外部语义增强的健康信息短文本关键词识别方法及系统
本发明涉及文本识别,具体地涉及一种外部语义增强的健康信息短文本关键词识别方法及系统。
背景技术:
1、文本关键词识别是一种自然语言处理技术,旨在从文本中识别出最能代表该文本主题信息的关键词。目前,该领域的主要方法包括传统tf-idf、lda及其变体、以及以lstm-crf为代表的神经网络模型等。tf-idf根据文档内的词频以及在所有文档中的相对词频,对词的重要性进行评价,而lda基于隐含狄利克雷分布考虑将文本投影到潜在的主题空间,挖掘出文本中隐含的主题,lstm-crf则通过处理序列数据捕捉长期依赖关系,在长序列中进行关键词的识别。目前的关键词识别方法主要适用于长文档场景,对于短文本场景下的关键词识别任务较难适用。例如,在医疗健康问答平台(如好大夫、丁香医生等)的提问、健康科普文章的标题(如微信公众号的文章标题等)、问答平台中健康话题下的提问(如知乎的“健康”话题等)等场景下,健康信息通常以短文本的形式呈现,存在序列建模过程依赖信息少、词频分布及区分信息不明显等问题,当前的关键词识别方法难以解决此问题。
2、短文本关键词识别能够快速提取出文本的主题和核心信息,是后期的文本分类、信息检索、情感分析、文本聚类以及主题划分等文本分析和信息挖掘任务的基础。健康信息短文本的关键词识别可以应用于医学文献的分类、疾病预测和诊断、药品推荐、病情监测等相关任务的关键信息抽取,为医生、患者和公众提供更加精准、实用、简练的健康信息。例如,当人们在搜索健康相关的问题时,短文本关键词识别可以通过分析搜索词汇,快速准确地识别出与该问题相关的关键词和热门话题,帮助人们快速了解该疾病的症状、治疗方法、预防措施等信息。现有技术中常用的文本关键词识别方法包括tf-idp模型、lda模型以及lstm-crf模型等。这是这些方法针对健康信息短文本均存在各自的缺陷:
3、①难以准确判断关键词权重:一条短文本通常仅会出现一次关键词,其在文本中的权重通常难以准确判断,依赖词频统计信息的方法(如tf-idf)难以取得较好效果。
4、②缺乏丰富的上下文信息辅助识别:短文本场景下能提供的序列依赖信息极少,难以从中发现共性的规律,基于上下文信息(如lda)的主题模型以及序列依赖信息的命名实体识别方法(如lstm-crf)难以适用。
5、③没有现成的术语库提供查询:健康信息文本中出现的关键词是具有复杂医学知识的名词,且关键词常常以口语化的形式出现,并不是统一规范的专业医学名词,当下没有合适的结构化知识库能够提供检索查询。
技术实现思路
1、本发明实施例的目的是提供一种外部语义增强的健康信息短文本关键词识别方法及系统,该识别方法及系统能够提高关键词识别的准确率。
2、为了实现上述目的,本发明实施例提供一种外部语义增强的健康信息短文本关键词识别方法,包括:
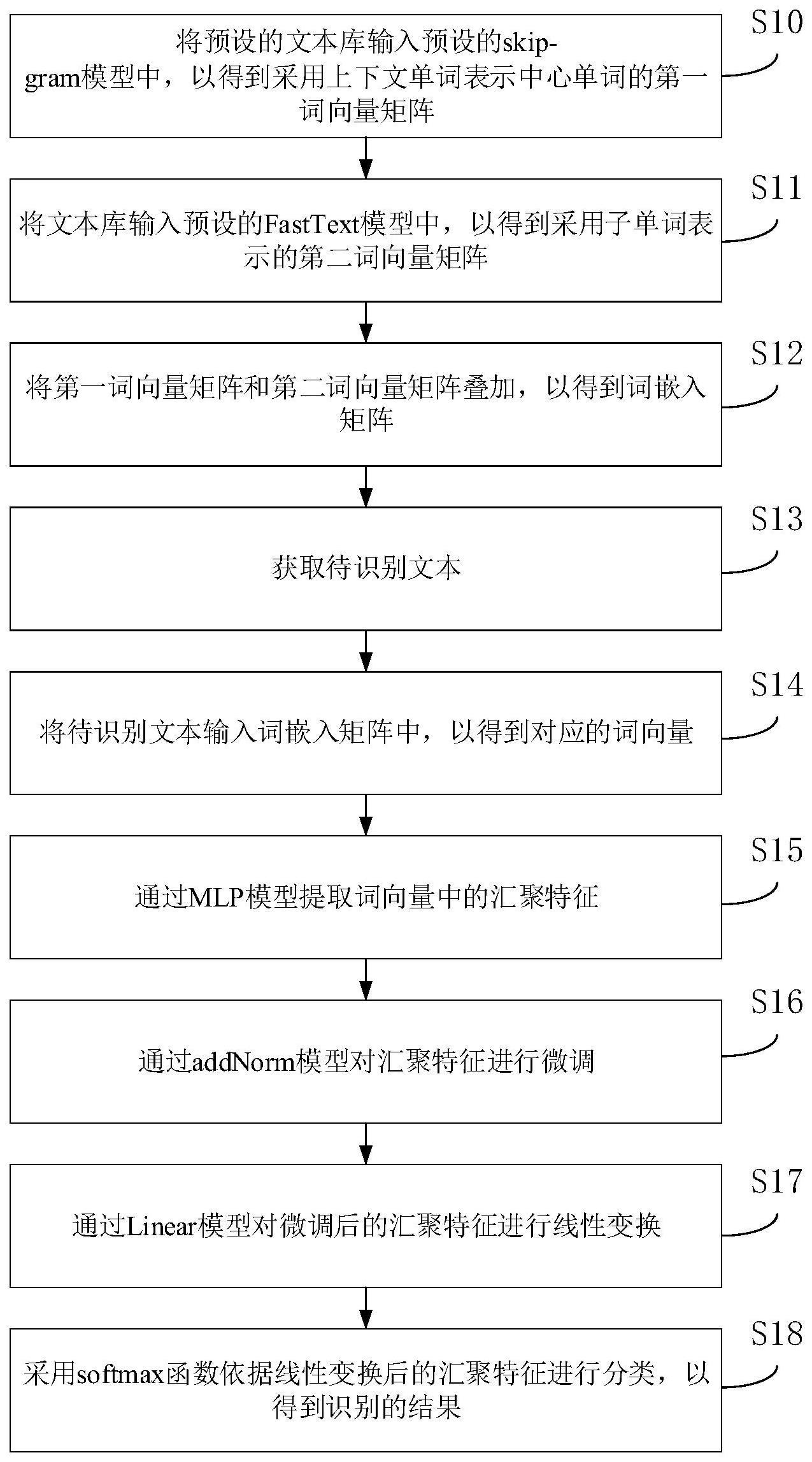
3、将预设的文本库输入预设的skip-gram模型中,以得到采用上下文单词表示中心单词的第一词向量矩阵;
4、将所述文本库输入预设的fasttext模型中,以得到采用子单词表示的第二词向量矩阵;
5、将所述第一词向量矩阵和第二词向量矩阵叠加,以得到词嵌入矩阵;
6、获取待识别文本;
7、将所述待识别文本输入所述词嵌入矩阵中,以得到对应的词向量;
8、通过mlp模型提取所述词向量中的汇聚特征;
9、通过addnorm模型对所述汇聚特征进行微调;
10、通过linear模型对微调后的所述汇聚特征进行线性变换;
11、采用softmax函数依据线性变换后的所述汇聚特征进行分类,以得到识别的结果。
12、可选地,将预设的文本库输入预设的skip-gram模型中,以得到词向量矩阵,包括:
13、对所述文本库进行预处理操作;
