电子病历的文本关系提取方法、装置、设备及介质与流程
本技术适用于人工智能,尤其涉及一种电子病历的文本关系提取方法、装置、设备及介质。
背景技术:
1、目前,电子病历(electronic medical records,emr)产生于患者在医疗机构就诊的过程中,因此,每天都会有大量的电子病历数据产生。由于电子病历中包含着大量的医学知识以及病人的健康资料,通过研究和挖掘电子病历,能够快速准确地获取与病人有关的医疗信息,这种信息可以帮助医疗专业人员尽快了解患者的疾病状态,能够用于建立医学决策支持系统以及个性化卫生服务平台。文本信息提取主要包含命名实体提取以及实体间关系的提取,在电子病历中,医疗信息提取是指自动识别电子病历文件中的医疗信息,各种命名实体以及实体之间的关系,同时,电子病历中的医疗实体识别和实体关系提取是医疗信息提取工作中的重点任务。
2、与开放领域的文本相比,电子病历并不是完全结构化的数据,包含了许多自由文本等复杂的无结构数据,这对科学研究和统计分析造成了巨大障碍。其中,电子病历还包含了大量的生僻词和字、错别字、半结构化的内容组织方式、简略且模式化较强的语言表达,同时,由于医生的书写习惯和专业知识的原因,对于同一内容,不同医生的文本描述存在明显差异,有时甚至存在书写错误。这些特点使命名实体识别和实体关系提取任务成为挑战。另外,由于电子病历语言具有专业性强的特点,在语料构建工作中造成了巨大的障碍。当前大部分电子病历信息提取模型使用循环神经网络,虽然循环网络可以很好的处理序列数据,但是不能像图卷积神经网络那样处理局部区域附近的信息,因而整体的提取性能较差。因此,如何提取电子病历中文本的完整关系,以提高关系提取的准确性成为亟待解决的问题。
技术实现思路
1、有鉴于此,本技术实施例提供了一种电子病历的文本关系提取方法、装置、设备及介质,以解决如何提取电子病历中文本的完整关系,以提高关系提取的准确性的问题。
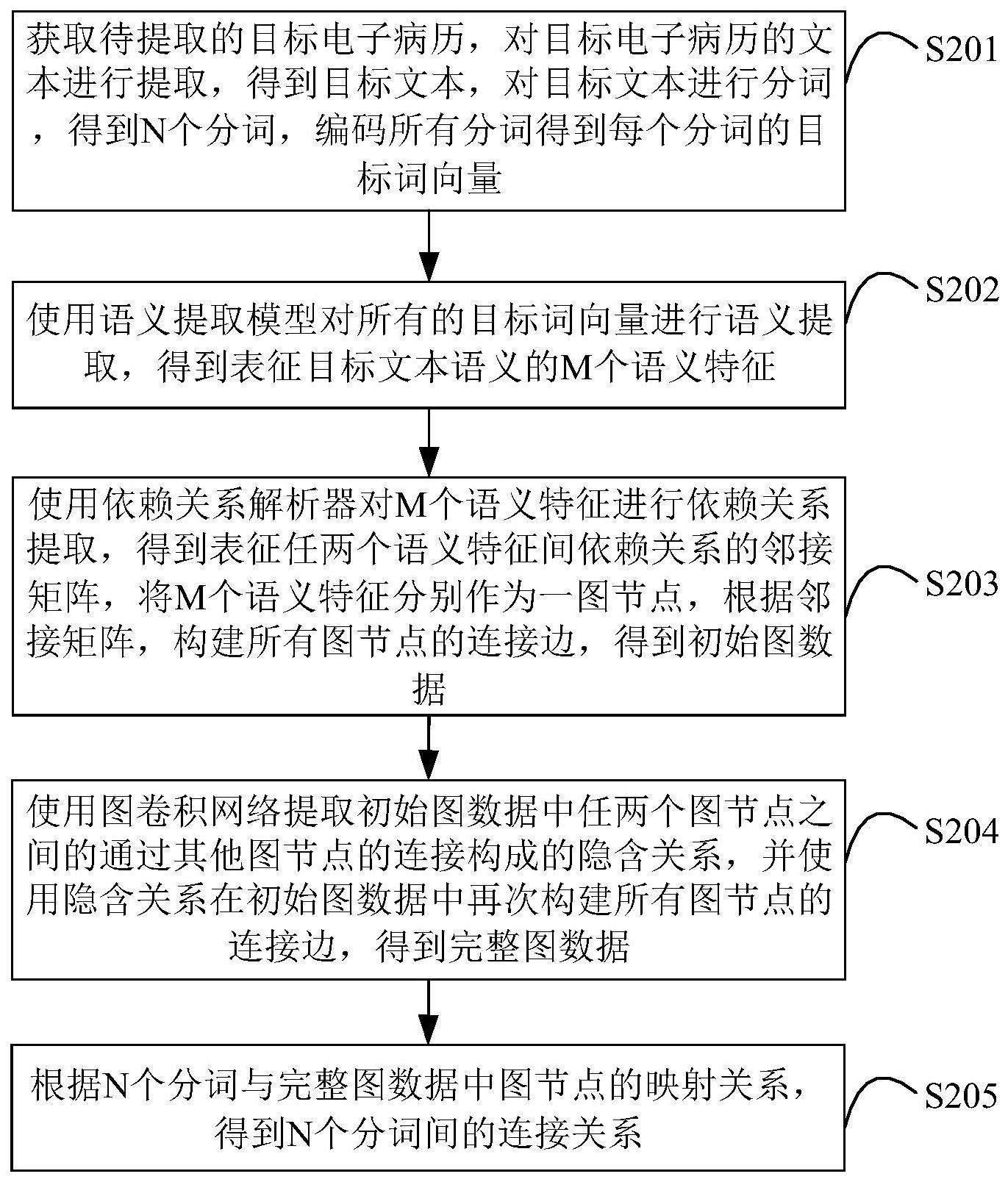
2、第一方面,本技术实施例提供一种电子病历的文本关系提取方法,所述文本关系提取方法包括:
3、获取待提取的目标电子病历,对所述目标电子病历的文本进行提取,得到目标文本,对所述目标文本进行分词,得到n个分词,编码所有分词得到每个分词的目标词向量,n为大于零的整数;
4、使用语义提取模型对所有的目标词向量进行语义提取,得到表征所述目标文本语义的m个语义特征,m为大于零的整数;
5、使用依赖关系解析器对所述m个语义特征进行依赖关系提取,得到表征任两个语义特征间依赖关系的邻接矩阵,将所述m个语义特征分别作为一图节点,根据所述邻接矩阵,构建所有图节点的连接边,得到初始图数据;
6、使用图卷积网络提取所述初始图数据中任两个图节点之间的通过其他图节点的连接构成的隐含关系,并使用所述隐含关系在所述初始图数据中再次构建所有图节点的连接边,得到完整图数据;
7、根据所述n个分词与所述完整图数据中图节点的映射关系,得到所述n个分词间的连接关系。
8、在一实施方式中,编码所有分词得到每个分词的目标词向量包括:
9、识别所述n个分词的词性;
