一种基于电力大数据挖掘算法的电路负荷预测方法与流程
本发明涉及电力负荷预测,具体涉及一种基于电力大数据挖掘算法的电路负荷预测方法。
背景技术:
1、随着大数据时代的到来和各种智能设备的增加,设备获取的各类数据发生着指数级的增长,给电力系统带来了额数据类型多样化、价值密度低的海量数据。此外,随着科技进步与发展,各种各样的智能设备的増加使得电力负荷的采集点的分布更加密集,采集频率变高,进一步催化了电力负荷数据的指数级增长。与此同时,电力数据复杂程度也日益加深,数据存储规模也迅速增长甚至达到了pb级别。因而,如何运用数据挖掘算法找到适合电力负荷预测进行建模和学习,提高电力负荷预测精度,成为一个重要问题。
2、如中国专利cn108053055a,公开日2018年05月18日,本发明涉及一种基于支持向量机的大型城市中长期电力负荷组合预测方法,其技术特点在于:包括以下步骤:步骤1、以大型城市中长期负荷的分区特征值和分区面积作为输入,提出基于负荷密度法的大型城市中长期负荷预测方法;步骤2、以历史年负荷数据作为输入,提出基于趋势外推法的大型城市中长期负荷预测方法;步骤3、以专家经验和年负荷历史数据作为输入,提出基于专家经验的年均增长率法的大型城市中长期负荷预测方法;步骤4:基于步骤1、步骤2和步骤3的负荷预测结果,应用支持向量机法进行拟合,提出基于支持向量机的大型城市中长期负荷组合预测方法。本发明通过对三种负荷预测方法进行二次拟合,获得了大型城市电网中长期的负荷预测值。本发明采用的趋势外推法泛化性能不高,只适用于变化较为平稳且没有跳跃式变化的负荷数据,在预测有波动性的负荷值时精度不高。
技术实现思路
1、本发明要解决的技术问题是:现有技术对负荷的预测精度不高的技术问题。提出了一种基于电力大数据挖掘算法的电路负荷预测方法,泛化性能好,且预测精度也高。
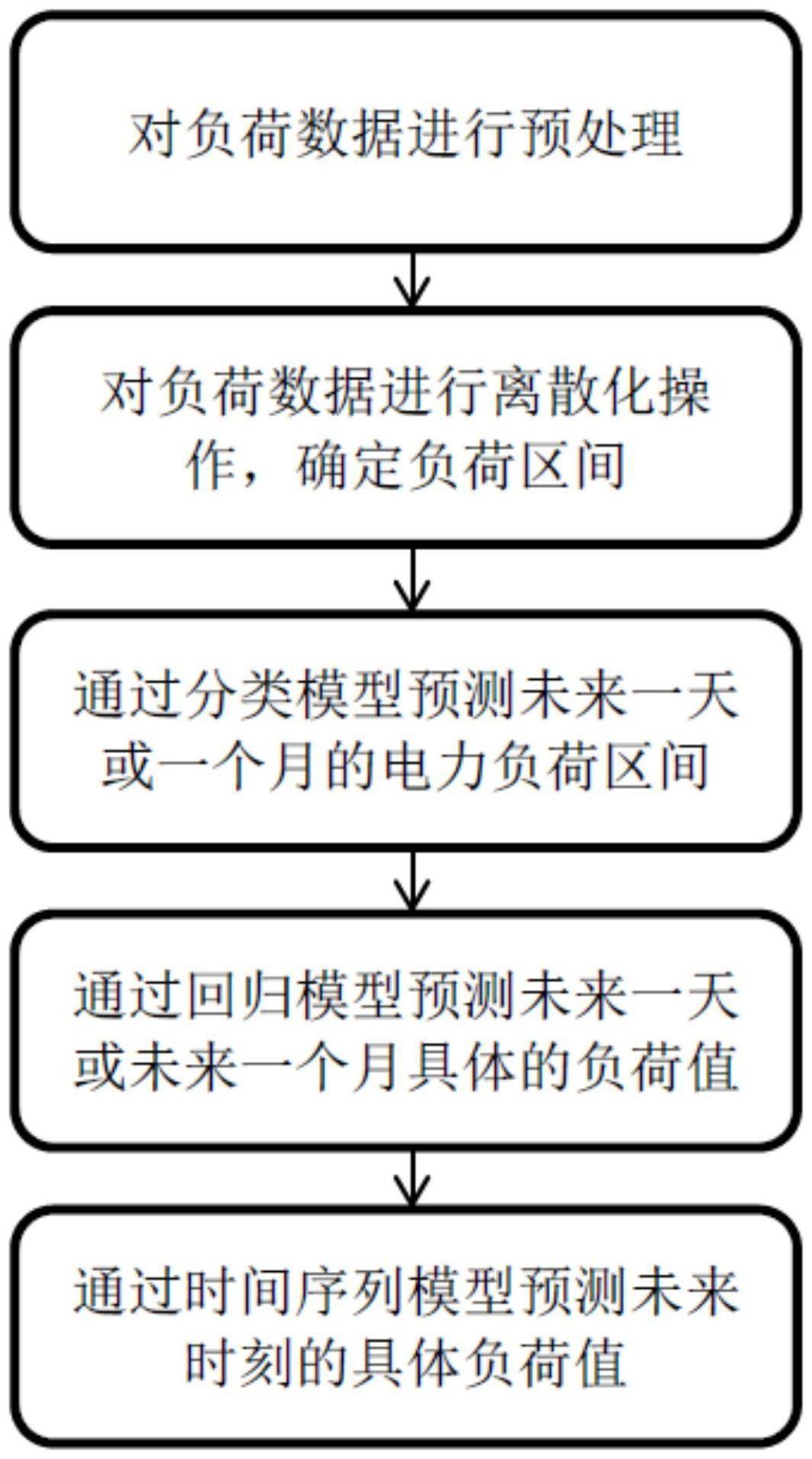
2、为解决上述技术问题,本发明所采取的技术方案为:一种基于电力大数据挖掘算法的电路负荷预测方法,包括如下步骤:
3、s1:对负荷数据进行预处理;
4、s2:基于x-means算法对负荷数据进行离散化操作,确定负荷区间;
5、s3:采用随机森林算法建立分类模型,预测未来一天或者一个月的电力负荷区间;
6、s4:采用随机森林算法建立回归模型,预测未来一天或者未来一个月具体的负荷值;
7、s5:结合weka中的时间序列模型采用随机森林方法对历史负荷数据进行时间序列预测,预测未来时刻的具体负荷值。
