基于EMD-APSO-SVR模型铁路货运量预测方法与流程
本发明涉及数据预测,具体涉及基于emd-apso-svr模型铁路货运量预测方法。
背景技术:
1、铁路货运量是体现铁路运输能力的重要指标之一。地大物博的中国幅员辽阔,自然资源因气候、地理位置的存在分布不均的现象,而不同地区之间的物资需求也存在明显差异,对于运输业来说是个严峻的挑战,而铁路运输一直以来都是我国物流业运输的中流砥柱,是货物运输的重要载体。结合强相关性的影响因素,在一定范围内科学精准且有效的铁路货运预测,可以获得不同时空的流量特征,有利于为铁路工作规划提供更加可靠全面的参考帮助,对于铁路行业的规划工作起着重要作用。但在类似流行性传染病这类突发情况下,除开铁路运输行业之外的其他各行业都会在短时间内受到冲击。以往常用的铁路货运量的预测模型精度也会受到较大影响。因此在类似突发情况下,准确预测铁路货运量数据变化趋势对于铁路运输行业的发展具有重要意义。
2、box和jenkins于上世纪七十年代一同构建了最初期的时间序列预测模型——arima模型,其在交通运输流量预测的应用效果被美国学者brockweil.r.j和davis.r.a肯定。后续也有越来越多的学者提出不同定量预测方法,最常用的是基于传统统计学方法和机器学习的预测方法。对于数据不平稳、动态变化特点明显的预测目标来说,基于机器学习的预测方法一直受到学者的青睐,例如灰色预测模型、神经网络预测模型、支持向量机预测模型等,但单一的预测方法不免有一定的局限性,无法很好处理数据中的随机性及突发性波动。针对这个缺陷,学者结合几种预测方法的特点构建组合预测模型,融合几种方法的优点,有效了提高预测目标的预测精度。其中,支持向量机回归模型(support vectorregression,svr)兼容性强、适用于小样本预测及短期预测等特点,近几年在回归预测领域受到学者的广泛应用。王治利用遗传算法对svr模型进行参数优化,发现该组合模型比神经网络模型的预测误差更小。张鹏等改进了王治的研究方法,结合经验模态分解(empiricalmode decomposition,emd),建立e md-ga-svr对目标值的分量进行预测,证实了改进后算法拥有较好的预测效果。为解决铁路货运量与影响因素之间的非线性关系,有学者研究出了自适应粒子群优化(adaptive particle swarm optimizati on,apso)的最小二乘支持向量机模型,有效地预测了铁路货运量,但相对误差波动较大。张蕾等人等选择结合灰色关联分析对支持向量机模型进行改善,发现改进后的模型具有较高的泛化能力,但其参数难以确定,因此梁宁等深入他们的研究,运用果蝇算法确定该组合模型的最优参数,提高了其推广能力。陈楠在研究svr预测模型的过程中引入模糊信息粒化、相空间重构等知识对数据进行预处理,并对北京铁路局货运量进行实例分析,缩小了样本数据的预测误差,但得到的仅为预测范围,数据信息的处理还需进一步加强。刘祝娟等将粒子群优化算法(particleswarm optimization,pso)运用到svr模型中,通过优化参数保证预测的稳定性,有利于提高模型的泛化能力。
