一种基于生成对抗网络的联邦学习优化方法
本发明属于联邦学习领域,具体涉及一种基于生成对抗网络的联邦学习优化方法。
背景技术:
1、随着通信技术的发展,电子设备覆盖了人们生活的方方面面。而这些海量的电子设备携带着海量的数据,如果使用大数据和人工智能技术对这些数据进行挖掘分析,那么这些数据就会产生巨大的价值。但是传统的集中式机器学习技术要求把数据上传到中央服务器进行训练,这涉及到了通信、隐私、安全等问题,亟需一种新的方法突破这个困局。
2、联邦学习是一种被提出来取代传统集中式学习的新方法,它使得各个移动设备能够充分利用自己的训练数据协同训练一个全局共享的神经网络模型,而无需上传本地数据到服务端进行集中式训练。在联邦学习中,服务端首先会通过某种选择策略选择一定数量的客户端参与训练,这些客户端基于本地数据独立训练出本地模型。然后各个客户端将训练好的本地模型参数上传到服务端,服务端将它们聚合到一个新的具有泛化能力的全局模型中。通过将用户的数据留在本地的训练方式保护了用户的隐私。
3、由于不同客户端的硬件、用户使用习惯不同,它们的数据往往是异构的,是非独立同分布的,这会严重阻碍联邦学习全局模型的收敛和造成性能下降。因此需要一种有效的联邦学习方法解决上述问题。
4、生成对抗网络是一种有效的生成模型,它由生成器和判别器组成。生成器的任务是随机抽取潜在空间中的样本以生成和真实样本相似的数据。判别器的任务是评估生成器生成的数据和真实的数据的相似程度。两者在训练的过程中相互对抗和博弈以达到一个平衡点。近年来,由于生成对抗网络可以到学习数据的底层分布特点,它被广泛地应用在小样本学习、数据增强中。
技术实现思路
1、本发明针对现有技术不足,设计并实现一种基于生成对抗网络的联邦学习优化方法。
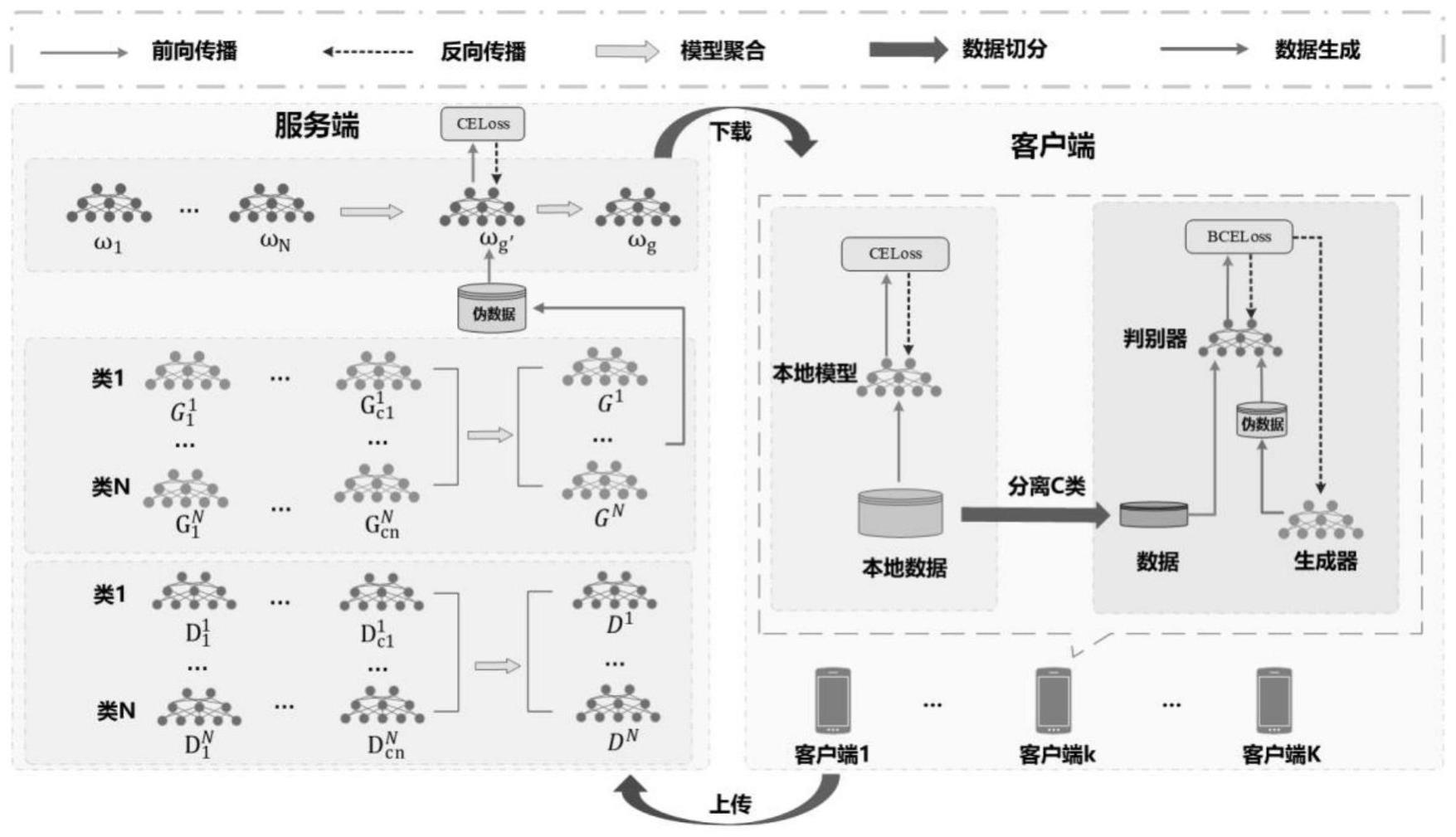
2、本发明通过利用生成对抗网络能够通过学习训练数据分布的特点,让生成对抗网络学习客户端上数据量最多的类对应的数据分布,这些数据是客户端上质量最好的,因此生成对抗网络可以很好地学习到这些数据的特征,从而生成器可以基于真实样本生成质量较高的假样本。在训练完生成对抗网络之后,服务端聚合各个类对应的生成器和判别器得到全局生成器和全局判别器,并利用各个类对应的全局生成器生成一组独立同分布的数据集,利用该数据集对全局模型进行微调训练,从而增强全局模型的泛化能力和面对异构数据的稳定性。
3、一种基于生成对抗网络的联邦学习优化方法,包括如下步骤:
4、s1,服务端获取所有参与联邦学习训练的客户端上样本数量最多的类别,即主类ck,用以给客户端发放对应主类的判别器、生成器模型参数。服务端初始化全局模型、n组用于生成各个主类数据的全局生成器参数{θ1,…θi…,θn}和全局判别器参数{d1,…di…,dn},n表示主类数量。
5、s2,服务端根据客户端参与率随机选择k个客户端参与本轮全局训练,并将全局模型参数ω,客户端k,(k∈k)中主类ck对应的全局生成器参数θck和全局判别器参数dck下发到参与本轮全局训练各个客户端。
6、s3,客户端接收到全局模型参数ω、全局生成器参数θck和全局判别器参数dck,作为客户端的本地模型参数、本地生成器参数和本地判别器参数,开始本地训练。训练完成将更新后的本地模型参数和本地生成器参数、本地判别器参数上传到服务端。
7、s4,服务端聚合参与本轮全局训练各个客户端的本地模型,并采用分组聚合策略聚合对应的本地生成器参数和本地判别器参数,从而聚合相同主类的数据特征,得到新的全局模型和全局生成器、全局判别器。
8、s5,服务端协调每个主类对应的全局生成器{θ1,…θi…,θn},生成一组包含所有主类并且每个主类数据相等的独立同分布数据集。利用该数据集对全局模型进行微调训练以纠正全局模型优化方向,同时防止了知识遗忘的现象的发生。
9、步骤s3中包括如下步骤:
10、s31,对于参与本轮训练的客户端,它们的目的是基于本地数据寻找一个最优的本地模型,使得损失值尽可能地小:
11、
12、其中,ωk表示客户端k的本地模型参数,fk表示客户端k的本地目标函数。具体来说,客户端用全局模型初始化其本地模型,并用本地数据执行随机梯度下降算法(sgd)更新本地模型参数,计算公式如下:
13、
14、其中表示第t轮训练客户端k的本地模型参数,η表示本地模型的学习率;表示本地模型的梯度更新;为本地模型正向传播的损失值。
15、s32,客户端本地生成器和判别器的训练目的是基于主类数据采用对抗方式使得生成器尽可能学习该数据分布,判别器尽可能公正地区别接收到的数据是否真实,即最小化生成器损失和最大化判别器损失:
16、
17、其中g(·)表示生成器,d(·)表示判别器,e表示期望,x~pdata表示从主类数据中选择数据x,z~pz(z)表示输入噪声变量选择输入噪声z。具体来说,客户端用全局生成器和全局判别器初始化本地生成器和判别器模型,然后利用主类别数据执行随机梯度下降算法更新参数,更新公式如下:
18、
19、
20、其中,和分别表示第t轮训练本地生成器的参数和本地判别器参数,ηg和ηd分别表示本地生成器的学习率和本地判别器的学习率,和分别表示本地生成器和本地判别器的梯度更新,z表示生成器输入噪声,x表示主类数据,m表示生成器和判别器输入数据的数量,i1表示大小为m的输入数据中第i1条数据。