8、一种基于电力大数据挖掘算法的电路负荷预测方法,通过对天气数据和负荷数据的整理,首先从数据库中导出数据转化为可以使用的文本格式,然后对数据进行初步的预处理,比如:对空值的处理,对数值型的数据进行标准化处理等,采用x-means聚类算法对负荷数据进行离散化操作,提取出合理的负荷区间,便于分类模型的建立,采用随机森林对预处理完的负荷数据进行分类建模,预测未来x或者-个月的电力负荷区间,为了弥补区间预测的负荷的粒度不够细,本文采用随机森林对负荷数据做冋归操作,预测未来一天或者未来一个月具体的负荷值,结合weka中的时间序列模型采用随机森林方法对历史负荷数据进行时间序列预测,预测未来时刻的具体负荷值。
9、作为优选,所述步骤s1包括以下步骤:
10、s11:数据填充和异常值处理:根据缺失数据相邻的负荷数据,对缺失数据进行填充,根据异常值相邻的负荷数据,对异常值进行替换修改;
11、s12:特征规范化:通过区间规范化方法对负荷数据的各个特征进行规范化;
12、s13:特征选择:利用信息增益公式计算各个特征的信息增益,选取有用的特征。缺失数据和异常值的存在会影响负荷预测的精度,不仅增加负荷预测的难度而且还会使增加数据序列的整体噪声,因此需要对这些缺失数据和异常值做处理,找到合理的数值去替换缺失数据和异常值,进一步提高数据的质量。
13、作为优选,所述步骤s11中的缺失数据的填充和异常值的替换都根据以下公式进行计算:
14、x(d,t)=ω1x(d1,t)+ω2x(d2,t)
15、其中:x(d,t)表示第d天第t小时对应的负荷值,ω1x(d1,t)表示第d-1天第t小时对应的负荷值,ω2x(d2,t)表示第d+1天第t小时对应的负荷值,ω1和ω2分别表示前一天及后一天负荷的权重,ω1=ω2=0.5。由于负荷数据具冇较强的周期性,影响因素也比复杂,因此,针对某一天缺失了很多数据的记录,我们利用相邻几天的正常数据进行加权处理,然后进行填充以减小误差。
16、作为优选,所述区间规范化方法包括以下步骤:根椐特征值的区间的边界值将数值归一化到[0,1]区间,计算如式
17、
18、其中:mina和maxa分别为特征a的最小值和最大值,vi为特征a的某一个值,v′i为特征a的某一个值规范化后的值,当某个特征的最大值和最小值相等时,该特征的所有数值都变为1。原始数据表中不同特征的值域可能存在较大差异,不对这些数据做处理直接分析的话,值域范围大的特征将掩盖掉值域范围小的特征,使得类似于催收次数这样值域小的特征会被用电量这样值域大的特征掩盖掉进而无法得到有效利用。
19、作为优选,所述信息增益公式如下所示:
20、
