一种联邦学习模型训练方法及系统与流程
本技术涉及计算机,具体而言,涉及一种联邦学习模型训练方法及系统。
背景技术:
1、目前,随着人工智能技术的飞速发展,人工智能技术的应用越来越广泛,已经被应用于图像分析、语音识别、文字处理、智能推荐、安全检测等多个领域,以联邦学习为代表的隐私计算技术已经成为新的前沿技术热点领域。但是传统的联邦学习技术在面对超大规模数据、数据非独立同分布和极度分散的大量节点等场景时,全局模型训练过程将陷入代价高、训练慢、难收敛、性能差等困境。
技术实现思路
1、本技术实施例的目的在于提供一种联邦学习模型训练方法及系统,能够提高全局模型的训练速度和收敛速度,优化全局模型的性能表现。
2、本技术实施例第一方面提供了一种联邦学习模型训练方法,应用于联邦学习模型训练系统,所述联邦学习模型训练系统包括集中式节点和多个分布式节点,所述方法包括:
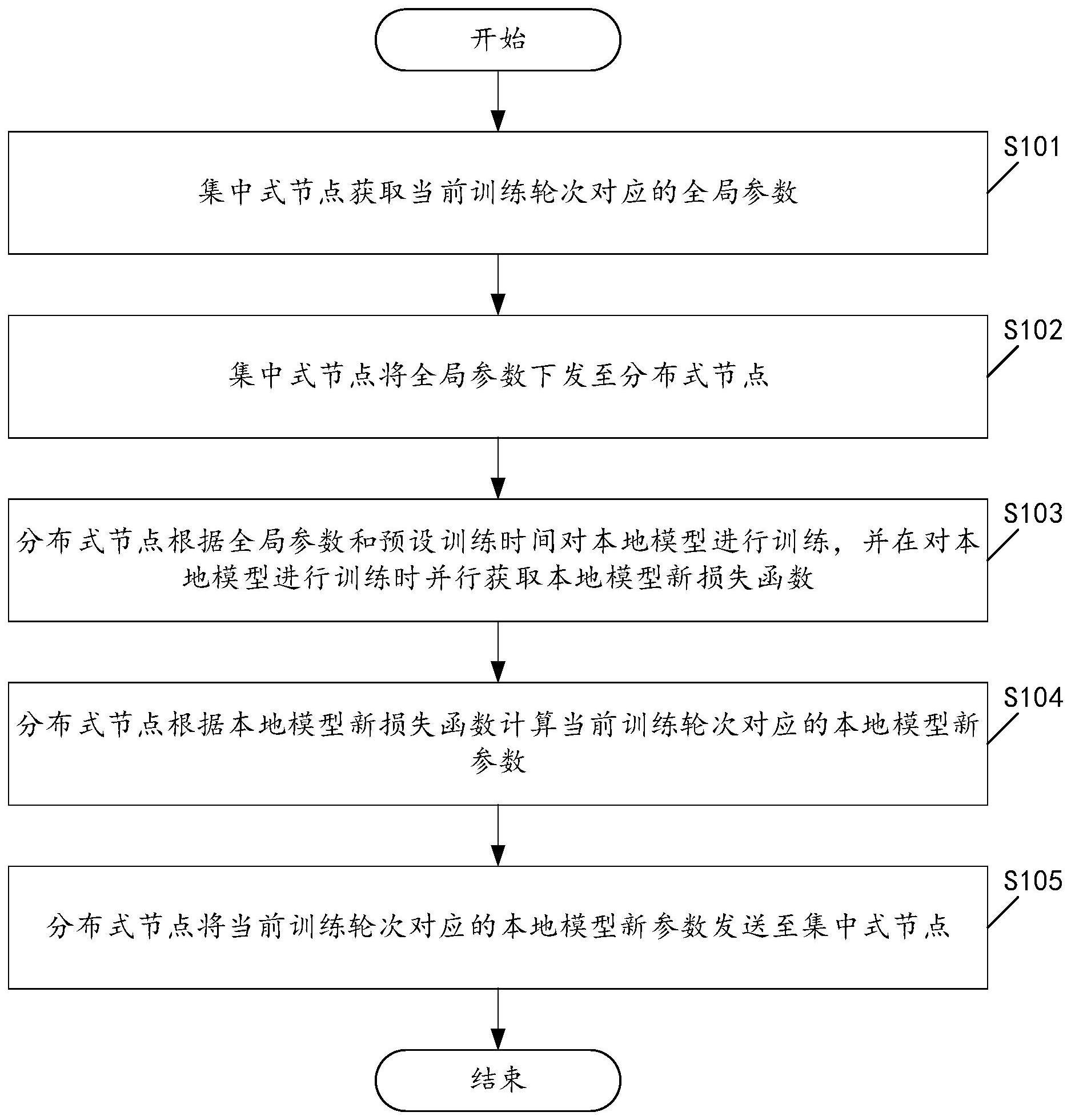
3、所述集中式节点获取当前训练轮次对应的全局参数;
4、所述集中式节点将所述全局参数下发至所述分布式节点;
5、所述分布式节点根据所述全局参数和预设训练时间对本地模型进行训练,并在对所述本地模型进行训练时并行获取本地模型新损失函数;
6、所述分布式节点根据所述本地模型新损失函数计算所述当前训练轮次对应的本地模型新参数;
7、所述分布式节点将所述当前训练轮次对应的本地模型新参数发送至所述集中式节点。
8、在上述实现过程中,集中式节点可以先获取当前训练轮次对应的全局参数,并在获取到全局参数时下发全局参数至分布式节点;可见,该方法可以基于联邦学习的方式将全局参数下发给指定的分布式节点,以使分布式节点可以进行相应的模型训练。具体的,分布式节点在接收到全局参数时,可以根据全局参数和预设训练时间对本地模型进行训练,并在对本地模型进行训练时并行获取本地模型的新损失函数;可见,该方法可以在传统l2正则化技术的基础上,改进模型训练的目标函数,从而以此来解决以往模型训练速度慢、收敛速度慢以及收敛性能差的技术问题。然后,分布式节点可以根据本地模型新损失函数计算当前训练轮次对应的本地模型新参数,并将本地模型新参数发送至集中式节点,以使该方法完成半同步联邦学习模型的训练过程,从而以此来提高大规模节点和数据下联邦学习模型的训练速度,并提高大规模节点的计算资源利用率。
9、进一步地,所述集中式节点获取当前训练轮次对应的全局参数的步骤,包括:
10、所述集中式节点在当前训练轮次为第一个训练轮次时,获取所采用的深度神经网络模型的模型参数;
11、所述集中式节点对所述模型参数进行初始化,得到当前训练轮次对应的全局参数。