10、针对任一分词,将所述分词及其词性进行向量编码,得到每个分词的目标词向量。
11、在一实施方式中,将所述分词及其词性进行向量编码包括:
12、将所述分词的词性标注在所述分词上,得到标注后的分词;
13、使用word2vec对所述标注后的分词进行向量化,得到所述分词的目标词向量。
14、在一实施方式中,根据所述邻接矩阵,构建所有图节点的连接边,得到初始图数据包括:
15、根据所述邻接矩阵,构建所有图节点的连接边;
16、根据所有图节点的连接边的长度和方向,预测任两个图节点之间的关系得分以及预测出对应关系得分的得分概率;
17、将所述关系得分和所述得分概率作为节点信息存入对应的两个图节点中,得到包含所述节点信息和所有图节点的连接边的初始图数据。
18、在一实施方式中,使用图卷积网络提取所述初始图数据中任两个图节点之间的通过其他图节点的连接构成的隐含关系包括:
19、使用图卷积网络提取所述初始图数据中任两个通过其他图节点连接的图节点;
20、根据所述其他图节点的节点信息和所述任两个图节点的节点信息,预测所述任两个图节点的关系得分和得分概率;
21、若所述任两个图节点的关系得分大于得分阈值且任两个图节点的得分概率大于概率阈值,则确定所述任两个图节点之间具备隐含关系。
22、在一实施方式中,在根据所述n个分词与所述完整图数据中图节点的映射关系,得到所述n个分词间的连接关系之后,还包括:
23、基于所述n个分词间的连接关系,对文本生成模型进行训练,得到训练好的文本生成模型;
24、获取待生成文本的至少一个关键词;
25、将所述至少一个关键词输入所述训练好的文本生成模型,输出对应的生成文本。
26、第二方面,本技术实施例提供一种电子病历的文本关系提取装置,所述文本关系提取装置包括:
27、编码模块,用于获取待提取的目标电子病历,对所述目标电子病历的文本进行提取,得到目标文本,对所述目标文本进行分词,得到n个分词,编码所有分词得到每个分词的目标词向量,n为大于零的整数;
28、语义提取模块,用于使用语义提取模型对所有的目标词向量进行语义提取,得到表征所述目标文本语义的m个语义特征,m为大于零的整数;
29、初始图构建模块,用于使用依赖关系解析器对所述m个语义特征进行依赖关系提取,得到表征任两个语义特征间依赖关系的邻接矩阵,将所述m个语义特征分别作为一图节点,根据所述邻接矩阵,构建所有图节点的连接边,得到初始图数据;
30、完整图构建模块,用于使用图卷积网络提取所述初始图数据中任两个图节点之间的通过其他图节点的连接构成的隐含关系,并使用所述隐含关系在所述初始图数据中再次构建所有图节点的连接边,得到完整图数据;
31、关系提取模块,用于根据所述n个分词与所述完整图数据中图节点的映射关系,得到所述n个分词间的连接关系。
32、在一实施方式中,所述编码模块包括:
33、词性识别单元,用于识别所述n个分词的词性;
34、编码单元,用于针对任一分词,将所述分词及其词性进行向量编码,得到每个分词的目标词向量。
35、在一实施方式中,所述编码单元包括:
36、标注子单元,用于将所述分词的词性标注在所述分词上,得到标注后的分词;