21、基于此,经过若干轮训练后,本地模型学习到了本地数据的知识,本地生成器在本地判别器的帮助下学习到了主类别的数据分布。
22、进一步地,步骤s4包括如下步骤:
23、s41,服务端对本地模型的参数加权平均聚合,得到新的全局模型参数,计算公式如下:
24、
25、其中ωt+1表示新一轮的全局模型参数,k表示参与训练客户端的数量,pk表示本地模型参数的聚合权重,可以采用所有客户端权重相同的均匀聚合策略,也可以采用客户端k数据量占比大小作为权重,即
26、
27、其中,|dk|表示客户端k的本地数据集大小,|d|为所有客户端本地数据集之和。
28、服务端在接受到k个本地模型的同时也接收到了k组本地生成器和本地判别器,这些生成器和判别器分别学习了不同主类的数据分布。但是相同主类的不同客户端上的数据可能偏向不同。为了使得相同主类的生成器的性能更好、包含更多的多样性特征,对来自相同主类的生成器和判别器进行聚合。
29、s42,服务端将客户端中相同主类别的生成器和判别器执行分组聚合策略,服务端将相同主类的本地生成器和本地判别器放到同一个集合中,每一组中都含有若干来自不同客户端但是学习了相同类分布的本地生成器和本地判别器。在分组完成之后,服务端对每一组的本地生成器和本地判别器也采用公式(7)进行聚合,得到新的全局生成器和全局判别器。若是当前训练轮中,某一组没有对应的生成器和判别器,这说明当前训练轮没有选择到相应主类的客户端,因此这一轮的全局生成器和全局判别器选择继承上一轮。
30、进一步地,步骤s5包含如下步骤:
31、s51,对于这n个类的全局生成器,给定输入高斯分布噪声z,由于每个主类的全局生成器都已经学习到了目标主类的数据分布,因此高斯分布的随机噪声经过正向传播生成器将变换成符合目标分布的数据。服务端将所有生成器的输出数据组合,因而形成了一个包含全部类的独立同分布的均匀数据集。
32、s52,服务端将全局模型在这组独立同分布的数据集下,通过梯度下降法进行微调,扩展全局模型的知识并纠正全局模型偏离的优化方向,更新公式如公式(2)所示。
33、本发明有益效果:本发明采取了利用客户端上的主类数据训练生成对抗网络,并在服务端上进行聚合得到全局生成器和全局判别器,然后利用全局生成器生成一组独立同分布的数据集对全局模型进行微调,达到了纠正全局模型偏移的目标方向,防止知识遗忘现象的发生,从而提升了全局模型的性能的效果,解决了在数据异构场景下联邦学习全局模型精度低的问题。
- 还没有人留言评论。精彩留言会获得点赞!