一种相似数据对象候选对快速生成方法
本发明涉及大数据处理领域,尤其涉及一种相似数据对象候选对快速生成方法。
背景技术:
1、在大数据时代,企业、政府和各类机构的信息系统所承载的数据量快速增长,数据来源也日益多元化。为了能更高效的从大数据中提炼价值,数据清洗和整合能力对大数据信息系统不可或缺。实体解析任务在数据整合中承担了重要的一环,其目的是在单个数据源内以及多个数据源之间,识别出指向同一现实世界实体(例如用户、产品等)的数据对象。实体解析任务需要对数据源中的数据对象进行两两匹配,往往会产生极高的计算量,所需的时间过长,因此需要通过前置的相似数据对象候选对筛选,来减少实体解析任务消耗的时间。目前的相似候选对筛选技术主要有基于学习和基于非学习两类,其中基于学习的方法往往需要预标注的数据集进行训练,且模型难以在不同结构的数据源中迁移;基于非学习的方法往往直接将单词或文本的切片作为筛选候选对的标准,忽略其本身包含的信息量,容易产生较多冗余的相似候选对。
技术实现思路
1、有鉴于现有技术的上述缺陷,本发明所要解决的技术问题是现有的相似数据对象候选对筛选需要预标注数据集且进行训练,并且模型难以在不同结构的数据源中迁移,或容易产生较多冗余的相似候选对。因此,本发明提供了一种相似数据对象候选对快速生成方法,基于局部敏感哈希和无向图的相似数据对象候选对快速生成方法,实现从多个结构化数据源中快速生成相似数据对象候选对的功能,不依赖标注数据进行训练,根据值的特性对字段分类,使用局部敏感哈希提取数据对象的相似性特征,并考虑不同相似性特征间信息含量的差异,使相似性度量更为准确,并使用修剪无向图的方式,使产生的相似数据对象候选对有更精简的规模和更高的质量,有助于提高后续匹配任务的效率。
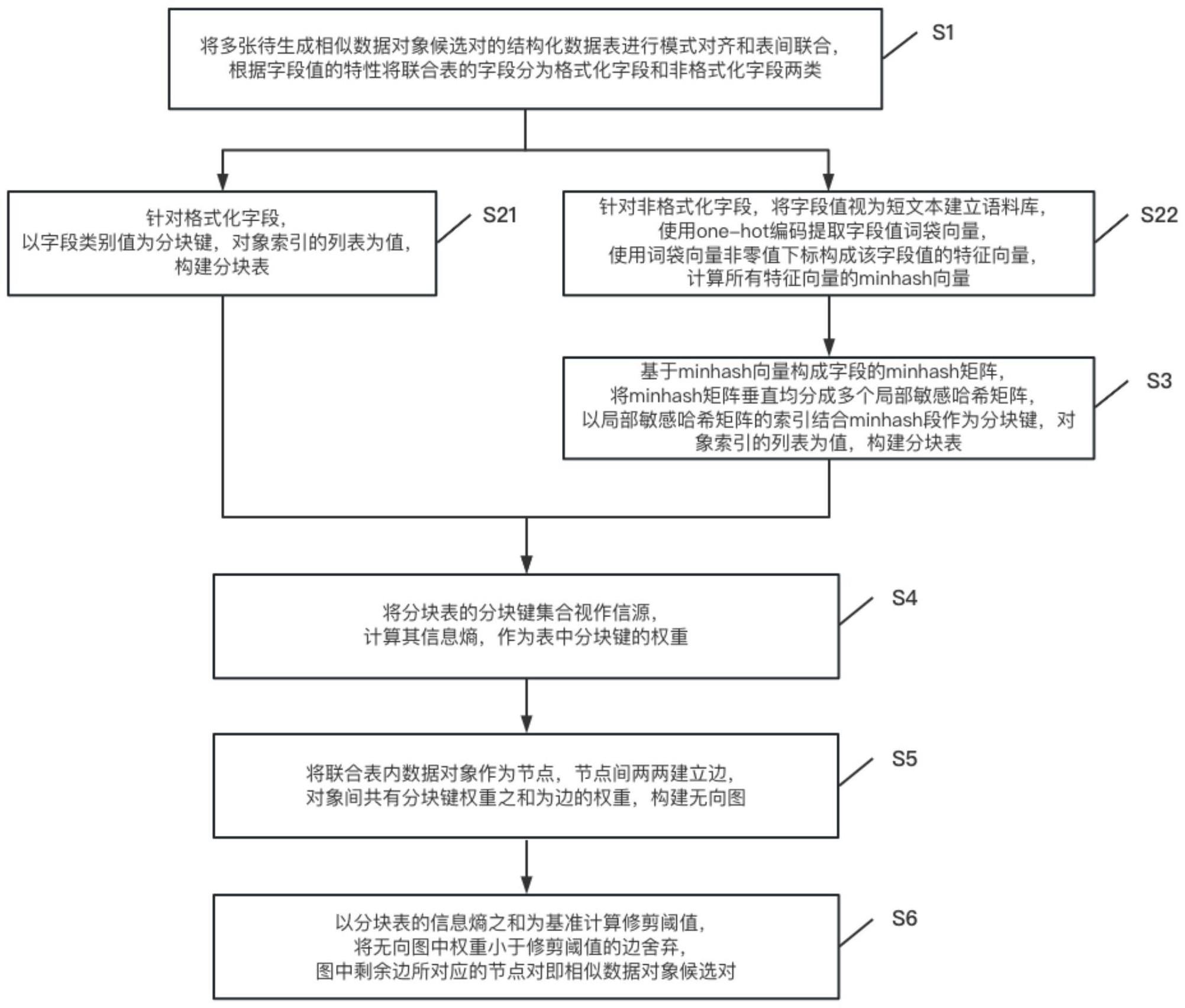
2、为实现上述目的,本发明提供了一种相似数据对象候选对快速生成方法,包括以下步骤:
3、s1、将多张待生成相似数据对象候选对的结构化数据表进行模式对齐和表间联合,根据字段值的特性将联合表的字段分为格式化字段和非格式化字段两类;
4、s2、分别针对格式化字段和非格式化字段进行处理,分别得到格式化字段下的分块表和非格式化字段下的所有特征向量的minhash向量;
5、s3、基于minhash向量构成字段的minhash矩阵并纵向均分成多个局部敏感哈希矩阵,以局部敏感哈希矩阵的索引和minhash段作为分块键,对象索引的列表为值,构建分块表;
6、s4、将分块表中分块键集合视作信源,计算其信息熵,作为分块键的权重;
7、s5、遍历所有分块表,以分块键对应列表内的对象为节点,对象间共现分块键权重之和为边的权重,构建无向图;