37、编码子单元,用于使用word2vec对所述标注后的分词进行向量化,得到所述分词的目标词向量。
38、在一实施方式中,所述初始图构建模块包括:
39、边构建单元,用于根据所述邻接矩阵,构建所有图节点的连接边;
40、第一预测单元,用于根据所有图节点的连接边的长度和方向,预测任两个图节点之间的关系得分以及预测出对应关系得分的得分概率;
41、初始图构建单元,用于将所述关系得分和所述得分概率作为节点信息存入对应的两个图节点中,得到包含所述节点信息和所有图节点的连接边的初始图数据。
42、在一实施方式中,所述完整图构建模块包括:
43、节点提取单元,用于使用图卷积网络提取所述初始图数据中任两个通过其他图节点连接的图节点;
44、第二预测单元,用于根据所述其他图节点的节点信息和所述任两个图节点的节点信息,预测所述任两个图节点的关系得分和得分概率;
45、隐含关系确定单元,用于若所述任两个图节点的关系得分大于得分阈值且任两个图节点的得分概率大于概率阈值,则确定所述任两个图节点之间具备隐含关系。
46、在一实施方式中,所述文本关系提取装置还包括:
47、模型训练模块,用于在根据所述n个分词与所述完整图数据中图节点的映射关系,得到所述n个分词间的连接关系之后,基于所述n个分词间的连接关系,对文本生成模型进行训练,得到训练好的文本生成模型;
48、关键词获取模块,用于获取待生成文本的至少一个关键词;
49、文本生成模块,用于将所述至少一个关键词输入所述训练好的文本生成模型,输出对应的生成文本。
50、第三方面,本技术实施例提供一种计算机设备,所述计算机设备包括处理器、存储器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如第一方面所述的文本关系提取方法。
51、第四方面,本技术实施例提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如第一方面所述的文本关系提取方法。
52、本技术实施例与现有技术相比存在的有益效果是:本技术获取待提取的目标电子病历,对所述目标电子病历的文本进行提取,得到目标文本,对所述目标文本进行分词,得到n个分词,编码所有分词得到每个分词的目标词向量,使用语义提取模型对所有的目标词向量进行语义提取,得到表征所述目标文本语义的m个语义特征,使用依赖关系解析器对所述m个语义特征进行依赖关系提取,得到表征任两个语义特征间依赖关系的邻接矩阵,将所述m个语义特征分别作为一图节点,根据所述邻接矩阵,构建所有图节点的连接边,得到初始图数据,使用图卷积网络提取所述初始图数据中任两个图节点之间的通过其他图节点的连接构成的隐含关系,并使用所述隐含关系在所述初始图数据中再次构建所有图节点的连接边,得到完整图数据,根据所述n个分词与所述完整图数据中图节点的映射关系,得到所述n个分词间的连接关系,基于依赖关系的提取和隐含关系的提取,从而得到较为完整的连接关系,提高了关系提取的准确性、完整性,有助于后续基于文本关系的模型训练使用。
- 还没有人留言评论。精彩留言会获得点赞!