神经架构,过于依赖训练工程师的经验,需要有经验的训练工程师手动调节参数,训练效率不高。
26、如果采用其他经典架构,训练的准确度大致分布在10%-30%,即使训练数千个epoch,都很难达到50%的准确度。
- 还没有人留言评论。精彩留言会获得点赞!