8、s6、以所有分块表信息熵之和为基准计算修剪阈值,修剪无向图的边,图中剩余边所对应的节点对即相似数据对象候选对。
9、进一步地,将多张待生成相似数据对象候选对的结构化数据表进行模式对齐和表间联合,根据字段值的特性将联合表的字段分为格式化字段和非格式化字段两类,具体包括:
10、模式对齐设置为根据多张结构化数据表的字段信息,筛选出含义相同的表间共有字段,对每一张结构化数据表,仅保留共有字段和该表主键;
11、表间联合设置为对多张数据表进行垂直方向的联合,原表的主键列合并成一个新列。为联合表添加主键,代表表中数据对象的索引;
12、将表中字段划分为两类,值遵循统一格式且类别值较少的字段为格式化字段,值无固定格式且差异度较高的字段为非格式化字段。
13、进一步地,分别针对格式化字段和非格式化字段进行处理,分别得到格式化字段下的分块表和非格式化字段下的所有特征向量的minhash向量,具体包括:
14、s21、针对格式化字段,以字段值的类别值为分块键,对象索引的列表为值,构建分块表;
15、s22、针对非格式化字段,将字段值视为短文本构建语料库,使用one-hot编码提取字段值词袋向量,用词袋向量非零值下标构成该字段值的特征向量,计算所有特征向量的minhash向量。
16、进一步地,s22、针对非格式化字段,将字段值视为短文本构建语料库,使用one-hot编码提取字段值词袋向量,用词袋向量非零值下标构成该字段值的特征向量,计算所有特征向量的minhash向量,具体包括:对于每一个非格式化字段,将字段值视作短文本,字段值集合构成一个语料库,去除标点符号、特殊字符和停用词之后提取关键词词典,并使用one-hot编码表示每一个关键词,使用关键词one-hot向量之和表示字段值的词袋向量,提取字段值词袋向量中非零元素的下标,构成字段值的特征向量;
17、使用如下公式计算minhash的参数:
18、其中,k代表一个局部敏感哈希段的长度,pj代表两个字段值词袋最低的jaccard相似度,pt代表两个字段值在相似度为pj时,至少共有一个局部敏感哈希段的期望概率。在给定k、pt、pj之后,可计算出l,代表局部敏感哈希段的总数;
19、选定一个随机种子s,使用梅森旋转法生成两个长度为l*k伪随机序列α、β,其中α的值域为[1,p),β的值域为[0,p),p为一个较大的梅森素数;将α、β转换成列向量;
20、对于一个特征向量f,将β水平扩展成列数为|f|的矩阵b,其中|f|代表特征向量的长度;使用如下全域散列函数对特征向量进行l*k次散列:
21、
22、其中mhash(f)为特征向量f的全域散列矩阵,对mhash(f)的每一行取最小值,构成特征向量f的minhash向量。
