一种基于多视角协同的多领域虚假新闻检测方法
本发明涉及虚假新闻检测领域,具体为一种基于多视角协同的多领域虚假新闻检测方法。
背景技术:
1、随着互联网的普及和社交媒体的流行,虚假新闻已经成为一个严重的问题。虚假新闻不仅会误导人们的思想,而且会对社会产生严重的影响。因此,虚假新闻检测成为一个热门的研究方向。虚假新闻检测的目的是将新闻内容分为真假两类。现有的方法主要可以分为基于内容的方法和基于社交上下文的方法。
2、在基于内容的方法中,研究者主要通过分析新闻的文本内容,从中提取特征来检测虚假新闻。这些特征包括词汇特征、语义特征和统计特征等。一些研究者还利用外部证据,如知识图谱或事实核查网站中的信息,来进行虚假新闻检测。基于内容的方法的优点是可以独立地分析新闻文本,但缺点是可能忽略了社交上下文信息。
3、基于社交上下文的方法主要是通过对新闻传播过程进行建模,挖掘新闻传播的结构信号。这些方法可以通过分析社交媒体实体之间的交互来捕捉社交上下文信息。另一方面,一些研究者利用群体智慧,如情感和立场等,来检测虚假新闻。
4、多领域虚假新闻检测是虚假新闻检测的一个重要分支。不同领域的新闻有着不同的特征,因此需要使用不同的模型来检测虚假新闻。多领域虚假新闻检测方法旨在从不同领域的数据中学习到通用的特征,以提高虚假新闻检测的准确性和泛化性能。
5、基于情感的虚假新闻检测是另一种虚假新闻检测的方法。研究表明,情感特征对于虚假新闻的检测非常重要。一些研究者利用情感特征、新颖性以及情绪等多个任务来进行多任务学习,以提高虚假新闻检测的性能。
6、综上所述,虚假新闻检测是一个重要的研究方向,可以通过基于内容、基于社交上下文、多领域和基于情感等多种方法来进行。这些方法可以分别或结合使用来提高虚假新闻检测的准确性和泛化性能。未来,虚假新闻检测的研究将继续发展,同时也需要不断地探索新的技术和方法,以应对新的虚假新闻的挑战。
技术实现思路
1、本发明的目的是针对现有技术的缺陷,提供一种基于多视角协同的多领域虚假新闻检测方法,以解决上述背景技术提出的问题。
2、为实现上述目的,本发明提供如下技术方案:一种基于多视角协同的多领域虚假新闻检测方法,按如下步骤完成判断该新闻是否为虚假新闻:
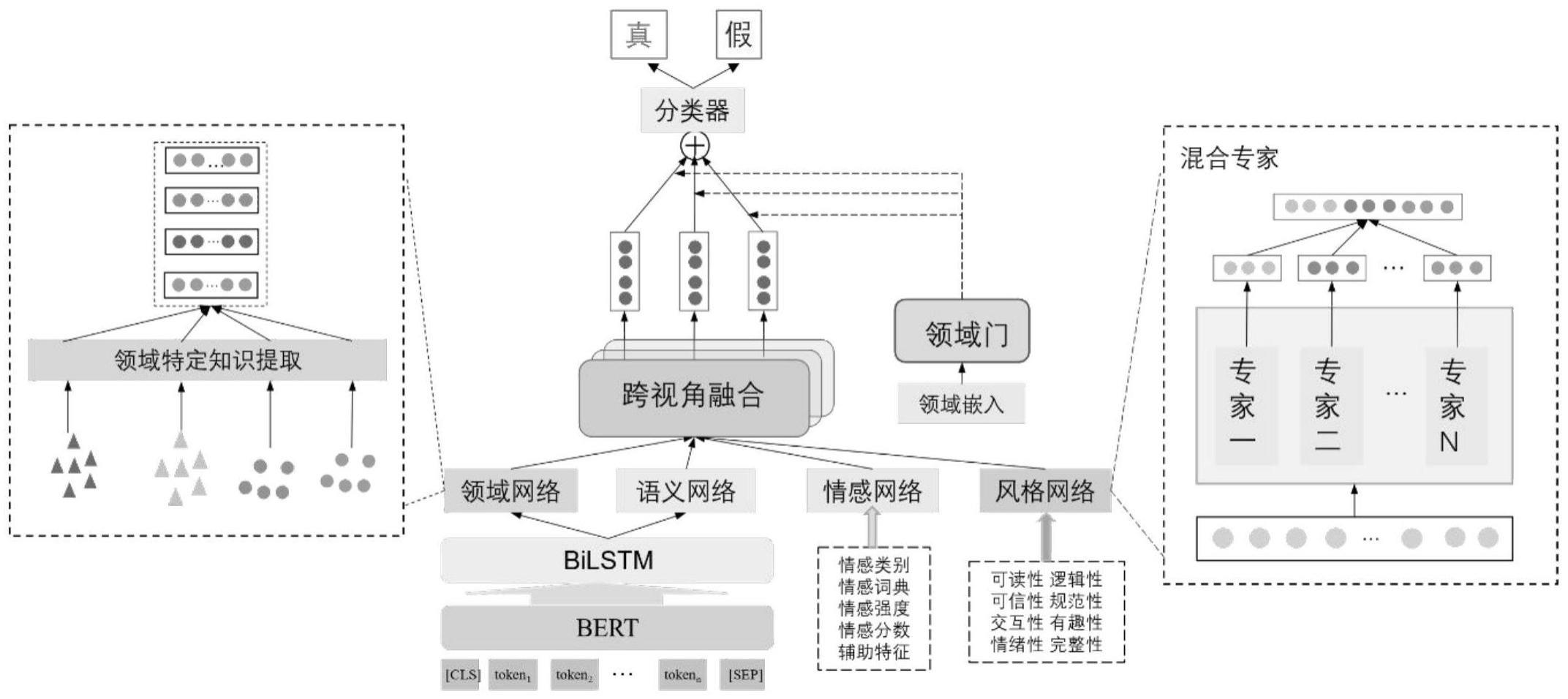
3、s1:接收新闻内容输入,将输入新闻内容经过bert模型处理,获得词嵌入向量;
4、s2:将词嵌入向量通过双向lstm处理,提取新闻的顺序特征;
5、s3:使用语义网络和领域网络分别处理新闻内容,得到新闻的语义特征和领域特定特征;
6、s4:通过混合专家系统处理新闻内容,获得情感特征和风格特征;