3、针对现有技术存在的上述不足,本发明提出一种基于emd-aps o-svr模型铁路货运量预测方法,提高铁路货运量预测的准确性,减少类似流行性传染病这样的突发事件对现有预测结果的不稳定影响。
技术实现思路
1、本发明提出一种基于emd-apso-svr模型铁路货运量预测方法,进一步加强对如今不断变动的大环境下铁路货运量时间序列特征的分析,针对铁路货运量进行经验模态分解研究,结合前期的数据处理,通过引入自适应变异策略的粒子群算法,对svr模型的参数进行优化,进一步增强预测模型的精确度和有效性。
2、为了达到上述技术目的,本发明是通过以下技术方案实现的:
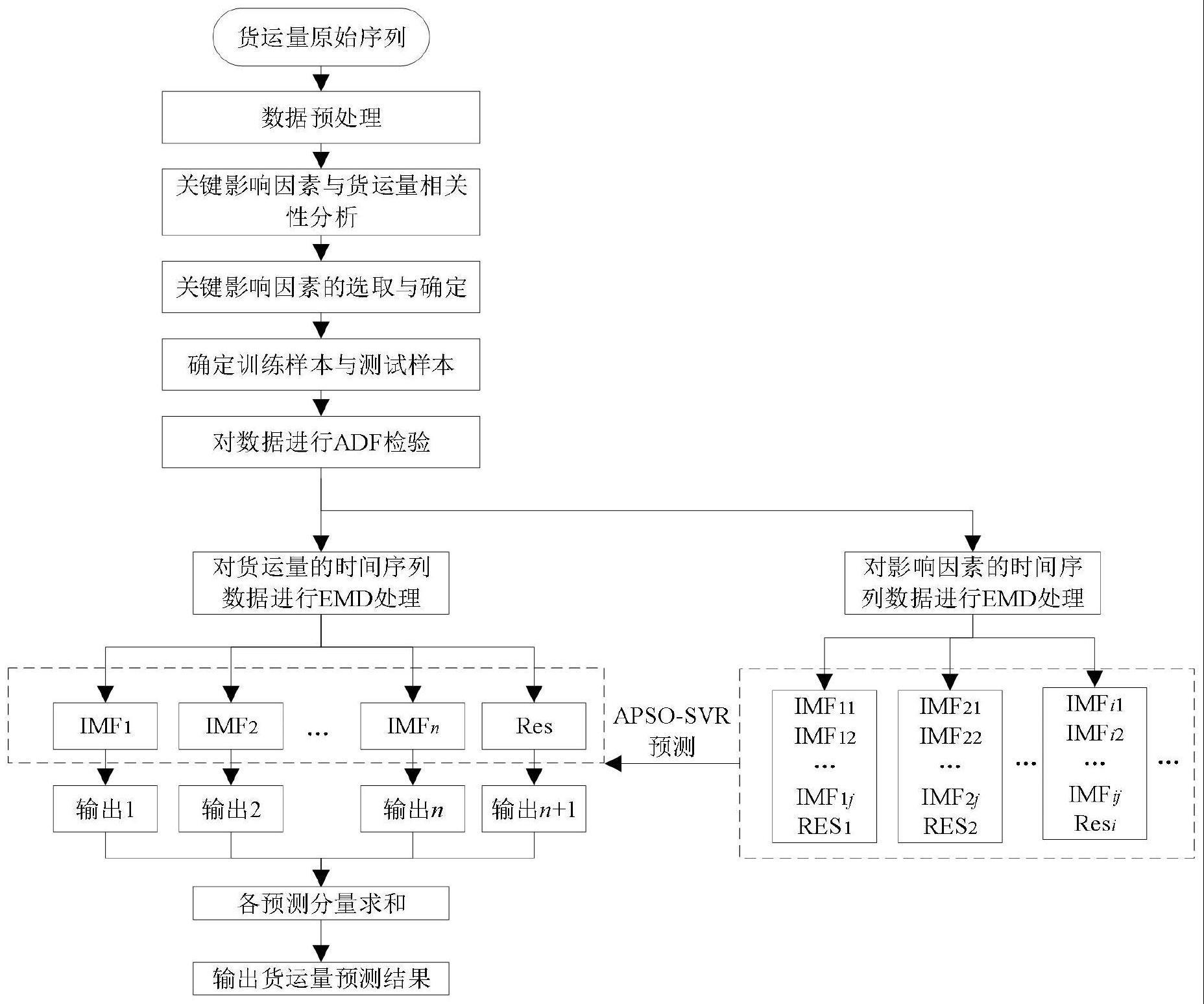
3、基于emd-apso-svr模型铁路货运量预测方法,包括以下步骤:
4、s1:货运量原始序列进行序列分解;
5、s2:进行关键影响因素与货运量相关性分析;
6、s3:对影响因素的时间序列数据进行序列分解;
7、s4:将经过序列分解后的数据进行模型优化与预测;
8、s5:对得到的预测结果进行评价。
9、进一步的,所述步骤s1中序列分解操作具体为经验模态分解(e md),所述经验模态分解(emd)具体为:将货运量原始序列非线性不平稳的数据分解成一系列的本征模函数(intrinsic mode functions,i mf)和一个残差项(res),得到的各组imf均具有不同的时间尺度特征;整个过程可类似于局部平稳化的过程,通过分解得出的不同时间尺度特征的模函数实现非平稳数据的平稳化;主要步骤包括如下步骤:
10、s1.1:求出原数据的所有极值点(包含极大值点与极小值点);根据样条插值法对两类极值点分别进行拟合,得到原数据序列的上包络线emax(t)和下包络线emin(t);
11、s1.2:根据上包络线和下包络线,绘制平均包络线eave(t),如下式:
12、
13、s1.3:求原始序列e(t)与平均包络线差值h(t):
14、h(t)=e(t)-eave(t)
15、s1.4:判断h(t)是否满足条件:序列中的极值点数以及零点数的差值绝对值小于等于1,同时要求h(t)上下包络线平均值为零;如果满足,h(t)即为分解出的一个imf;若不满足,则将h(t)新序列进行步骤s1.1至步骤s1.4的重复,直到满足条件输出imf;当得到第一个本征模函数imf1时,用原序列减去imf1可得残差r1(t):
16、r1(t)-e(t)=h1(t)
17、再将r1(t)作为新序列带入,重复步骤s1.1-s1.4,多次分解,直到残差项成为一个单调或振荡幅度极小的函数;
18、s1.5:根据以上分解步骤,得到多个imf项以及最后的一个残差项:
19、
20、进一步的,所述步骤s2中的关键影响因素包括:国民生产总值(gdp)、铁路营业里程、原煤与钢铁产量、第二产业增加值当季值、流行性传染病月底累计新增确诊人数;
21、所述关键影响因素的相关性分析具体包括pearson相关性和spearman秩相关性分析。
22、进一步的,所述步骤s4中模型优化具体包括通过粒子群算法(apso)进行支持向量机回归模型的优化,所述支持向量机回归模型(svr)以径向基函数(rbf)进行预测,需要设定支持向量机回归模型(svr)的惩罚参数c和径向基函数(rbf)的参数的函数中心γ;所述优化与预测包括以下步骤:
23、s4.1:初始化apso的系列参数,确定svr模型参数的范围,设置种群规模、粒子的迭代次数;
24、s4.2:随机生成初代种群粒子的位置和速度,用向量(c,γ)表示粒子所在位置;
25、s4.3:确定并计算粒子的适应度函数,将预测结果的均方误差设置为粒子的适应度函数;然后将每个粒子的位置(c,γ)代入svr回归模型,计算每个粒子的适应值,选择适应值最小位置为个体最优位置,即个体极值,比较并选择所有粒子的最优位置为群体极值;
26、s4.4:进行迭代更新,根据下两式更新粒子群体的速度和位置,并重复步骤s5.3计算所有更新后的适应度值,当前迭代次数下群体的个体最优值及全局最优值;
27、vid(n+1)=wvid(n)+c1r1(pid(n)-xid(n))+c2r2(pgd(n)-xid(n))
28、xid(n+1)=xid(n)+vid(n+1)
29、其中:vid(n)、xid(n)、pid(n)、pgd(n)分别为第n次迭代中第i个粒子在第d维空间上的速度、位置、个体最优值和全局最优值;r1,r2为互不相关的独立数,随机分布在区间[0,1];c1,c2为学习因子,通常h(t);
30、s4.5:达到apso的最大迭代次数后算法结束,将当前粒子群的群体极值(c,γ)作为模型的最优参数输入svr模型,输出预测值。
31、进一步的,所述步骤s5中的评价具体包括:根据平均绝对百分比误差(mape)、均方根误差(rmse)、及决定系数(r2)评估预测模型的精度;
32、
33、
34、
35、当rmse与mape的值均越接近于0,r2的值越接近1,预测值与真实值越吻合。
36、本发明的有益效果是:
37、本发明提出一种基于emd-apso-svr模型铁路货运量预测方法,提供的一种基于emd和apso优化的svr组合预测模型,在综合考虑铁路货运量受gdp、铁路营业里程、原煤产量、钢材产量、第二产业增加值以及流行性传染病等因素情况下,对选取的货运量序列进行emd处理,得到不同时间尺度下的本征模态函数和残差;通过自适应变异策略下的粒子群算法优化svr模型的参数,并利用优化后的组合模型对各imf分量分别进行预测,相加得到最终结果。将a pso-svr模型与emd-apso-svr模型的预测状况进行对比,结果表明,本发明建立的emd-apso-svr模型的预测结果误差更小,其预测值与真实值的测定系数高于apso-svr模型;前者的平均绝对百分比误差仅有0.22%,该模型能有效提升铁路货运量短期内的预测精度。
38、本发明将emd、pso、svr相结合,提出组合预测方法对铁路货运量月度数据进行预测,由于铁路货运量及其部分影响因素数据均不平稳,所以对目标值与特征值均进行经验模态分解处理,将不同特征值的分量进行排列组合,利用apso-svr对目标值的分量进行回归预测,继而将结果相加得到月度铁路货运量预测数据。结果表明e md-apso-svr预测效果理想,相较于apso-svr的准确度更高,预测精度更高,不仅能反映决定因素对铁路货运量的长期作用,也能有效反映随机因素对铁路货运量的波动影响,同时具有较强的泛化能力。
- 还没有人留言评论。精彩留言会获得点赞!