12、在上述实现过程中,集中式节点在获取当前训练轮次的全局参数的过程中,可以先判断是否为首次训练,从而以此来确定是否需要进行全局参数的初始化。其中,在当前训练轮次是第一次时,该方法可以获取深度神经网络模型的模型参数,并采用预设的高斯随机初始化算法对模型参数进行初始化,得到当前训练轮次的全局参数。
13、进一步地,所述集中式节点获取当前训练轮次对应的全局参数的步骤,包括:
14、所述集中式节点在当前训练轮次不为第一个训练轮次时,获取上一个训练轮次对应的本地模型新参数;
15、所述集中式节点根据所述上一个训练轮次对应的本地模型新参数进行计算,得到当前训练轮次对应的全局参数。
16、在上述实现过程中,集中式节点还可以在判断出此次训练并非首次训练时,获取上一个训练轮次对应的本地模型新参数,并基于上一个训练轮次对应的本地模型新参数进行计算,得到当前训练轮次对应的全局参数。
17、进一步地,所述集中式节点将所述全局参数下发至所述分布式节点的步骤,包括:
18、所述集中式节点在当前训练轮次为第一个训练轮次时,将所述当前训练轮次对应的全局参数下发至所述分布式节点;或者,在所述当前训练轮次不为所述第一个训练轮次时,将所述当前训练轮次对应的全局参数和所述当前训练轮次对应的更新动量下发至所述分布式节点。
19、在上述实现过程中,集中式节点可以基于当前训练轮次是否为第一个训练轮次来确定需要下发的参数,并根据确定出来的结果完成对应参数的下发。
20、进一步地,所述分布式节点在对所述本地模型进行训练时并行获取本地模型新损失函数,包括:
21、所述分布式节点在所述当前训练轮次为第一个训练轮次时,在对所述本地模型进行训练时并行获取本地模型参数向量和本地模型原损失函数;
22、所述分布式节点根据所述当前训练轮次对应的全局参数和所述本地模型参数向量计算损失函数惩罚项;
23、所述分布式节点根据所述损失函数惩罚项和本地模型原损失函数计算本地模型新损失函数。
24、进一步地,所述分布式节点在对所述本地模型进行训练时并行获取本地模型新损失函数,包括:
25、所述分布式节点在所述当前训练轮次不为第一个训练轮次时,在对所述本地模型进行训练时并行获取本地模型参数向量和本地模型原损失函数;
26、所述分布式节点根据所述当前训练轮次对应的全局参数、所述当前训练轮次对应的更新动量、所述本地模型参数向量、所述当前训练轮次计算损失函数惩罚项;
27、所述分布式节点根据所述损失函数惩罚项和本地模型原损失函数计算本地模型新损失函数。
28、在上述实现过程中,该方法给出了分布式节点在不同的训练轮次中获取本地模型新损失函数的方法,从而使得该方法可以应用于任何训练轮次当中。
29、进一步地,所述分布式节点将所述当前训练轮次对应的本地模型新参数发送至所述集中式节点之后,所述方法还包括:
30、所述集中式节点在所述当前训练轮次为第一个训练轮次时,根据所述当前训练轮次对应的本地模型新参数进行计算,得到下一个训练轮次对应的全局参数;
31、所述集中式节点根据所述当前训练轮次对应的全局参数和所述下一个训练轮次对应的全局参数进行计算,得到下一个训练轮次对应的更新动量。
32、进一步地,所述分布式节点将所述当前训练轮次对应的本地模型新参数发送至所述集中式节点之后,所述方法还包括:
33、所述集中式节点在所述当前训练轮次不为第一个训练轮次时,根据所述当前训练轮次对应的本地模型新参数进行计算,得到下一个训练轮次对应的全局参数;
34、所述集中式节点根据所述当前训练轮次对应的全局参数、所述下一个训练轮次对应的全局参数和所述当前训练轮次对应的更新动量进行计算,得到下一个训练轮次对应的更新动量。
35、在上述实现过程中,该方法给出了集中式节点在不同的训练轮次中计算更新动量的方法,从而使得该方法可以应用于任何训练轮次当中。
36、进一步地,所述方法还包括:
37、所述集中式节点根据所述下一个训练轮次对应的全局参数和所述当前训练轮次判断是否结束训练过程;
38、所述集中式节点在所述训练过程未结束时,迭代训练轮次并执行所述获取当前训练轮次对应的全局参数的步骤。
39、在上述实现过程中,该方法可以在未停止训练的时候,按照轮次进行迭代,直到获取到最合适的联邦学习模型为止。
40、本技术实施例第二方面提供了一种联邦学习模型训练系统,所述联邦学习模型训练系统包括集中式节点和多个分布式节点,其中,
41、所述集中式节点,用于获取当前训练轮次对应的全局参数;
42、所述集中式节点,还用于将所述全局参数下发至所述分布式节点;
43、所述分布式节点,用于根据所述全局参数和预设训练时间对本地模型进行训练,并在对所述本地模型进行训练时并行获取本地模型新损失函数;
44、所述分布式节点,还用于根据所述本地模型新损失函数计算所述当前训练轮次对应的本地模型新参数;
45、所述分布式节点,还用于将所述当前训练轮次对应的本地模型新参数发送至所述集中式节点。
46、进一步地,所述集中式节点,具体用于在当前训练轮次为第一个训练轮次时,获取所采用的深度神经网络模型的模型参数;
47、所述集中式节点,具体还用于对所述模型参数进行初始化,得到当前训练轮次对应的全局参数。
48、进一步地,所述集中式节点,具体用于在当前训练轮次不为第一个训练轮次时,获取上一个训练轮次对应的本地模型新参数;
49、所述集中式节点,具体还用于根据所述上一个训练轮次对应的本地模型新参数进行计算,得到当前训练轮次对应的全局参数。