7、s5:将语义特征、领域特定特征、情感特征和风格特征输入跨视角融合模块实现自适应跨视图表示;
8、s6:根据领域网络获得的权重,对融合后的特征进行加权求和,得到总的特征表示;
9、s7:将总的特征表示输入分类器模块,对新闻内容进行真假性判断;
10、s8:输出新闻真假性判断结果。
11、作为本发明的一种优选技术方案:所述虚假新闻检测问题的建模包含以下步骤:
12、k1:将新闻p的文本内容使用bert预训练模型编码为长度为t的标记序列;
13、k2:从新闻p中提取情感特征e和风格特征s,其中情感特征e和风格特征s都是数值特征;
14、k3:将新闻p的域标签g作为输入,结合情感特征e和风格特征s,使用多任务学习的方法,训练一个多领域虚假新闻检测模型;
15、k4:对于新闻p,输入其文本标记序列、情感特征e和风格特征s,结合其域标签g,使用训练好的多领域虚假新闻检测模型,输出其真假标签y;
16、k5:对于多个域标签,重复步骤k3和k4,得到每个域下的真假标签y,最终将多个域下的真假标签y结合起来,得到新闻p的最终真假标签;
17、k6:对于新闻p的每个域标签,使用一组混淆矩阵、准确率、召回率、f1分数等指标,评估该域下的虚假新闻检测性能。
18、作为本发明的一种优选技术方案:所述多视角协同的具体提取流程包含如下步骤:
19、(a):设置超参数t,表示专家网络中的专家个数;
20、(b):构建混合专家网络,包括语义网络、情感网络、风格网络和领域网络;
21、(c):将输入新闻文本转换为词向量w;
22、(d):对于每个专家网络执行以下操作:
23、(d1):确定各个专家网络模型结构以及其中的可学习参数θi;
24、(d2):利用词向量w和可学习参数θi,计算专家网络的输出表示ri;
25、(e):根据各个专家网络的输出表示ri,获得输入新闻文本的多视角特征表示;
26、其中,每个专家网络(1≤i≤t)都有自己擅长的领域,善于提取某一领域的特征。
27、作为本发明的一种优选技术方案:所述s5中跨视角融合的具体流程步骤为:
28、s51:接收多个视图的输入数据,其中每个视图表示一个特定的数据特征,包括但不限于语义、情感和风格;
29、s52:为每个视图计算对应的权重系数,其中wsem,wemo和wstl分别表示语义、情感和风格视图的权重系数;
30、s53:计算跨视图交互表示z,通过将不同视图的权重系数与对应的视图表示相乘并求和得到,其中计算公式为:
31、
32、其中ksem,kemo,kstl分别代表语义网络,情感网络以及风格网络中的专家个数,其中lnrsem,lnremo和lnrstl分别表示语义、情感和风格视图的视图表示,wdomain和lnrdomain代表领域权重和领域局部视图表示;