23、进一步地,s21、针对格式化字段,以字段值的类别值为分块键,对象索引的列表为值,构建分块表,具体包括,对于联合表的每一个格式化字段,遍历字段值并提取不重复的类别值,以类别值为键,类别值对应的对象索引构成的列表为值,构建哈希表,称为分块表;表中的键称为分块键。
24、进一步地,s3、基于minhash向量构成字段的minhash矩阵并纵向均分成多个局部敏感哈希矩阵,以局部敏感哈希矩阵的索引和minhash段作为分块键,对象索引的列表为值,构建分块表,具体包括:
25、对于一个非结构化字段,使用s22方法计算其每个值的minhash向量并按行构成该字段的minhash矩阵;将minhash矩阵纵向均分成l个n*k的局部敏感哈希矩阵,每一行为一个minhash段,其中n代表联合表的总行数;
26、遍历一个局部敏感哈希矩阵的minhash段,提取出无重复的类别值,使用该矩阵的索引和类别值作为分块键,对应的对象索引构成的列表为值,构建分块表。
27、进一步地,s4、将分块表中分块键集合视作信源,计算其信息熵,作为分块键的权重,具体包括:
28、对于每一个分块表,使用如下公式计算其信息熵:
29、
30、其中,|bt|代表分块表中所有分块键对应的数据对象总数,|bt(ki)|代表分块键ki对应数据对象总数,m为分块表的分块键总数;使用信息熵作为表内分块键的权重。
31、进一步地,s5、遍历所有分块表,以分块键对应列表内的对象为节点,对象间共现分块键权重之和为边的权重,构建无向图,具体包括:
32、将联合表中的每一个数据对象作为节点,为节点间两两构建边,边的权重为两个数据对象在所有分块表中共有的分块键权重之和,将权重为零的边和度为零的节点去除,得到一张无向图。
33、进一步地,s6、以所有分块表信息熵之和为基准计算修剪阈值,修剪无向图的边,图中剩余边所对应的节点对即相似数据对象候选对,具体包括:
34、对于s4中产生的分块表信息熵求和,得到最大相似度smax,选取一个系数c,计算修剪阈值sp=c×smax;
35、将s5中产生的无向图中所有权重小于sp的边全部去除,所剩余的边对应的节点对即为相似数据对象候选对。
36、技术效果
37、本发明提供的一种相似数据对象候选对快速生成方法,实现从多个结构化数据源中快速生成相似数据对象候选对的功能,不依赖标注数据进行训练,根据值的特性对字段分类,使用局部敏感哈希提取数据对象的相似性特征,并考虑不同相似性特征间信息含量的差异,使相似性度量更为准确,并使用修剪无向图的方式,使产生的相似数据对象候选对有更精简的规模和更高的质量,有助于提高后续匹配任务的效率。
38、以下将结合附图对本发明的构思、具体结构及产生的技术效果作进一步说明,以充分地了解本发明的目的、特征和效果。
- 还没有人留言评论。精彩留言会获得点赞!