21、其中:ig(xi)表示信息增益的大小,d表示所有的负荷预测记录,dv表示将d划分为v个子集{d1,d2,...,dv),ent(d)表示数据集d中的信息熵,信息熵的计算公式如下所示:
22、
23、其中:y表示负荷类别的个数,pi表示在数据d中第i类负荷的比重。由于原始数据表中包含许多无意义的值,如果不进行处理直接进行建模则会影响负荷预测的结果,为了减少预测算法中的数据处理量,提高算法的预测效率,还需要对数据做特征选择。
24、作为优选,所述步骤s5包括以下步骤:
25、s51:将负荷特征通过增加额外的特征对和时间有关的目标字段根据不同时间间隔的大小进行编码,生成一张关于该目标特征的不同时间间隔大小的表。
26、s52:利用随机森林算法对进行数据转换后的负荷值进行预测。时间序列预测是根据特征的历史数据信息预测未来一段时间的特征数据,本文通过基于weka构建时间序列预测模型,通过将时间序列数据转换为一种标准学习算法可以处理的格式,然后再利用数据挖掘算法对数据进行建模,将负荷特征输入构建完成的模型中,即可得到预测负荷值。
27、作为优选,所述分类模型通过计算查全率和查准率进行模型评估,公式如下所示:
28、
29、
30、其中:ri表示查全率,pi表示查准率,mii表示类别i预测正确的记录数,表示类别i的记录数,表示真实属于类别i的记录数。查准率是指预测为某一类别的所有记录与实际匹配的记录数占预测为该类别的记录数的比例,查全率是指预测为某一类别的记录数与实际匹配的记录数占该类别实际包含的记录数的比例,它是从真实类别的角度来衡量模型的预测效果的。
31、作为优选,所述时间序列模型通过计算常用误差值来进行模型评估,公式如下所示:
32、
33、
34、
35、其中:mae、rmse和mape表示三个常用误差,ai表示真实值,fi表示预测值。mae、rmse和mape的值越小,则模型的预测效果越好。
36、作为优选,所述步骤s3包括以下步骤:对测试数据进行离散化处理;将测试数据输入训练完成后的分类模型中,得到负荷区间形式的输出结果。在预处理阶段就需要对负荷数据进行离散化,并映射到对应的区间。
37、作为优选,所述步骤s4包括以下步骤:对测试数据进行预处理;将预处理后的测试数据输入训练完成后的回归模型中,得到具体的负荷值。不需要离散化负荷值,模型直接输出具体的负荷值,而不是一个可能的负荷区间。
38、本发明的实质性效果是:一种基于电力大数据挖掘算法的电路负荷预测方法,利用森林算法建立了分类模型、回归模型和时间序列模型,可以完美预测处未来某一段时间的负荷区间和负荷值,也可以预测处未来某一时刻的具体负荷值,预测精度高,模型适用范围广。
- 还没有人留言评论。精彩留言会获得点赞!