33、s54:设置多头跨视角融合,每个头自适应地学习一种跨视图表示,生成一组跨视图表示集合其中h代表跨视图表示的数量;
34、s55:根据生成的跨视图表示集合对输入数据进行分类或回归任务处理并输出结果。
35、作为本发明的一种优选技术方案:所述s7中分类器模块的具体特征为:
36、s71:采用不同的专家网络获取新闻文章的跨视图表示;
37、s71:将领域标签输入领域门,以建模领域差异,得到权重分数,权重函数表示为softmax(mlp(g));
38、s71:根据计算得到的权重分数聚合跨视图表示,公式为:
39、s71:将聚合后的跨视图表示输入一个具有softmax输出层的多层感知分类器,用于虚假新闻的二分类问题;
40、s71:采用二分类交叉熵损失函数进行网络训练,损失函数表示为yi代表的是真实标签,代表的是预测标签。
41、作为本发明的一种优选技术方案:所述(b)中构建混合专家网络的具体步骤如下:
42、(b1):对新闻文本进行bert标记和lstm序列信息提取,获得新闻文本的语义特征表示rsem;
43、(b2):对情感类别、情感词典、情感强度、情感分数和辅助特征五方面作为情感特征输入情感网络,使用混合专家网络提取情感特征,获得新闻文本的情感特征表示remo;
44、(b3):对可读性、逻辑性、可信性、规范性、交互性、有趣性、情绪性和完整性八方面作为风格特征输入风格网络,使用混合专家网络提取风格特征,获得新闻文本的风格特征表示rstl;
45、(b4):对每个领域使用一个特定的领域特征提取网络,使用textcnn提取领域特征,获得新闻文本的领域特定特征表示rdomain;
46、(b5):将三组不同来源的特征表示rsem、remo、rstl和领域特定特征表示rdomain进行组合,得到多维特征表示,全面描述新闻文本的内容和特征。
47、本发明所述一种基于多视角协同的多领域虚假新闻检测方法,采用以上技术方案与现有技术相比,具有以下技术效果:
48、本发明的有益效果是:本发明提出的一种基于多视角协同的多领域虚假新闻检测方法,可以更好地利用领域信息,实现在多领域场景下的假新闻修正。有了专家网络进入特征提取,引入领域门户网络学习领域与视角之间的关系,并利用多视角融合和bilstm模块有效地捕捉新闻的多视角特征表示。多种虚拟假新闻检测方法的比较,试验证明了该方法的有效性和优良性。本发明的有效果是提高了假新闻检测的准确率和可靠率,可以在新闻媒体、社交网络等陵墓下进行多领希望减少虚假信息对公众和社会的影响影响,保护信息安全和社会稳定。
- 还没有人留言评论。精彩留言会获得点赞!