50、进一步地,所述集中式节点,具体用于在当前训练轮次为第一个训练轮次时,将所述当前训练轮次对应的全局参数下发至所述分布式节点;或者,在所述当前训练轮次不为所述第一个训练轮次时,将所述当前训练轮次对应的全局参数和所述当前训练轮次对应的更新动量下发至所述分布式节点。
51、进一步地,所述分布式节点,具体用于在所述当前训练轮次为第一个训练轮次时,在对所述本地模型进行训练时并行获取本地模型参数向量和本地模型原损失函数;
52、所述分布式节点,具体还用于根据所述当前训练轮次对应的全局参数和所述本地模型参数向量计算损失函数惩罚项;
53、所述分布式节点,具体还用于根据所述损失函数惩罚项和本地模型原损失函数计算本地模型新损失函数。
54、进一步地,所述分布式节点,具体用于在所述当前训练轮次不为第一个训练轮次时,在对所述本地模型进行训练时并行获取本地模型参数向量和本地模型原损失函数;
55、所述分布式节点,具体还用于根据所述当前训练轮次对应的全局参数、所述当前训练轮次对应的更新动量、所述本地模型参数向量、所述当前训练轮次计算损失函数惩罚项;
56、所述分布式节点,具体还用于根据所述损失函数惩罚项和本地模型原损失函数计算本地模型新损失函数。
57、进一步地,所述集中式节点,还用于在所述当前训练轮次为第一个训练轮次时,根据所述当前训练轮次对应的本地模型新参数进行计算,得到下一个训练轮次对应的全局参数;
58、所述集中式节点,还用于根据所述当前训练轮次对应的全局参数和所述下一个训练轮次对应的全局参数进行计算,得到下一个训练轮次对应的更新动量。
59、进一步地,所述集中式节点,还用于在所述当前训练轮次不为第一个训练轮次时,根据所述当前训练轮次对应的本地模型新参数进行计算,得到下一个训练轮次对应的全局参数;
60、所述集中式节点,还用于根据所述当前训练轮次对应的全局参数、所述下一个训练轮次对应的全局参数和所述当前训练轮次对应的更新动量进行计算,得到下一个训练轮次对应的更新动量。
61、进一步地,所述集中式节点,还用于根据所述下一个训练轮次对应的全局参数和所述当前训练轮次判断是否结束训练过程;
62、所述集中式节点,还用于在所述训练过程未结束时,迭代训练轮次并执行所述获取当前训练轮次对应的全局参数的步骤。
63、本技术实施例第三方面提供了一种电子设备,包括存储器以及处理器,所述存储器用于存储计算机程序,所述处理器运行所述计算机程序以使所述电子设备执行本技术实施例第一方面中任一项所述的联邦学习模型训练方法。
64、本技术实施例第四方面提供了一种计算机可读存储介质,其存储有计算机程序指令,所述计算机程序指令被一处理器读取并运行时,执行本技术实施例第一方面中任一项所述的联邦学习模型训练方法。
- 还没有人留言评论。精彩留言会获得点赞!