14、依据所述文本库构建词汇表;
15、创建所述skip-gram模型的上下文窗口,以得到所述词汇表中的上下文信息;
16、将所述上下文信息输入所述skip-gram模型中,以训练所述skip-gram模型;
17、将训练完成的所述skip-gram模型的输出作为所述第一词向量矩阵。
18、可选地,将所述文本库输入预设的fasttext模型中,以得到采用子单词表示的第二词向量矩阵,包括:
19、构建词汇表;
20、将所述文本库的每个单词加入所述词汇表中,并统计每个单词的词频;
21、生成每个单词的子单词,并确定每个子单词对应的向量表示;
22、依据所述子单词的向量表示,生成每个单词对应的词向量;
23、将所述词向量输入所述fasttext模型中,以训练所述fasttext模型;
24、将训练完成的所述fasttext模型的输出作为所述第二词向量矩阵。
25、可选地,通过mlp模型提取所述词向量中的汇聚特征,包括:
26、根据公式(1)确定所述汇聚特征,
27、mlp(x1)=relu(w2·(relu(w1·x1+b1)+b2)), (1)
28、其中,mlp(x1)为所述汇聚特征,relu为激活函数,w1、w2为所述mlp模型的权重,b1、b2为所述mlp模型的偏置,x1为所述mlp模型的输入。
29、可选地,通过addnorm模型对所述汇聚特征进行微调,包括:
30、根据公式(2)至公式(5)对所述汇聚特征进行微调,
31、x2=mlp(x1), (2)
32、x3=dropout(x2), (3)
33、
34、addnorm(x)=x2+norm(x3), (5)
35、其中,x2为所述汇聚特征,mlp为mlp模型,x1为所述mlp模型的输入,x3为防拟合函数计算后的结果,dropout为防止过拟合函数,norm(x3)为标准化的结果,min表示取最小值,max表示取最大值,addnorm(x)表示微调后的结果。
36、可选地,通过linear模型对微调后的所述汇聚特征进行线性变换,包括:
37、采用公式(6)至公式(8)对进行所述线性变换,
38、x4=addnorm(x), (6)
39、linear(x4)=x4*w3+b, (7)
40、y=linear(x4), (8)
41、其中,x4为微调后的所述汇聚特征,addnorm为addnorm模型,w3为线性变换的权重,b为对应的偏置,y为线性变换的结果,linear为所述linear模型。
42、可选地,采用softmax函数依据线性变换后的所述汇聚特征进行分类,包括:
43、根据公式(9)计算每个类别对应的概率,
44、
45、其中,probabilities为类别的概率,softmax为softmax函数,y为线性变换的结果,yi、yj为第i个、第j个类别的得分值。
46、另一方面,本发明还提供一种外部语义增强的健康信息短文本关键词识别系统,所述系统包括处理器、存储器及存储在存储器上并可在处理器上运行的程序,所述处理器执行程序时实现如上述任一所述的识别方法。
47、通过上述技术方案,本发明提供的外部语义增强的健康信息短文本关键词识别方法及系统通过fasttext模型和skip-gram模型得到词嵌入矩阵,从而为待识别的文本提供查询库,再结合mlp模型提取词向量中的特征,最后分别通过addnorm模型、linear模型和softmax函数得到分类的结果。相较于现有技术而言,本发明提供的识别方法和系统克服了现有技术中常规关键词识别方法在针对健康信息短文本时,无法通过词频统计直接得到关键词,也无法直接通过上下文信息得到关键词,而导致的关键词识别不准的技术缺陷。
48、本发明实施例的其它特征和优点将在随后的具体实施方式部分予以详细说明。
- 还没有人留言评论。精彩留言会获得点赞!